 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Global AUC into Cluster-Level Contributions for Localized Model Diagnostics
Aug 10, 2025The Area Under the ROC Curve (AUC) is a widely used performance metric for binary classifiers. However, as a global ranking statistic, the AUC aggregates model behavior over the entire dataset, masking localized weaknesses in specific subpopulations. In high-stakes applications such as credit approval and fraud detection, these weaknesses can lead to financial risk or operational failures. In this paper, we introduce a formal decomposition of global AUC into intra- and inter-cluster components. This allows practitioners to evaluate classifier performance within and across clusters of data, enabling granular diagnostics and subgroup analysis. We also compare the AUC with additive performance metrics such as the Brier score and log loss, which support decomposability and direct attribution. Our framework enhances model development and validation practice by providing additional insights to detect model weakness for model risk management.
A Comparison of Modeling Preprocessing Techniques
Feb 24, 2023
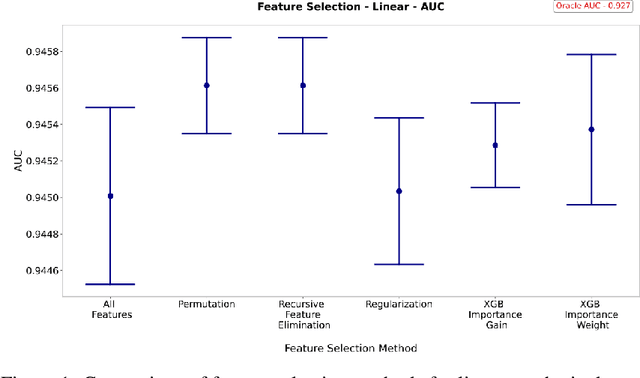

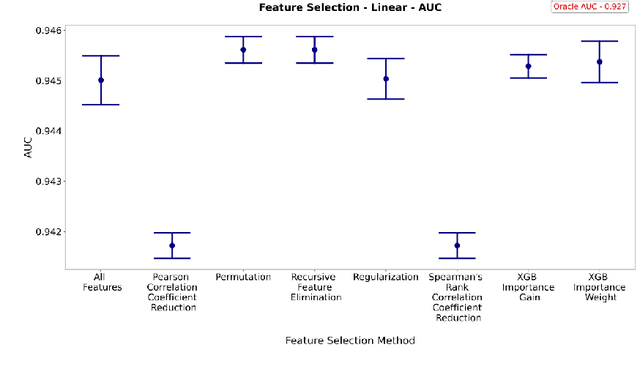
This paper compares the performance of various data processing methods in terms of predictive performance for structured data. This paper also seeks to identify and recommend preprocessing methodologies for tree-based binary classification models, with a focus on eXtreme Gradient Boosting (XGBoost) models. Three data sets of various structures, interactions, and complexity were constructed, which were supplemented by a real-world data set from the Lending Club. We compare several methods for feature selection, categorical handling, and null imputation. Performance is assessed using relative comparisons among the chosen methodologies, including model prediction variability. This paper is presented by the three groups of preprocessing methodologies, with each section consisting of generalized observations. Each observation is accompanied by a recommendation of one or more preferred methodologies. Among feature selection methods, permutation-based feature importance, regularization, and XGBoost's feature importance by weight are not recommended. The correlation coefficient reduction also shows inferior performance. Instead, XGBoost importance by gain shows the most consistency and highest caliber of performance. Categorical featuring encoding methods show greater discrimination in performance among data set structures. While there was no universal "best" method, frequency encoding showed the greatest performance for the most complex data sets (Lending Club), but had the poorest performance for all synthetic (i.e., simpler) data sets. Finally, missing indicator imputation dominated in terms of performance among imputation methods, whereas tree imputation showed extremely poor and highly variable model performance.
Performance and Interpretability Comparisons of Supervised Machine Learning Algorithms: An Empirical Study
May 05, 2022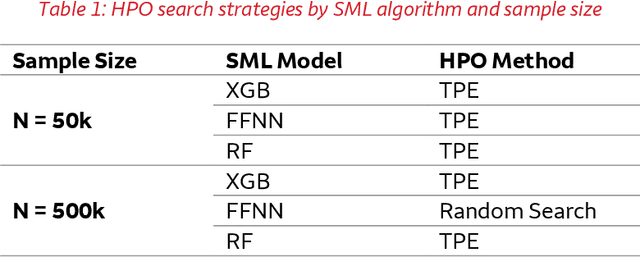
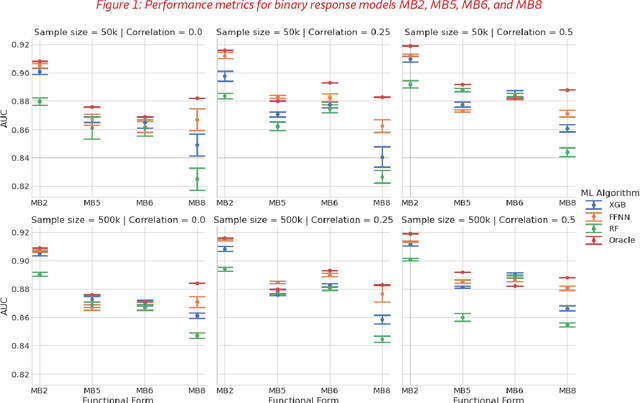
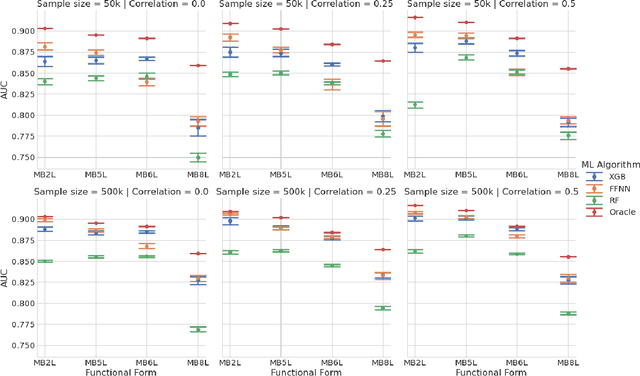
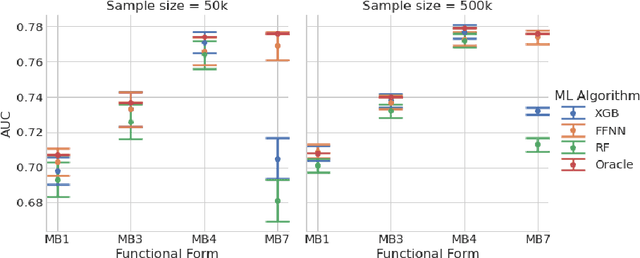
This paper compares the performances of three supervised machine learning algorithms in terms of predictive ability and model interpretation on structured or tabular data. The algorithms considered were scikit-learn implementations of extreme gradient boosting machines (XGB) and random forests (RFs), and feedforward neural networks (FFNNs) from TensorFlow. The paper is organized in a findings-based manner, with each section providing general conclusions supported by empirical results from simulation studies that cover a wide range of model complexity and correlation structures among predictors. We considered both continuous and binary responses of different sample sizes. Overall, XGB and FFNNs were competitive, with FFNNs showing better performance in smooth models and tree-based boosting algorithms performing better in non-smooth models. This conclusion held generally for predictive performance, identification of important variables, and determining correct input-output relationships as measured by partial dependence plots (PDPs). FFNNs generally had less over-fitting, as measured by the difference in performance between training and testing datasets. However, the difference with XGB was often small. RFs did not perform well in general, confirming the findings in the literature. All models exhibited different degrees of bias seen in PDPs, but the bias was especially problematic for RFs. The extent of the biases varied with correlation among predictors, response type, and data set sample size. In general, tree-based models tended to over-regularize the fitted model in the tails of predictor distributions. Finally, as to be expected, performances were better for continuous responses compared to binary data and with larger samples.