 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupMixer: Patch-based Group Convolutional Neural Network for Breast Cancer Detection from Histopathological Images
Nov 16, 2023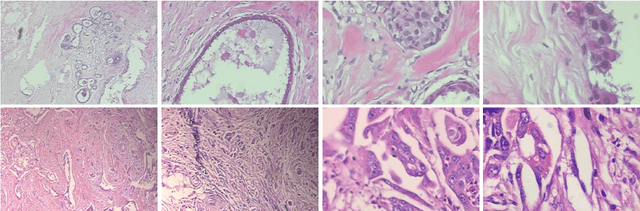

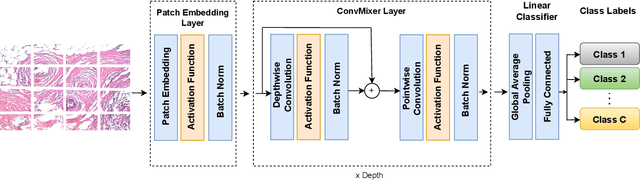
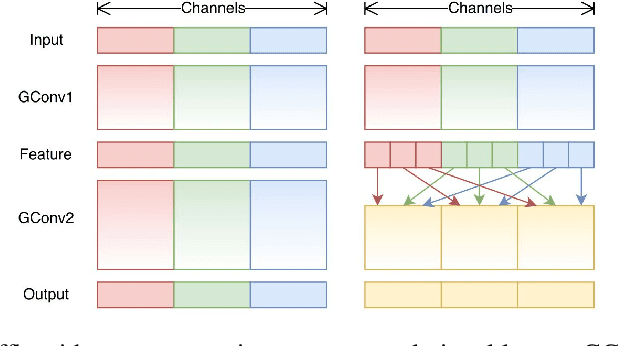
Diagnosis of breast cancer malignancy at the early stages is a crucial step for controlling its side effects. Histopathological analysis provides a unique opportunity for malignant breast cancer detection. However, such a task would be tedious and time-consuming for the histopathologists. Deep Neural Networks enable us to learn informative features directly from raw histopathological images without manual feature extraction. Although Convolutional Neural Networks (CNNs) have been the dominant architectures in the computer vision realm, Transformer-based architectures have shown promising results in different computer vision tasks. Although harnessing the capability of Transformer-based architectures for medical image analysis seems interesting, these architectures are large, have a significant number of trainable parameters, and require large datasets to be trained on, which are usually rare in the medical domain. It has been claimed and empirically proved that at least part of the superior performance of Transformer-based architectures in Computer Vision domain originates from patch embedding operation. In this paper, we borrowed the previously introduced idea of integrating a fully Convolutional Neural Network architecture with Patch Embedding operation and presented an efficient CNN architecture for breast cancer malignancy detection from histopathological images. Despite the number of parameters that is significantly smaller than other methods, the accuracy performance metrics achieved 97.65%, 98.92%, 99.21%, and 98.01% for 40x, 100x, 200x, and 400x magnifications respectively. We took a step forward and modified the architecture using Group Convolution and Channel Shuffling ideas and reduced the number of trainable parameters even more with a negligible decline in performance and achieved 95.42%, 98.16%, 96.05%, and 97.92% accuracy for the mentioned magnifications respectively.
Contrastive Multi-Modal Representation Learning for Spark Plug Fault Diagnosis
Nov 04, 2023



Due to the incapability of one sensory measurement to provide enough information for condition monitoring of some complex engineered industrial mechanisms and also for overcoming the misleading noise of a single sensor, multiple sensors are installed to improve the condition monitoring of some industrial equipment. Therefore, an efficient data fusion strategy is demanded. In this research, we presented a Denoising Multi-Modal Autoencoder with a unique training strategy based on contrastive learning paradigm, both being utilized for the first time in the machine health monitoring realm. The presented approach, which leverages the merits of both supervised and unsupervised learning, not only achieves excellent performance in fusing multiple modalities (or views) of data into an enriched common representation but also takes data fusion to the next level wherein one of the views can be omitted during inference time with very slight performance reduction, or even without any reduction at all. The presented methodology enables multi-modal fault diagnosis systems to perform more robustly in case of sensor failure occurrence, and one can also intentionally omit one of the sensors (the more expensive one) in order to build a more cost-effective condition monitoring system without sacrificing performance for practical purposes. The effectiveness of the presented methodology is examined on a real-world private multi-modal dataset gathered under non-laboratory conditions from a complex engineered mechanism, an inline four-stroke spark-ignition engine, aiming for spark plug fault diagnosis. This dataset, which contains the accelerometer and acoustic signals as two modalities, has a very slight amount of fault, and achieving good performance on such a dataset promises that the presented method can perform well on other equipment as well.