 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow When to Fuse: Investigating Non-English Hybrid Retrieval in the Legal Domain
Sep 02, 2024



Hybrid search has emerged as an effective strategy to offset the limitations of different matching paradigms, especially in out-of-domain contexts where notable improvements in retrieval quality have been observed. However, existing research predominantly focuses on a limited set of retrieval methods, evaluated in pairs on domain-general datasets exclusively in English. In this work, we study the efficacy of hybrid search across a variety of prominent retrieval models within the unexplored field of law in the French language, assessing both zero-shot and in-domain scenarios. Our findings reveal that in a zero-shot context, fusing different domain-general models consistently enhances performance compared to using a standalone model, regardless of the fusion method. Surprisingly, when models are trained in-domain, we find that fusion generally diminishes performance relative to using the best single system, unless fusing scores with carefully tuned weights. These novel insights, among others, expand the applicability of prior findings across a new field and language, and contribute to a deeper understanding of hybrid search in non-English specialized domains.
ColBERT-XM: A Modular Multi-Vector Representation Model for Zero-Shot Multilingual Information Retrieval
Feb 23, 2024State-of-the-art neural retrievers predominantly focus on high-resource languages like English, which impedes their adoption in retrieval scenarios involving other languages. Current approaches circumvent the lack of high-quality labeled data in non-English languages by leveraging multilingual pretrained language models capable of cross-lingual transfer. However, these models require substantial task-specific fine-tuning across multiple languages, often perform poorly in languages with minimal representation in the pretraining corpus, and struggle to incorporate new languages after the pretraining phase. In this work, we present a novel modular dense retrieval model that learns from the rich data of a single high-resource language and effectively zero-shot transfers to a wide array of languages, thereby eliminating the need for language-specific labeled data. Our model, ColBERT-XM, demonstrates competitive performance against existing state-of-the-art multilingual retrievers trained on more extensive datasets in various languages. Further analysis reveals that our modular approach is highly data-efficient, effectively adapts to out-of-distribution data, and significantly reduces energy consumption and carbon emissions. By demonstrating its proficiency in zero-shot scenarios, ColBERT-XM marks a shift towards more sustainable and inclusive retrieval systems, enabling effective information accessibility in numerous languages. We publicly release our code and models for the community.
Interpretable Long-Form Legal Question Answering with Retrieval-Augmented Large Language Models
Sep 29, 2023Many individuals are likely to face a legal dispute at some point in their lives, but their lack of understanding of how to navigate these complex issues often renders them vulnerable. The advancement of natural language processing opens new avenues for bridging this legal literacy gap through the development of automated legal aid systems. However, existing legal question answering (LQA) approaches often suffer from a narrow scope, being either confined to specific legal domains or limited to brief, uninformative responses. In this work, we propose an end-to-end methodology designed to generate long-form answers to any statutory law questions, utilizing a "retrieve-then-read" pipeline. To support this approach, we introduce and release the Long-form Legal Question Answering (LLeQA) dataset, comprising 1,868 expert-annotated legal questions in the French language, complete with detailed answers rooted in pertinent legal provisions. Our experimental results demonstrate promising performance on automatic evaluation metrics, but a qualitative analysis uncovers areas for refinement. As one of the only comprehensive, expert-annotated long-form LQA dataset, LLeQA has the potential to not only accelerate research towards resolving a significant real-world issue, but also act as a rigorous benchmark for evaluating NLP models in specialized domains. We publicly release our code, data, and models.
Finding the Law: Enhancing Statutory Article Retrieval via Graph Neural Networks
Jan 30, 2023


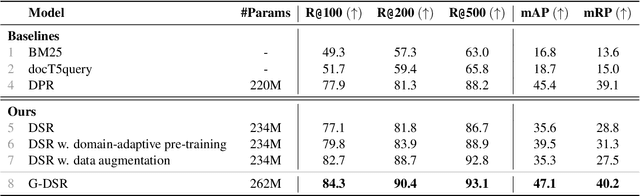
Statutory article retrieval (SAR), the task of retrieving statute law articles relevant to a legal question, is a promising application of legal text processing. In particular, high-quality SAR systems can improve the work efficiency of legal professionals and provide basic legal assistance to citizens in need at no cost. Unlike traditional ad-hoc information retrieval, where each document is considered a complete source of information, SAR deals with texts whose full sense depends on complementary information from the topological organization of statute law. While existing works ignore these domain-specific dependencies, we propose a novel graph-augmented dense statute retriever (G-DSR) model that incorporates the structure of legislation via a graph neural network to improve dense retrieval performance. Experimental results show that our approach outperforms strong retrieval baselines on a real-world expert-annotated SAR dataset.
A Statutory Article Retrieval Dataset in French
Aug 26, 2021



Statutory article retrieval is the task of automatically retrieving law articles relevant to a legal question. While recent advances in natural language processing have sparked considerable interest in many legal tasks, statutory article retrieval remains primarily untouched due to the scarcity of large-scale and high-quality annotated datasets. To address this bottleneck, we introduce the Belgian Statutory Article Retrieval Dataset (BSARD), which consists of 1,100+ French native legal questions labeled by experienced jurists with relevant articles from a corpus of 22,600+ Belgian law articles. Using BSARD, we benchmark several unsupervised information retrieval methods based on term weighting and pooled embeddings. Our best performing baseline achieves 50.8% R@100, which is promising for the feasibility of the task and indicates that there is still substantial room for improvement. By the specificity of the data domain and addressed task, BSARD presents a unique challenge problem for future research on legal information retrieval.