 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Shallow Networks: A New Approach for Constructing and Training Neural Networks
Paper and Code

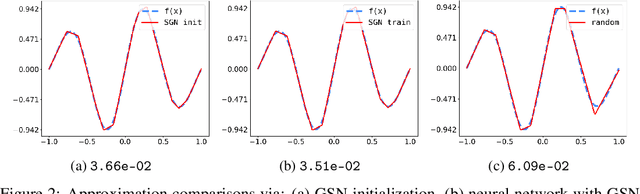
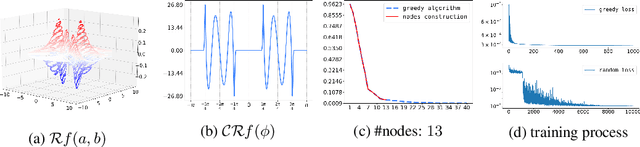

We present a novel greedy approach to obtain a single layer neural network approximation to a target function with the use of a ReLU activation function. In our approach we construct a shallow network by utilizing a greedy algorithm where the set of possible inner weights acts as a parametrization of the prescribed dictionary. To facilitate the greedy selection we employ an integral representation of the network, based on the ridgelet transform, that significantly reduces the cardinality of the dictionary and hence promotes feasibility of the proposed method. Our approach allows for the construction of efficient architectures which can be treated either as improved initializations to be used in place of random-based alternatives, or as fully-trained networks, thus potentially nullifying the need for training and/or calibrating based on backpropagation. Numerical experiments demonstrate the tenability of the proposed concept and its advantages compared to the classical techniques for training and constructing neural networks.