 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpness-Aware Minimization for Efficiently Improving Generalization
Oct 03, 2020

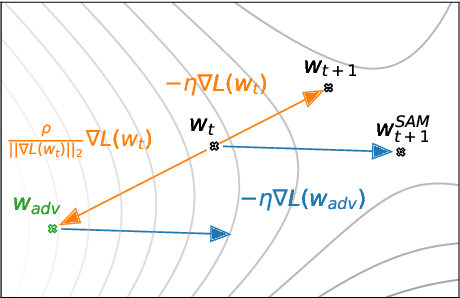

In today's heavily overparameterized models, the value of the training loss provides few guarantees on model generalization ability. Indeed, optimizing only the training loss value, as is commonly done, can easily lead to suboptimal model quality. Motivated by the connection between geometry of the loss landscape and generalization---including a generalization bound that we prove here---we introduce a novel, effective procedure for instead simultaneously minimizing loss value and loss sharpness. In particular, our procedure, Sharpness-Aware Minimization (SAM), seeks parameters that lie in neighborhoods having uniformly low loss; this formulation results in a min-max optimization problem on which gradient descent can be performed efficiently. We present empirical results showing that SAM improves model generalization across a variety of benchmark datasets (e.g., CIFAR-{10, 100}, ImageNet, finetuning tasks) and models, yielding novel state-of-the-art performance for several. Additionally, we find that SAM natively provides robustness to label noise on par with that provided by state-of-the-art procedures that specifically target learning with noisy labels.
A Scalable Bootstrap for Massive Data
Jun 28, 2012

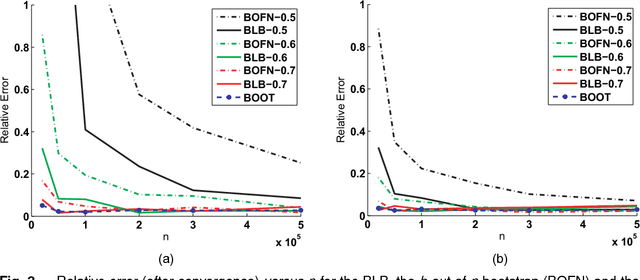

The bootstrap provides a simple and powerful means of assessing the quality of estimators. However, in settings involving large datasets---which are increasingly prevalent---the computation of bootstrap-based quantities can be prohibitively demanding computationally. While variants such as subsampling and the $m$ out of $n$ bootstrap can be used in principle to reduce the cost of bootstrap computations, we find that these methods are generally not robust to specification of hyperparameters (such as the number of subsampled data points), and they often require use of more prior information (such as rates of convergence of estimators) than the bootstrap. As an alternative, we introduce the Bag of Little Bootstraps (BLB), a new procedure which incorporates features of both the bootstrap and subsampling to yield a robust, computationally efficient means of assessing the quality of estimators. BLB is well suited to modern parallel and distributed computing architectures and furthermore retains the generic applicability and statistical efficiency of the bootstrap. We demonstrate BLB's favorable statistical performance via a theoretical analysis elucidating the procedure's properties, as well as a simulation study comparing BLB to the bootstrap, the $m$ out of $n$ bootstrap, and subsampling. In addition, we present results from a large-scale distributed implementation of BLB demonstrating its computational superiority on massive data, a method for adaptively selecting BLB's hyperparameters, an empirical study applying BLB to several real datasets, and an extension of BLB to time series data.
The Big Data Bootstrap
Jun 27, 2012The bootstrap provides a simple and powerful means of assessing the quality of estimators. However, in settings involving large datasets, the computation of bootstrap-based quantities can be prohibitively demanding. As an alternative, we present the Bag of Little Bootstraps (BLB), a new procedure which incorporates features of both the bootstrap and subsampling to obtain a robust, computationally efficient means of assessing estimator quality. BLB is well suited to modern parallel and distributed computing architectures and retains the generic applicability, statistical efficiency, and favorable theoretical properties of the bootstrap. We provide the results of an extensive empirical and theoretical investigation of BLB's behavior, including a study of its statistical correctness, its large-scale implementation and performance, selection of hyperparameters, and performance on real data.