 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupMixer: Patch-based Group Convolutional Neural Network for Breast Cancer Detection from Histopathological Images
Nov 16, 2023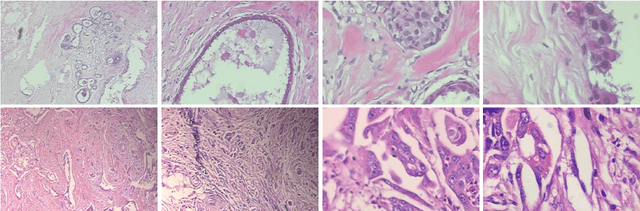

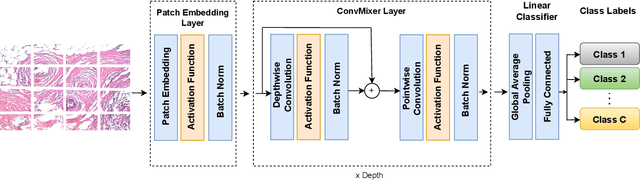
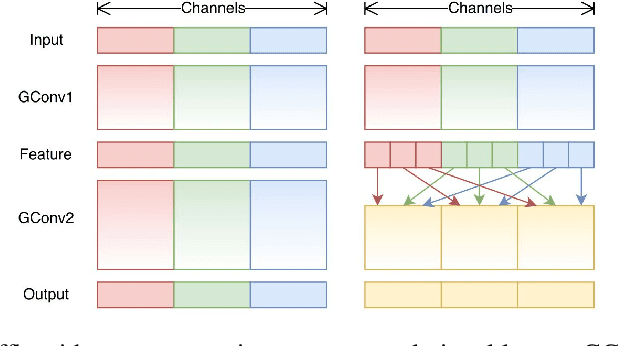
Diagnosis of breast cancer malignancy at the early stages is a crucial step for controlling its side effects. Histopathological analysis provides a unique opportunity for malignant breast cancer detection. However, such a task would be tedious and time-consuming for the histopathologists. Deep Neural Networks enable us to learn informative features directly from raw histopathological images without manual feature extraction. Although Convolutional Neural Networks (CNNs) have been the dominant architectures in the computer vision realm, Transformer-based architectures have shown promising results in different computer vision tasks. Although harnessing the capability of Transformer-based architectures for medical image analysis seems interesting, these architectures are large, have a significant number of trainable parameters, and require large datasets to be trained on, which are usually rare in the medical domain. It has been claimed and empirically proved that at least part of the superior performance of Transformer-based architectures in Computer Vision domain originates from patch embedding operation. In this paper, we borrowed the previously introduced idea of integrating a fully Convolutional Neural Network architecture with Patch Embedding operation and presented an efficient CNN architecture for breast cancer malignancy detection from histopathological images. Despite the number of parameters that is significantly smaller than other methods, the accuracy performance metrics achieved 97.65%, 98.92%, 99.21%, and 98.01% for 40x, 100x, 200x, and 400x magnifications respectively. We took a step forward and modified the architecture using Group Convolution and Channel Shuffling ideas and reduced the number of trainable parameters even more with a negligible decline in performance and achieved 95.42%, 98.16%, 96.05%, and 97.92% accuracy for the mentioned magnifications respectively.
Survival Prediction from Imbalance colorectal cancer dataset using hybrid sampling methods and tree-based classifiers
Sep 04, 2023



Background and Objective: Colorectal cancer is a high mortality cancer. Clinical data analysis plays a crucial role in predicting the survival of colorectal cancer patients, enabling clinicians to make informed treatment decisions. However, utilizing clinical data can be challenging, especially when dealing with imbalanced outcomes. This paper focuses on developing algorithms to predict 1-, 3-, and 5-year survival of colorectal cancer patients using clinical datasets, with particular emphasis on the highly imbalanced 1-year survival prediction task. To address this issue, we propose a method that creates a pipeline of some of standard balancing techniques to increase the true positive rate. Evaluation is conducted on a colorectal cancer dataset from the SEER database. Methods: The pre-processing step consists of removing records with missing values and merging categories. The minority class of 1-year and 3-year survival tasks consists of 10% and 20% of the data, respectively. Edited Nearest Neighbor, Repeated edited nearest neighbor (RENN), Synthetic Minority Over-sampling Techniques (SMOTE), and pipelines of SMOTE and RENN approaches were used and compared for balancing the data with tree-based classifiers. Decision Trees, Random Forest, Extra Tree, eXtreme Gradient Boosting, and Light Gradient Boosting (LGBM) are used in this article. Method. Results: The performance evaluation utilizes a 5-fold cross-validation approach. In the case of highly imbalanced datasets (1-year), our proposed method with LGBM outperforms other sampling methods with the sensitivity of 72.30%. For the task of imbalance (3-year survival), the combination of RENN and LGBM achieves a sensitivity of 80.81%, indicating that our proposed method works best for highly imbalanced datasets. Conclusions: Our proposed method significantly improves mortality prediction for the minority class of colorectal cancer patients.