 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Length Empirical Comparison of Polar, PAC, and Invertible-Extractor Secrecy Codes over the Wiretap BSC
Apr 21, 2026We compare three secrecy-coding schemes for the degraded wiretap binary symmetric channel (BSC) in the finite-blocklength regime: (i) polar wiretap coset codes, (ii) PAC codes used as wiretap coset codes, and (iii) the invertible-extractor (IE) framework of Bellare-Tessaro. Our comparison is empirical and uses a common semantic-secrecy metric (distinguishing advantage). For polar coset codes, we compute Eve's polarized bit-channel capacities (via the Tal-Vardy construction) to obtain explicit finite-length upper bounds on mutual-information leakage, yielding strong secrecy bounds. For PAC coset codes, we prove that Eve's synthesized bit-channels are equivalent to those of polar codes (up to a permutation), so the same leakage bounds apply; we then convert these strong-secrecy bounds into semantic-secrecy guarantees for symmetric wiretap channels. For the IE scheme, we use the closed-form semantic-secrecy bounds given in the reference work. Finally, we report finite-length results that jointly characterize (a) semantic-secrecy guarantees against Eve and (b) frame-error-rate performance at Bob, illustrating that PAC codes can significantly improve reliability without changing the secrecy bounds inherited from polar coding. Moreover, under the finite-length bounds considered in this work, polar/PAC secrecy codes provide tighter security guarantees than the invertible-extractor framework.
Rate of Model Collapse in Recursive Training
Dec 23, 2024



Given the ease of creating synthetic data from machine learning models, new models can be potentially trained on synthetic data generated by previous models. This recursive training process raises concerns about the long-term impact on model quality. As models are recursively trained on generated data from previous rounds, their ability to capture the nuances of the original human-generated data may degrade. This is often referred to as \emph{model collapse}. In this work, we ask how fast model collapse occurs for some well-studied distribution families under maximum likelihood (ML or near ML) estimation during recursive training. Surprisingly, even for fundamental distributions such as discrete and Gaussian distributions, the exact rate of model collapse is unknown. In this work, we theoretically characterize the rate of collapse in these fundamental settings and complement it with experimental evaluations. Our results show that for discrete distributions, the time to forget a word is approximately linearly dependent on the number of times it occurred in the original corpus, and for Gaussian models, the standard deviation reduces to zero roughly at $n$ iterations, where $n$ is the number of samples at each iteration. Both of these findings imply that model forgetting, at least in these simple distributions under near ML estimation with many samples, takes a long time.
Just Wing It: Optimal Estimation of Missing Mass in a Markovian Sequence
Apr 08, 2024We study the problem of estimating the stationary mass -- also called the unigram mass -- that is missing from a single trajectory of a discrete-time, ergodic Markov chain. This problem has several applications -- for example, estimating the stationary missing mass is critical for accurately smoothing probability estimates in sequence models. While the classical Good--Turing estimator from the 1950s has appealing properties for i.i.d. data, it is known to be biased in the Markov setting, and other heuristic estimators do not come equipped with guarantees. Operating in the general setting in which the size of the state space may be much larger than the length $n$ of the trajectory, we develop a linear-runtime estimator called \emph{Windowed Good--Turing} (\textsc{WingIt}) and show that its risk decays as $\widetilde{\mathcal{O}}(\mathsf{T_{mix}}/n)$, where $\mathsf{T_{mix}}$ denotes the mixing time of the chain in total variation distance. Notably, this rate is independent of the size of the state space and minimax-optimal up to a logarithmic factor in $n / \mathsf{T_{mix}}$. We also present a bound on the variance of the missing mass random variable, which may be of independent interest. We extend our estimator to approximate the stationary mass placed on elements occurring with small frequency in $X^n$. Finally, we demonstrate the efficacy of our estimators both in simulations on canonical chains and on sequences constructed from a popular natural language corpus.
Missing Mass of Rank-2 Markov Chains
Feb 06, 2021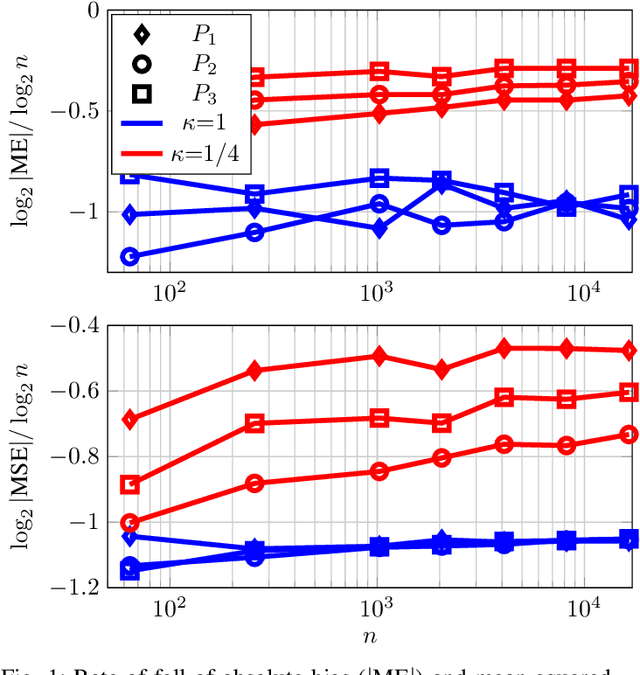
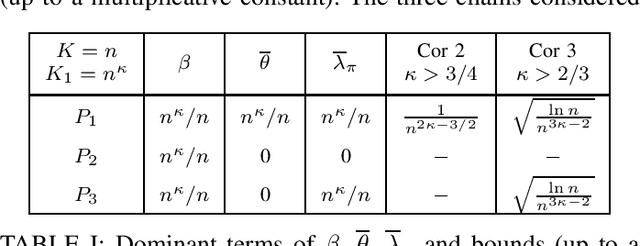
Estimation of missing mass with the popular Good-Turing (GT) estimator is well-understood in the case where samples are independent and identically distributed (iid). In this article, we consider the same problem when the samples come from a stationary Markov chain with a rank-2 transition matrix, which is one of the simplest extensions of the iid case. We develop an upper bound on the absolute bias of the GT estimator in terms of the spectral gap of the chain and a tail bound on the occupancy of states. Borrowing tail bounds from known concentration results for Markov chains, we evaluate the bound using other parameters of the chain. The analysis, supported by simulations, suggests that, for rank-2 irreducible chains, the GT estimator has bias and mean-squared error falling with number of samples at a rate that depends loosely on the connectivity of the states in the chain.