 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonally weighted $\ell_{2,1}$ regularization for rank-aware joint sparse recovery: algorithm and analysis
Nov 21, 2023



We propose and analyze an efficient algorithm for solving the joint sparse recovery problem using a new regularization-based method, named orthogonally weighted $\ell_{2,1}$ ($\mathit{ow}\ell_{2,1}$), which is specifically designed to take into account the rank of the solution matrix. This method has applications in feature extraction, matrix column selection, and dictionary learning, and it is distinct from commonly used $\ell_{2,1}$ regularization and other existing regularization-based approaches because it can exploit the full rank of the row-sparse solution matrix, a key feature in many applications. We provide a proof of the method's rank-awareness, establish the existence of solutions to the proposed optimization problem, and develop an efficient algorithm for solving it, whose convergence is analyzed. We also present numerical experiments to illustrate the theory and demonstrate the effectiveness of our method on real-life problems.
Nonconvex penalization for sparse neural networks
Apr 24, 2020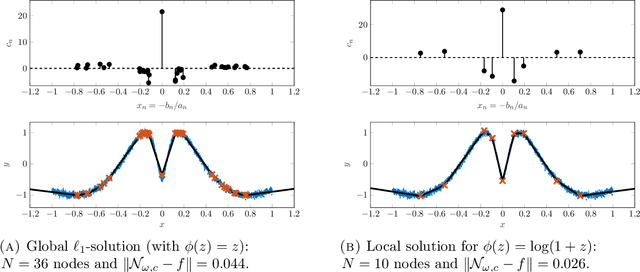

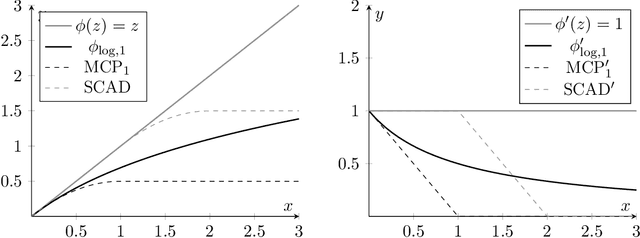

Training methods for artificial neural networks often rely on over-parameterization and random initialization in order to avoid spurious local minima of the loss function that fail to fit the data properly. To sidestep this, one can employ convex neural networks, which combine a convex interpretation of the loss term, sparsity promoting penalization of the outer weights, and greedy neuron insertion. However, the canonical $\ell_1$ penalty does not achieve a sufficient reduction in the number of nodes in a shallow network in the presence of large amounts of data, as observed in practice and supported by our theory. As a remedy, we propose a nonconvex penalization method for the outer weights that maintains the advantages of the convex approach. We investigate the analytic aspects of the method in the context of neural network integral representations and prove attainability of minimizers, together with a finite support property and approximation guarantees. Additionally, we describe how to numerically solve the minimization problem with an adaptive algorithm combining local gradient based training, and adaptive node insertion and extraction.
Neural network integral representations with the ReLU activation function
Oct 07, 2019We derive a formula for neural network integral representations on the sphere with the ReLU activation function under the finite $L_1$ norm (with respect to Lebesgue measure on the sphere) assumption on the outer weights. In one dimensional case, we further solve via a closed-form formula all possible such representations. Additionally, in this case our formula allows one to explicitly solve the least $L_1$ norm neural network representation for a given function.
Greedy Shallow Networks: A New Approach for Constructing and Training Neural Networks
May 24, 2019
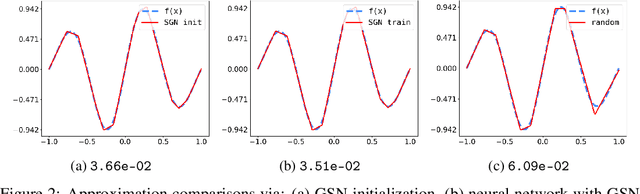
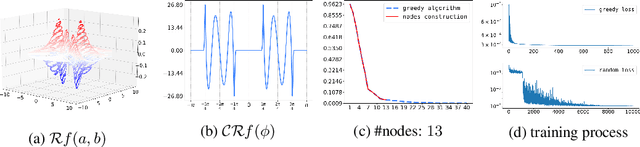

We present a novel greedy approach to obtain a single layer neural network approximation to a target function with the use of a ReLU activation function. In our approach we construct a shallow network by utilizing a greedy algorithm where the set of possible inner weights acts as a parametrization of the prescribed dictionary. To facilitate the greedy selection we employ an integral representation of the network, based on the ridgelet transform, that significantly reduces the cardinality of the dictionary and hence promotes feasibility of the proposed method. Our approach allows for the construction of efficient architectures which can be treated either as improved initializations to be used in place of random-based alternatives, or as fully-trained networks, thus potentially nullifying the need for training and/or calibrating based on backpropagation. Numerical experiments demonstrate the tenability of the proposed concept and its advantages compared to the classical techniques for training and constructing neural networks.