 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention cannot be an Explanation
Jan 26, 2022Attention based explanations (viz. saliency maps), by providing interpretability to black box models such as deep neural networks, are assumed to improve human trust and reliance in the underlying models. Recently, it has been shown that attention weights are frequently uncorrelated with gradient-based measures of feature importance. Motivated by this, we ask a follow-up question: "Assuming that we only consider the tasks where attention weights correlate well with feature importance, how effective are these attention based explanations in increasing human trust and reliance in the underlying models?". In other words, can we use attention as an explanation? We perform extensive human study experiments that aim to qualitatively and quantitatively assess the degree to which attention based explanations are suitable in increasing human trust and reliance. Our experiment results show that attention cannot be used as an explanation.
Discourse Analysis for Evaluating Coherence in Video Paragraph Captions
Jan 17, 2022

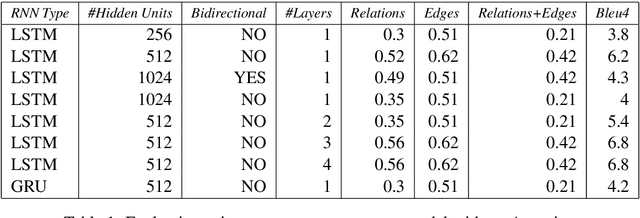
Video paragraph captioning is the task of automatically generating a coherent paragraph description of the actions in a video. Previous linguistic studies have demonstrated that coherence of a natural language text is reflected by its discourse structure and relations. However, existing video captioning methods evaluate the coherence of generated paragraphs by comparing them merely against human paragraph annotations and fail to reason about the underlying discourse structure. At UCLA, we are currently exploring a novel discourse based framework to evaluate the coherence of video paragraphs. Central to our approach is the discourse representation of videos, which helps in modeling coherence of paragraphs conditioned on coherence of videos. We also introduce DisNet, a novel dataset containing the proposed visual discourse annotations of 3000 videos and their paragraphs. Our experiment results have shown that the proposed framework evaluates coherence of video paragraphs significantly better than all the baseline methods. We believe that many other multi-discipline Artificial Intelligence problems such as Visual Dialog and Visual Storytelling would also greatly benefit from the proposed visual discourse framework and the DisNet dataset.
Words aren't enough, their order matters: On the Robustness of Grounding Visual Referring Expressions
May 04, 2020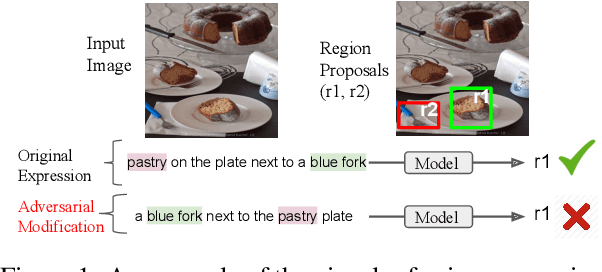

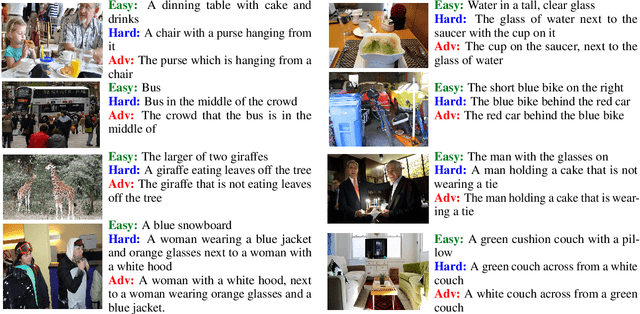
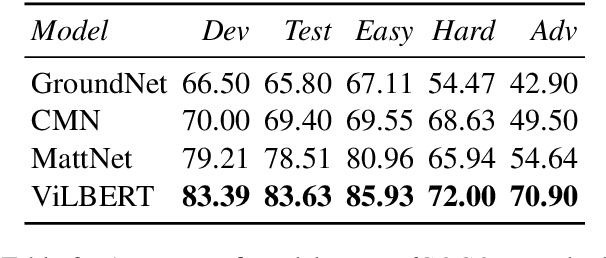
Visual referring expression recognition is a challenging task that requires natural language understanding in the context of an image. We critically examine RefCOCOg, a standard benchmark for this task, using a human study and show that 83.7% of test instances do not require reasoning on linguistic structure, i.e., words are enough to identify the target object, the word order doesn't matter. To measure the true progress of existing models, we split the test set into two sets, one which requires reasoning on linguistic structure and the other which doesn't. Additionally, we create an out-of-distribution dataset Ref-Adv by asking crowdworkers to perturb in-domain examples such that the target object changes. Using these datasets, we empirically show that existing methods fail to exploit linguistic structure and are 12% to 23% lower in performance than the established progress for this task. We also propose two methods, one based on contrastive learning and the other based on multi-task learning, to increase the robustness of ViLBERT, the current state-of-the-art model for this task. Our datasets are publicly available at https://github.com/aws/aws-refcocog-adv
Visual Discourse Parsing
Mar 13, 2019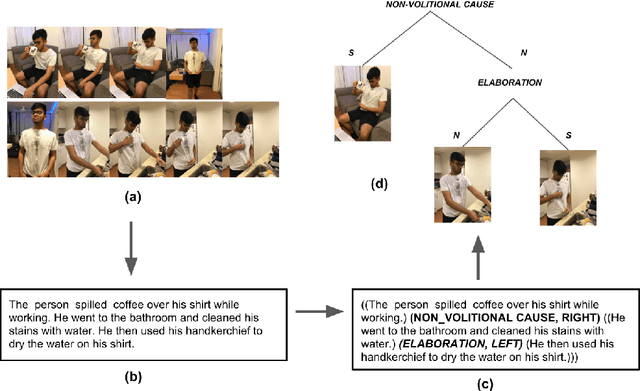

Text-level discourse parsing aims to unmask how two segments (or sentences) in the text are related to each other. We propose the task of Visual Discourse Parsing, which requires understanding discourse relations among scenes in a video. Here we use the term scene to refer to a subset of video frames that can better summarize the video. In order to collect a dataset for learning discourse cues from videos, one needs to manually identify the scenes from a large pool of video frames and then annotate the discourse relations between them. This is clearly a time consuming, expensive and tedious task. In this work, we propose an approach to identify discourse cues from the videos without the need to explicitly identify and annotate the scenes. We also present a novel dataset containing 310 videos and the corresponding discourse cues to evaluate our approach. We believe that many of the multi-discipline Artificial Intelligence problems such as Visual Dialog and Visual Storytelling would greatly benefit from the use of visual discourse cues.
Natural Language Interaction with Explainable AI Models
Mar 13, 2019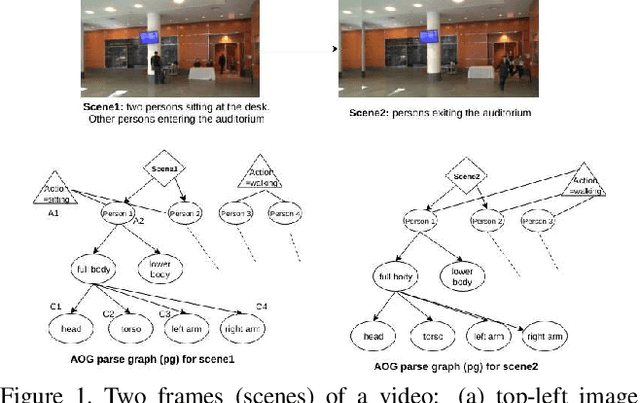
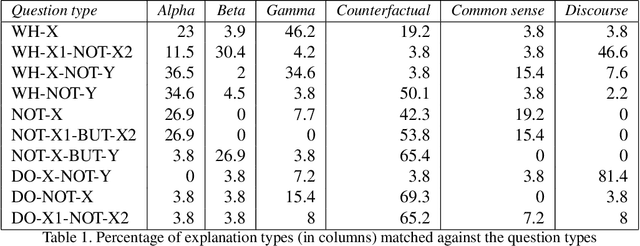

This paper presents an explainable AI (XAI) system that provides explanations for its predictions. The system consists of two key components -- namely, the prediction And-Or graph (AOG) model for recognizing and localizing concepts of interest in input data, and the XAI model for providing explanations to the user about the AOG's predictions. In this work, we focus on the XAI model specified to interact with the user in natural language, whereas the AOG's predictions are considered given and represented by the corresponding parse graphs (pg's) of the AOG. Our XAI model takes pg's as input and provides answers to the user's questions using the following types of reasoning: direct evidence (e.g., detection scores), part-based inference (e.g., detected parts provide evidence for the concept asked), and other evidences from spatio-temporal context (e.g., constraints from the spatio-temporal surround). We identify several correlations between user's questions and the XAI answers using Youtube Action dataset.