 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Implementation of a Multi-Layer Gradient-Free Online-Trainable Spiking Neural Network on FPGA
May 31, 2023This paper presents an efficient hardware implementation of the recently proposed Optimized Deep Event-driven Spiking Neural Network Architecture (ODESA). ODESA is the first network to have end-to-end multi-layer online local supervised training without using gradients and has the combined adaptation of weights and thresholds in an efficient hierarchical structure. This research shows that the network architecture and the online training of weights and thresholds can be implemented efficiently on a large scale in hardware. The implementation consists of a multi-layer Spiking Neural Network (SNN) and individual training modules for each layer that enable online self-learning without using back-propagation. By using simple local adaptive selection thresholds, a Winner-Takes-All (WTA) constraint on each layer, and a modified weight update rule that is more amenable to hardware, the trainer module allocates neuronal resources optimally at each layer without having to pass high-precision error measurements across layers. All elements in the system, including the training module, interact using event-based binary spikes. The hardware-optimized implementation is shown to preserve the performance of the original algorithm across multiple spatial-temporal classification problems with significantly reduced hardware requirements.
Making a Spiking Net Work: Robust brain-like unsupervised machine learning
Aug 02, 2022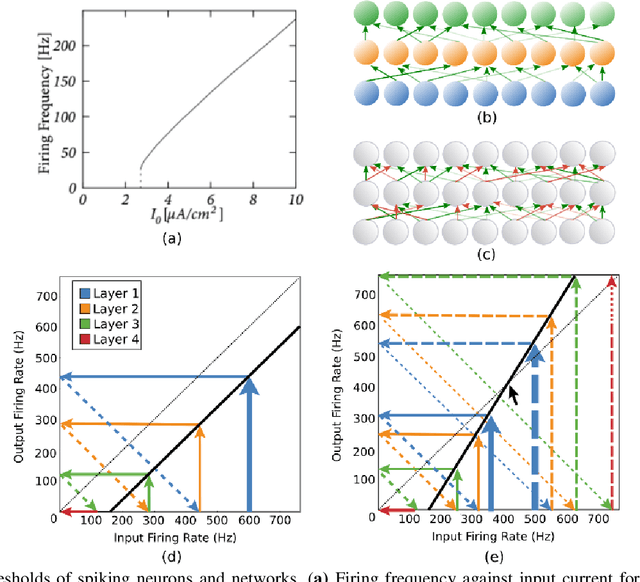
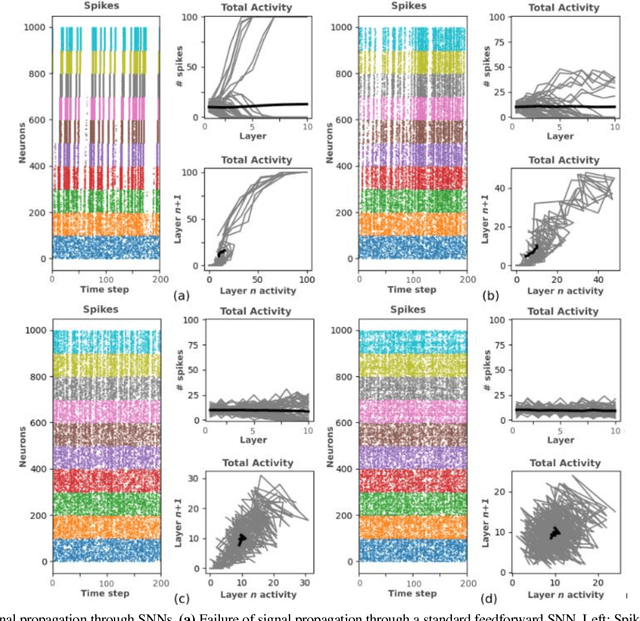
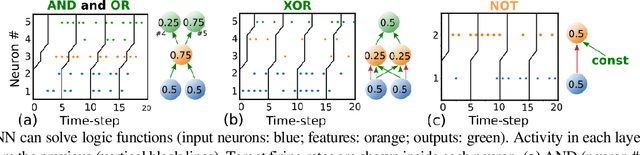
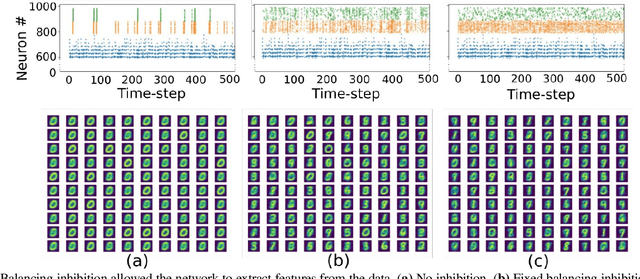
The surge in interest in Artificial Intelligence (AI) over the past decade has been driven almost exclusively by advances in Artificial Neural Networks (ANNs). While ANNs set state-of-the-art performance for many previously intractable problems, they require large amounts of data and computational resources for training, and since they employ supervised learning they typically need to know the correctly labelled response for every training example, limiting their scalability for real-world domains. Spiking Neural Networks (SNNs) are an alternative to ANNs that use more brain-like artificial neurons and can use unsupervised learning to discover recognizable features in the input data without knowing correct responses. SNNs, however, struggle with dynamical stability and cannot match the accuracy of ANNs. Here we show how an SNN can overcome many of the shortcomings that have been identified in the literature, including offering a principled solution to the vanishing spike problem, to outperform all existing shallow SNNs and equal the performance of an ANN. It accomplishes this while using unsupervised learning with unlabeled data and only 1/50th of the training epochs (labelled data is used only for a final simple linear readout layer). This result makes SNNs a viable new method for fast, accurate, efficient, explainable, and re-deployable machine learning with unlabeled datasets.