 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampleFix: Learning to Correct Programs by Sampling Diverse Fixes
Jun 24, 2019

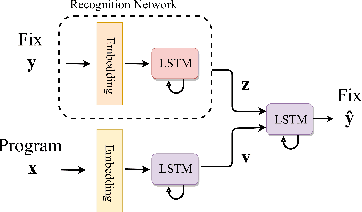

Automatic program correction is an active topic of research, which holds the potential of dramatically improving productivity of programmers during the software development process and correctness of software in general. Recent advances in machine learning, deep learning and NLP have rekindled the hope to eventually fully automate the process of repairing programs. A key challenges is ambiguity, as multiple codes -- or fixes -- can implement the same functionality. In addition, dataset by nature fail to capture the variance introduced by such ambiguities. Therefore, we propose a deep generative model to automatically correct programming errors by learning a distribution of potential fixes. Our model is formulated as a deep conditional variational autoencoder that samples diverse fixes for the given erroneous programs. In order to account for ambiguity and inherent lack of representative datasets, we propose a novel regularizer to encourage the model to generate diverse fixes. Our evaluations on common programming errors show for the first time the generation of diverse fixes and strong improvements over the state-of-the-art approaches by fixing up to $61\%$ of the mistakes.
Updates-Leak: Data Set Inference and Reconstruction Attacks in Online Learning
Apr 01, 2019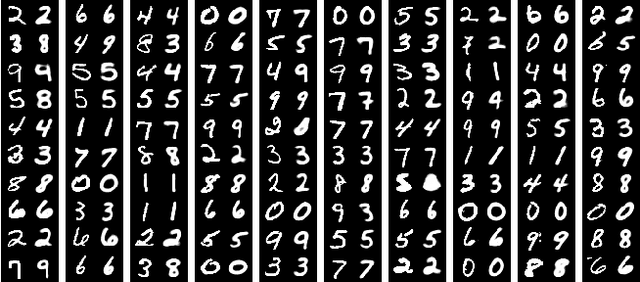
Machine learning (ML) has progressed rapidly during the past decade and the major factor that drives such development is the unprecedented large-scale data. As data generation is a continuous process, this leads to ML service providers updating their models frequently with newly-collected data in an online learning scenario. In consequence, if an ML model is queried with the same set of data samples at two different points in time, it will provide different results. In this paper, we investigate whether the change in the output of a black-box ML model before and after being updated can leak information of the dataset used to perform the update. This constitutes a new attack surface against black-box ML models and such information leakage severely damages the intellectual property and data privacy of the ML model owner/provider. In contrast to membership inference attacks, we use an encoder-decoder formulation that allows inferring diverse information ranging from detailed characteristics to full reconstruction of the dataset. Our new attacks are facilitated by state-of-the-art deep learning techniques. In particular, we propose a hybrid generative model (BM-GAN) that is based on generative adversarial networks (GANs) but includes a reconstructive loss that allows generating accurate samples. Our experiments show effective prediction of dataset characteristics and even full reconstruction in challenging conditions.