 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Predictive Coding: Inferring, Fast and Slow
Apr 06, 2022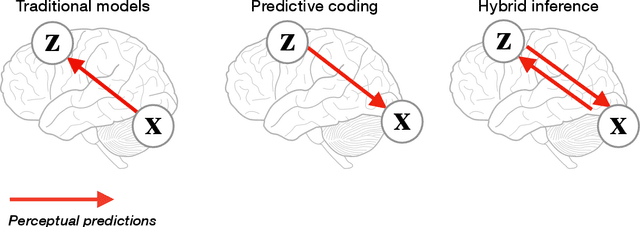
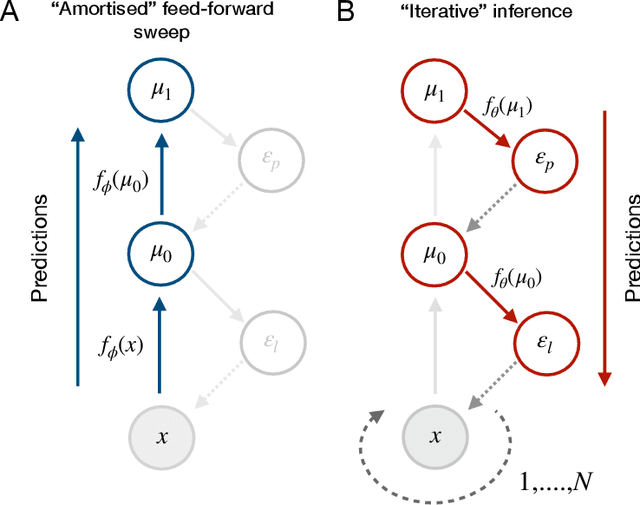
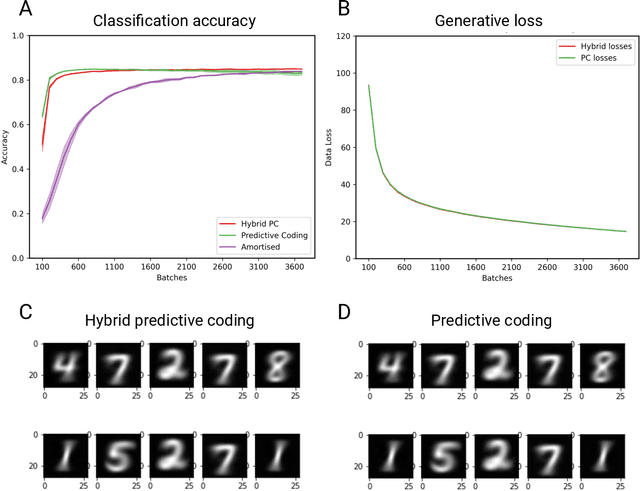
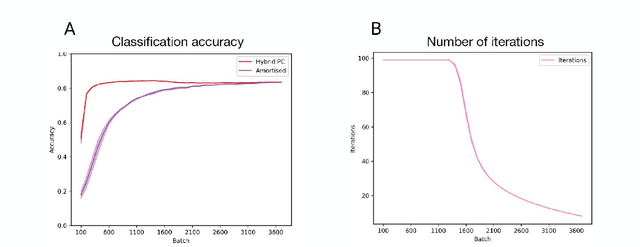
Predictive coding is an influential model of cortical neural activity. It proposes that perceptual beliefs are furnished by sequentially minimising "prediction errors" - the differences between predicted and observed data. Implicit in this proposal is the idea that perception requires multiple cycles of neural activity. This is at odds with evidence that several aspects of visual perception - including complex forms of object recognition - arise from an initial "feedforward sweep" that occurs on fast timescales which preclude substantial recurrent activity. Here, we propose that the feedforward sweep can be understood as performing amortized inference and recurrent processing can be understood as performing iterative inference. We propose a hybrid predictive coding network that combines both iterative and amortized inference in a principled manner by describing both in terms of a dual optimization of a single objective function. We show that the resulting scheme can be implemented in a biologically plausible neural architecture that approximates Bayesian inference utilising local Hebbian update rules. We demonstrate that our hybrid predictive coding model combines the benefits of both amortized and iterative inference -- obtaining rapid and computationally cheap perceptual inference for familiar data while maintaining the context-sensitivity, precision, and sample efficiency of iterative inference schemes. Moreover, we show how our model is inherently sensitive to its uncertainty and adaptively balances iterative and amortized inference to obtain accurate beliefs using minimum computational expense. Hybrid predictive coding offers a new perspective on the functional relevance of the feedforward and recurrent activity observed during visual perception and offers novel insights into distinct aspects of visual phenomenology.
Activation Relaxation: A Local Dynamical Approximation to Backpropagation in the Brain
Oct 10, 2020

The backpropagation of error algorithm (backprop) has been instrumental in the recent success of deep learning. However, a key question remains as to whether backprop can be formulated in a manner suitable for implementation in neural circuitry. The primary challenge is to ensure that any candidate formulation uses only local information, rather than relying on global signals as in standard backprop. Recently several algorithms for approximating backprop using only local signals have been proposed. However, these algorithms typically impose other requirements which challenge biological plausibility: for example, requiring complex and precise connectivity schemes, or multiple sequential backwards phases with information being stored across phases. Here, we propose a novel algorithm, Activation Relaxation (AR), which is motivated by constructing the backpropagation gradient as the equilibrium point of a dynamical system. Our algorithm converges rapidly and robustly to the correct backpropagation gradients, requires only a single type of computational unit, utilises only a single parallel backwards relaxation phase, and can operate on arbitrary computation graphs. We illustrate these properties by training deep neural networks on visual classification tasks, and describe simplifications to the algorithm which remove further obstacles to neurobiological implementation (for example, the weight-transport problem, and the use of nonlinear derivatives), while preserving performance.
Reinforcement Learning as Iterative and Amortised Inference
Jul 05, 2020

There are several ways to categorise reinforcement learning (RL) algorithms, such as either model-based or model-free, policy-based or planning-based, on-policy or off-policy, and online or offline. Broad classification schemes such as these help provide a unified perspective on disparate techniques and can contextualise and guide the development of new algorithms. In this paper, we utilise the control as inference framework to outline a novel classification scheme based on amortised and iterative inference. We demonstrate that a wide range of algorithms can be classified in this manner providing a fresh perspective and highlighting a range of existing similarities. Moreover, we show that taking this perspective allows us to identify parts of the algorithmic design space which have been relatively unexplored, suggesting new routes to innovative RL algorithms.
On the Relationship Between Active Inference and Control as Inference
Jun 29, 2020
Active Inference (AIF) is an emerging framework in the brain sciences which suggests that biological agents act to minimise a variational bound on model evidence. Control-as-Inference (CAI) is a framework within reinforcement learning which casts decision making as a variational inference problem. While these frameworks both consider action selection through the lens of variational inference, their relationship remains unclear. Here, we provide a formal comparison between them and demonstrate that the primary difference arises from how value is incorporated into their respective generative models. In the context of this comparison, we highlight several ways in which these frameworks can inform one another.