 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Discourse Parsing
Paper and Code
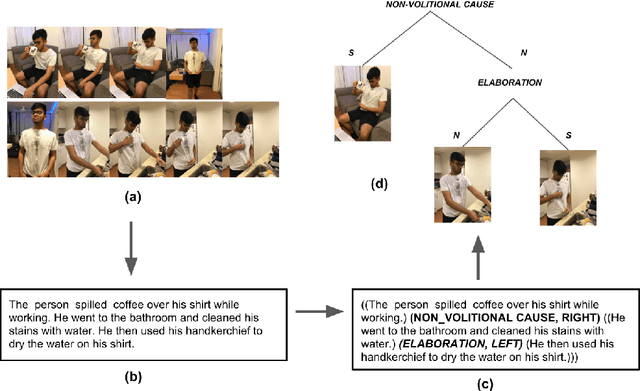
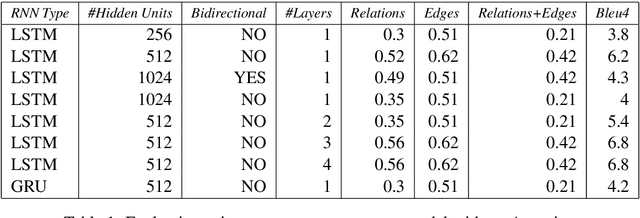

Text-level discourse parsing aims to unmask how two segments (or sentences) in the text are related to each other. We propose the task of Visual Discourse Parsing, which requires understanding discourse relations among scenes in a video. Here we use the term scene to refer to a subset of video frames that can better summarize the video. In order to collect a dataset for learning discourse cues from videos, one needs to manually identify the scenes from a large pool of video frames and then annotate the discourse relations between them. This is clearly a time consuming, expensive and tedious task. In this work, we propose an approach to identify discourse cues from the videos without the need to explicitly identify and annotate the scenes. We also present a novel dataset containing 310 videos and the corresponding discourse cues to evaluate our approach. We believe that many of the multi-discipline Artificial Intelligence problems such as Visual Dialog and Visual Storytelling would greatly benefit from the use of visual discourse cues.