 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Safety Guarantees in Multi-Task Bayesian Optimization
Mar 11, 2025In many practical scenarios of black box optimization, the objective function is subject to constraints that must be satisfied to avoid undesirable outcomes. Such constraints are typically unknown and must be learned during optimization. Safe Bayesian optimization aims to find the global optimum while ensuring that the constraints are satisfied with high probability. However, it is often sample-inefficient due to the small initial feasible set, which requires expansion by evaluating the objective or constraint functions, limiting its applicability to low-dimensional or inexpensive problems. To enhance sample efficiency, additional information from cheap simulations can be leveraged, albeit at the cost of safeness guarantees. This paper introduces a novel safe multi-task Bayesian optimization algorithm that integrates multiple tasks while maintaining high-probability safety. We derive robust uniform error bounds for the multi-task case and demonstrate the effectiveness of the approach on benchmark functions and a control problem. Our results show a significant improvement in sample efficiency, making the proposed method well-suited for expensive-to-evaluate functions.
A Two-Stage Machine Learning-Aided Approach for Quench Identification at the European XFEL
Jul 11, 2024This paper introduces a machine learning-aided fault detection and isolation method applied to the case study of quench identification at the European X-Ray Free-Electron Laser. The plant utilizes 800 superconducting radio-frequency cavities in order to accelerate electron bunches to high energies of up to 17.5 GeV. Various faulty events can disrupt the nominal functioning of the accelerator, including quenches that can lead to a loss of the superconductivity of the cavities and the interruption of their operation. In this context, our solution consists in analyzing signals reflecting the dynamics of the cavities in a two-stage approach. (I) Fault detection that uses analytical redundancy to process the data and generate a residual. The evaluation of the residual through the generalized likelihood ratio allows detecting the faulty behaviors. (II) Fault isolation which involves the distinction of the quenches from the other faults. To this end, we proceed with a data-driven model of the k-medoids algorithm that explores different similarity measures, namely, the Euclidean and the dynamic time warping. Finally, we evaluate the new method and compare it to the currently deployed quench detection system, the results show the improved performance achieved by our method.
Automated Anomaly Detection on European XFEL Klystrons
May 20, 2024High-power multi-beam klystrons represent a key component to amplify RF to generate the accelerating field of the superconducting radio frequency (SRF) cavities at European XFEL. Exchanging these high-power components takes time and effort, thus it is necessary to minimize maintenance and downtime and at the same time maximize the device's operation. In an attempt to explore the behavior of klystrons using machine learning, we completed a series of experiments on our klystrons to determine various operational modes and conduct feature extraction and dimensionality reduction to extract the most valuable information about a normal operation. To analyze recorded data we used state-of-the-art data-driven learning techniques and recognized the most promising components that might help us better understand klystron operational states and identify early on possible faults or anomalies.
Large Language Models for Human-Machine Collaborative Particle Accelerator Tuning through Natural Language
May 14, 2024Autonomous tuning of particle accelerators is an active and challenging field of research with the goal of enabling novel accelerator technologies cutting-edge high-impact applications, such as physics discovery, cancer research and material sciences. A key challenge with autonomous accelerator tuning remains that the most capable algorithms require an expert in optimisation, machine learning or a similar field to implement the algorithm for every new tuning task. In this work, we propose the use of large language models (LLMs) to tune particle accelerators. We demonstrate on a proof-of-principle example the ability of LLMs to successfully and autonomously tune a particle accelerator subsystem based on nothing more than a natural language prompt from the operator, and compare the performance of our LLM-based solution to state-of-the-art optimisation algorithms, such as Bayesian optimisation (BO) and reinforcement learning-trained optimisation (RLO). In doing so, we also show how LLMs can perform numerical optimisation of a highly non-linear real-world objective function. Ultimately, this work represents yet another complex task that LLMs are capable of solving and promises to help accelerate the deployment of autonomous tuning algorithms to the day-to-day operations of particle accelerators.
Cheetah: Bridging the Gap Between Machine Learning and Particle Accelerator Physics with High-Speed, Differentiable Simulations
Jan 11, 2024Machine learning has emerged as a powerful solution to the modern challenges in accelerator physics. However, the limited availability of beam time, the computational cost of simulations, and the high-dimensionality of optimisation problems pose significant challenges in generating the required data for training state-of-the-art machine learning models. In this work, we introduce Cheetah, a PyTorch-based high-speed differentiable linear-beam dynamics code. Cheetah enables the fast collection of large data sets by reducing computation times by multiple orders of magnitude and facilitates efficient gradient-based optimisation for accelerator tuning and system identification. This positions Cheetah as a user-friendly, readily extensible tool that integrates seamlessly with widely adopted machine learning tools. We showcase the utility of Cheetah through five examples, including reinforcement learning training, gradient-based beamline tuning, gradient-based system identification, physics-informed Bayesian optimisation priors, and modular neural network surrogate modelling of space charge effects. The use of such a high-speed differentiable simulation code will simplify the development of machine learning-based methods for particle accelerators and fast-track their integration into everyday operations of accelerator facilities.
Safe Multi-Task Bayesian Optimization
Dec 12, 2023


Bayesian optimization has become a powerful tool for safe online optimization of systems, due to its high sample efficiency and noise robustness. For further speed-up reduced physical models of the system can be incorporated into the optimization to accelerate the process, since the models are able to offer an approximation of the actual system, and sampling from them is significantly cheaper. The similarity between model and reality is represented by additional hyperparameters and learned within the optimization process. Safety is an important criteria for online optimization methods like Bayesian optimization, which has been addressed by recent literature, which provide safety guarantees under the assumption of known hyperparameters. However, in practice this is not applicable. Therefore, we extend the robust Gaussian process uniform error bounds to meet the multi-task setting, which involves the calculation of a confidence region from the hyperparameter posterior distribution utilizing Markov chain Monte Carlo methods. Then, using the robust safety bounds, Bayesian optimization is applied to safely optimize the system while incorporating measurements of the models. Simulations show that the optimization can be significantly accelerated compared to other state-of-the-art safe Bayesian optimization methods depending on the fidelity of the models.
PACuna: Automated Fine-Tuning of Language Models for Particle Accelerators
Oct 29, 2023
Navigating the landscape of particle accelerators has become increasingly challenging with recent surges in contributions. These intricate devices challenge comprehension, even within individual facilities. To address this, we introduce PACuna, a fine-tuned language model refined through publicly available accelerator resources like conferences, pre-prints, and books. We automated data collection and question generation to minimize expert involvement and make the data publicly available. PACuna demonstrates proficiency in addressing intricate accelerator questions, validated by experts. Our approach shows adapting language models to scientific domains by fine-tuning technical texts and auto-generated corpora capturing the latest developments can further produce pre-trained models to answer some intricate questions that commercially available assistants cannot and can serve as intelligent assistants for individual facilities.
Textual Analysis of ICALEPCS and IPAC Conference Proceedings: Revealing Research Trends, Topics, and Collaborations for Future Insights and Advanced Search
Oct 13, 2023



In this paper, we show a textual analysis of past ICALEPCS and IPAC conference proceedings to gain insights into the research trends and topics discussed in the field. We use natural language processing techniques to extract meaningful information from the abstracts and papers of past conference proceedings. We extract topics to visualize and identify trends, analyze their evolution to identify emerging research directions, and highlight interesting publications based solely on their content with an analysis of their network. Additionally, we will provide an advanced search tool to better search the existing papers to prevent duplication and easier reference findings. Our analysis provides a comprehensive overview of the research landscape in the field and helps researchers and practitioners to better understand the state-of-the-art and identify areas for future research.
Learning to Do or Learning While Doing: Reinforcement Learning and Bayesian Optimisation for Online Continuous Tuning
Jun 06, 2023
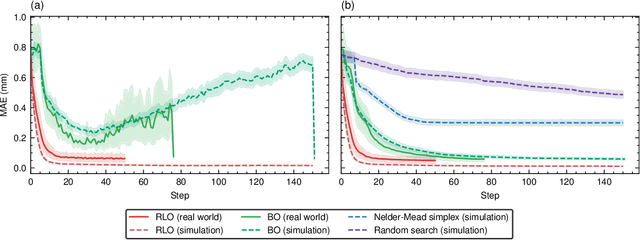


Online tuning of real-world plants is a complex optimisation problem that continues to require manual intervention by experienced human operators. Autonomous tuning is a rapidly expanding field of research, where learning-based methods, such as Reinforcement Learning-trained Optimisation (RLO) and Bayesian optimisation (BO), hold great promise for achieving outstanding plant performance and reducing tuning times. Which algorithm to choose in different scenarios, however, remains an open question. Here we present a comparative study using a routine task in a real particle accelerator as an example, showing that RLO generally outperforms BO, but is not always the best choice. Based on the study's results, we provide a clear set of criteria to guide the choice of algorithm for a given tuning task. These can ease the adoption of learning-based autonomous tuning solutions to the operation of complex real-world plants, ultimately improving the availability and pushing the limits of operability of these facilities, thereby enabling scientific and engineering advancements.