 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonconvex penalization for sparse neural networks
Paper and Code
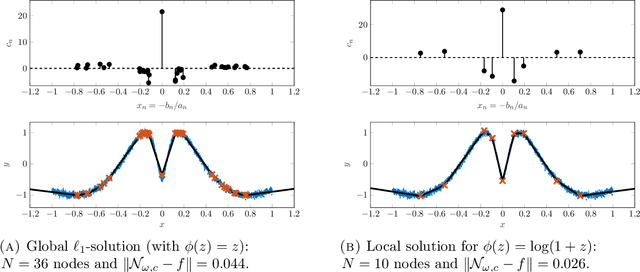

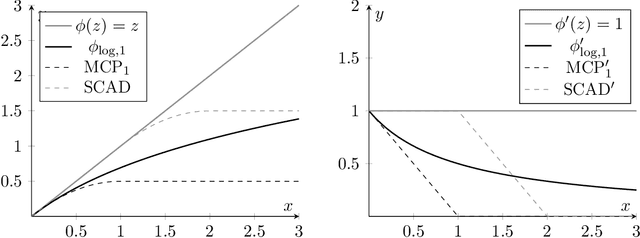

Training methods for artificial neural networks often rely on over-parameterization and random initialization in order to avoid spurious local minima of the loss function that fail to fit the data properly. To sidestep this, one can employ convex neural networks, which combine a convex interpretation of the loss term, sparsity promoting penalization of the outer weights, and greedy neuron insertion. However, the canonical $\ell_1$ penalty does not achieve a sufficient reduction in the number of nodes in a shallow network in the presence of large amounts of data, as observed in practice and supported by our theory. As a remedy, we propose a nonconvex penalization method for the outer weights that maintains the advantages of the convex approach. We investigate the analytic aspects of the method in the context of neural network integral representations and prove attainability of minimizers, together with a finite support property and approximation guarantees. Additionally, we describe how to numerically solve the minimization problem with an adaptive algorithm combining local gradient based training, and adaptive node insertion and extraction.