 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEGFN: Efficient Geometry Feature Network for Fast Stereo 3D Object Detection
Nov 28, 2021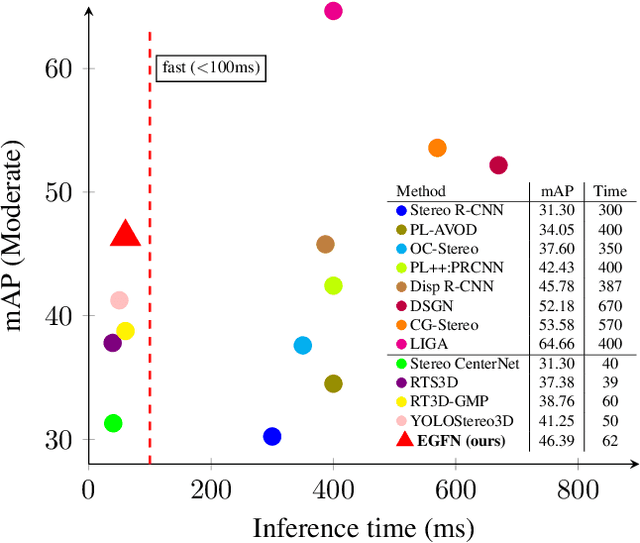
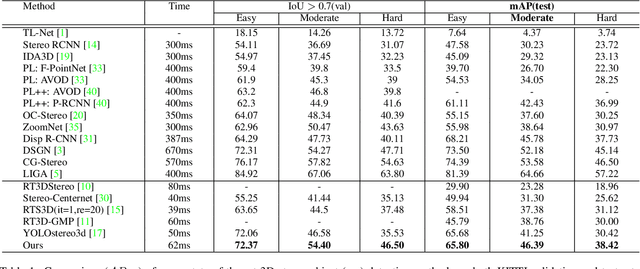
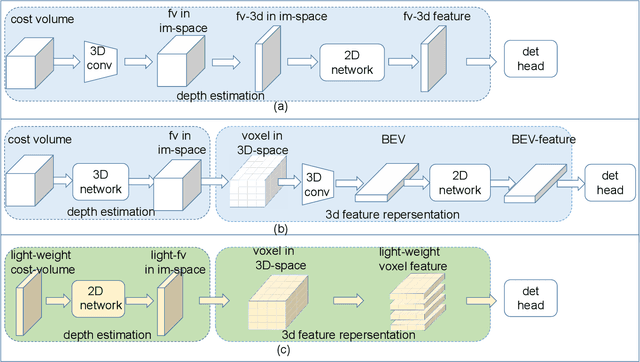
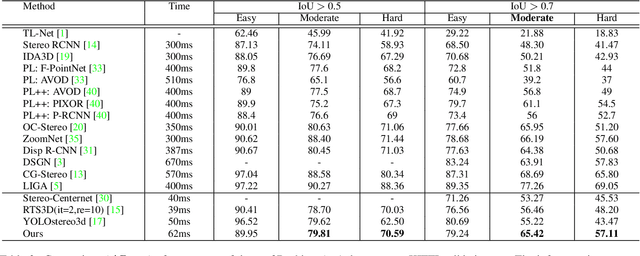
Fast stereo based 3D object detectors have made great progress in the sense of inference time recently. However, they lag far behind high-precision oriented methods in accuracy. We argue that the main reason is the missing or poor 3D geometry feature representation in fast stereo based methods. To solve this problem, we propose an efficient geometry feature generation network (EGFN). The key of our EGFN is an efficient and effective 3D geometry feature representation (EGFR) module. In the EGFR module, light-weight cost volume features are firstly generated, then are efficiently converted into 3D space, and finally multi-scale features enhancement in in both image and 3D spaces is conducted to obtain the 3D geometry features: enhanced light-weight voxel features. In addition, we introduce a novel multi-scale knowledge distillation strategy to guide multi-scale 3D geometry features learning. Experimental results on the public KITTI test set shows that the proposed EGFN outperforms YOLOStsereo3D, the advanced fast method, by 5.16\% on mAP$_{3d}$ at the cost of merely additional 12 ms and hence achieves a better trade-off between accuracy and efficiency for stereo 3D object detection. Our code will be publicly available.
Shape Prior Non-Uniform Sampling Guided Real-time Stereo 3D Object Detection
Jun 22, 2021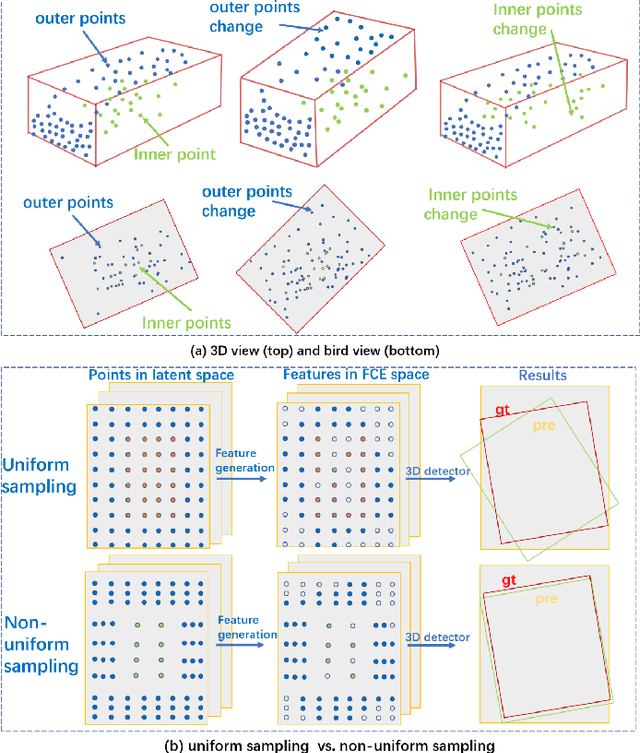
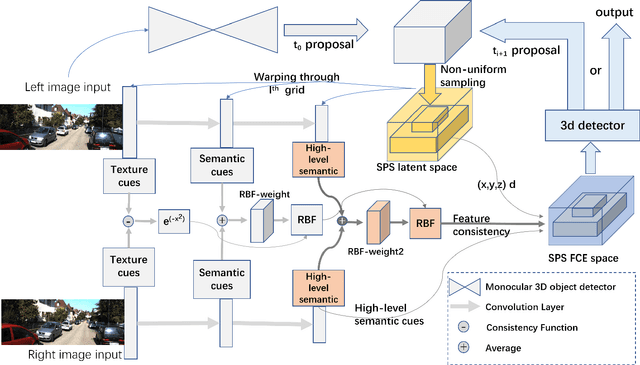
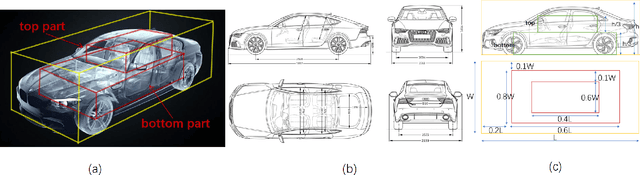
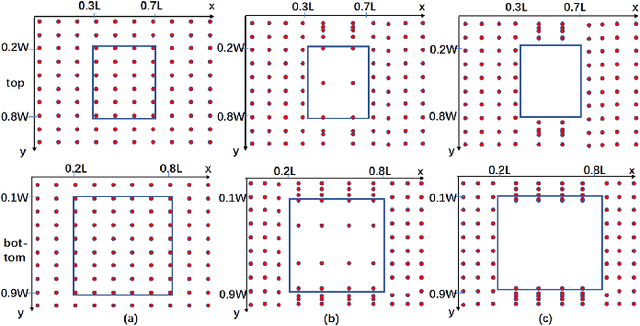
Pseudo-LiDAR based 3D object detectors have gained popularity due to their high accuracy. However, these methods need dense depth supervision and suffer from inferior speed. To solve these two issues, a recently introduced RTS3D builds an efficient 4D Feature-Consistency Embedding (FCE) space for the intermediate representation of object without depth supervision. FCE space splits the entire object region into 3D uniform grid latent space for feature sampling point generation, which ignores the importance of different object regions. However, we argue that, compared with the inner region, the outer region plays a more important role for accurate 3D detection. To encode more information from the outer region, we propose a shape prior non-uniform sampling strategy that performs dense sampling in outer region and sparse sampling in inner region. As a result, more points are sampled from the outer region and more useful features are extracted for 3D detection. Further, to enhance the feature discrimination of each sampling point, we propose a high-level semantic enhanced FCE module to exploit more contextual information and suppress noise better. Experiments on the KITTI dataset are performed to show the effectiveness of the proposed method. Compared with the baseline RTS3D, our proposed method has 2.57% improvement on AP3d almost without extra network parameters. Moreover, our proposed method outperforms the state-of-the-art methods without extra supervision at a real-time speed.