 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection Latencies of Anomaly Detectors: An Overlooked Perspective ?
Feb 14, 2024
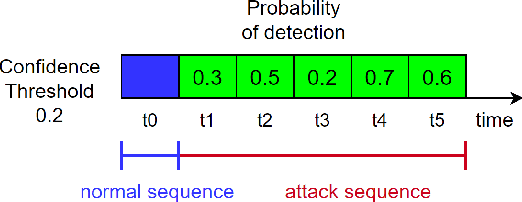
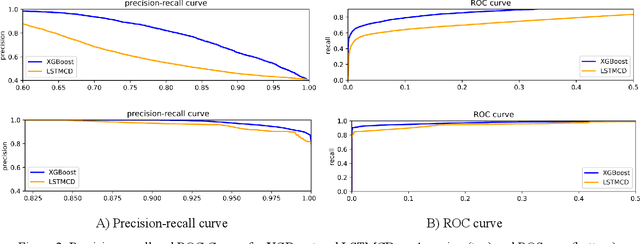
The ever-evolving landscape of attacks, coupled with the growing complexity of ICT systems, makes crafting anomaly-based intrusion detectors (ID) and error detectors (ED) a difficult task: they must accurately detect attacks, and they should promptly perform detections. Although improving and comparing the detection capability is the focus of most research works, the timeliness of the detection is less considered and often insufficiently evaluated or discussed. In this paper, we argue the relevance of measuring the temporal latency of attacks and errors, and we propose an evaluation approach for detectors to ensure a pragmatic trade-off between correct and in-time detection. Briefly, the approach relates the false positive rate with the temporal latency of attacks and errors, and this ultimately leads to guidelines for configuring a detector. We apply our approach by evaluating different ED and ID solutions in two industrial cases: i) an embedded railway on-board system that optimizes public mobility, and ii) an edge device for the Industrial Internet of Things. Our results show that considering latency in addition to traditional metrics like the false positive rate, precision, and coverage gives an additional fundamental perspective on the actual performance of the detector and should be considered when assessing and configuring anomaly detectors.
ROSpace: Intrusion Detection Dataset for a ROS2-Based Cyber-Physical System
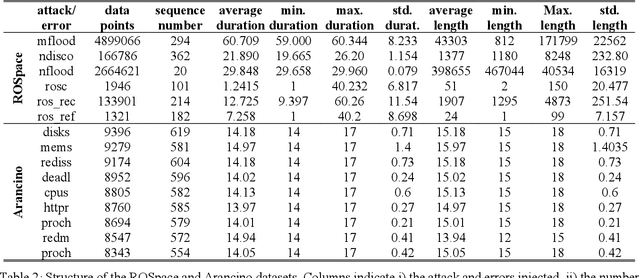
Feb 13, 2024Most of the intrusion detection datasets to research machine learning-based intrusion detection systems (IDSs) are devoted to cyber-only systems, and they typically collect data from one architectural layer. Additionally, often the attacks are generated in dedicated attack sessions, without reproducing the realistic alternation and overlap of normal and attack actions. We present a dataset for intrusion detection by performing penetration testing on an embedded cyber-physical system built over Robot Operating System 2 (ROS2). Features are monitored from three architectural layers: the Linux operating system, the network, and the ROS2 services. The dataset is structured as a time series and describes the expected behavior of the system and its response to ROS2-specific attacks: it repeatedly alternates periods of attack-free operation with periods when a specific attack is being performed. Noteworthy, this allows measuring the time to detect an attacker and the number of malicious activities performed before detection. Also, it allows training an intrusion detector to minimize both, by taking advantage of the numerous alternating periods of normal and attack operations.
Ensembling Uncertainty Measures to Improve Safety of Black-Box Classifiers
Aug 23, 2023
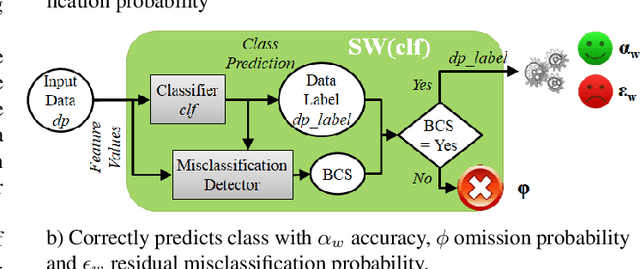

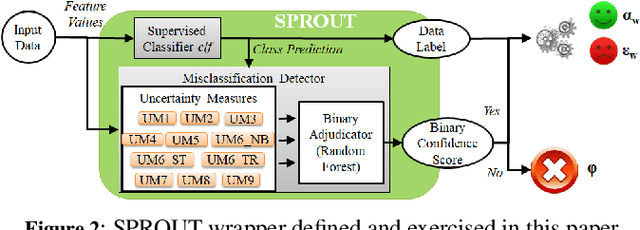
Machine Learning (ML) algorithms that perform classification may predict the wrong class, experiencing misclassifications. It is well-known that misclassifications may have cascading effects on the encompassing system, possibly resulting in critical failures. This paper proposes SPROUT, a Safety wraPper thROugh ensembles of UncertainTy measures, which suspects misclassifications by computing uncertainty measures on the inputs and outputs of a black-box classifier. If a misclassification is detected, SPROUT blocks the propagation of the output of the classifier to the encompassing system. The resulting impact on safety is that SPROUT transforms erratic outputs (misclassifications) into data omission failures, which can be easily managed at the system level. SPROUT has a broad range of applications as it fits binary and multi-class classification, comprising image and tabular datasets. We experimentally show that SPROUT always identifies a huge fraction of the misclassifications of supervised classifiers, and it is able to detect all misclassifications in specific cases. SPROUT implementation contains pre-trained wrappers, it is publicly available and ready to be deployed with minimal effort.
On the Efficacy of Metrics to Describe Adversarial Attacks
Jan 30, 2023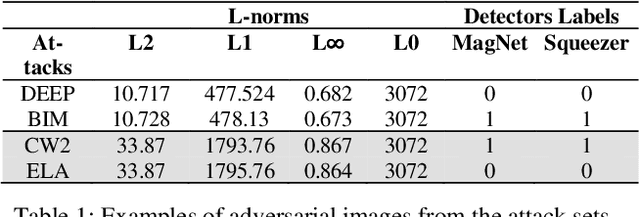
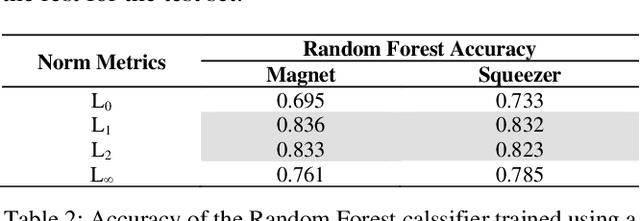
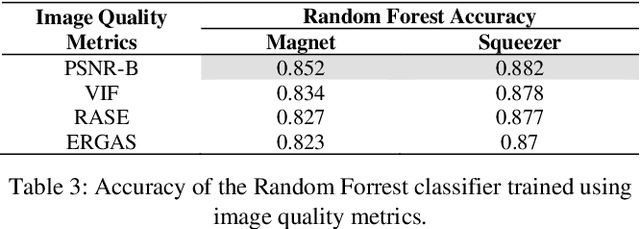

Adversarial defenses are naturally evaluated on their ability to tolerate adversarial attacks. To test defenses, diverse adversarial attacks are crafted, that are usually described in terms of their evading capability and the L0, L1, L2, and Linf norms. We question if the evading capability and L-norms are the most effective information to claim that defenses have been tested against a representative attack set. To this extent, we select image quality metrics from the state of the art and search correlations between image perturbation and detectability. We observe that computing L-norms alone is rarely the preferable solution. We observe a strong correlation between the identified metrics computed on an adversarial image and the output of a detector on such an image, to the extent that they can predict the response of a detector with approximately 0.94 accuracy. Further, we observe that metrics can classify attacks based on similar perturbations and similar detectability. This suggests a possible review of the approach to evaluate detectors, where additional metrics are included to assure that a representative attack dataset is selected.
Safety-aware metrics for object detectors in autonomous driving
Mar 04, 2022
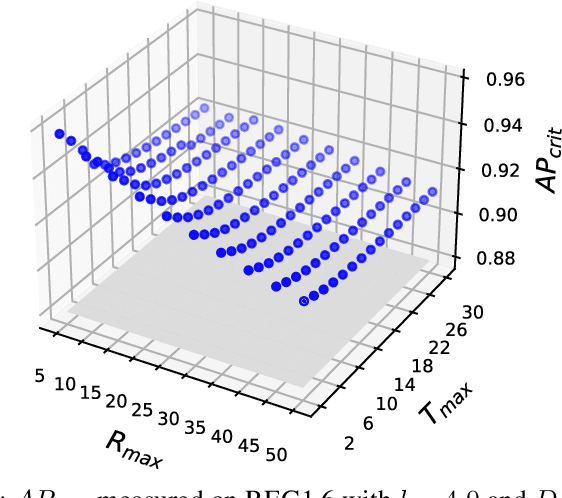
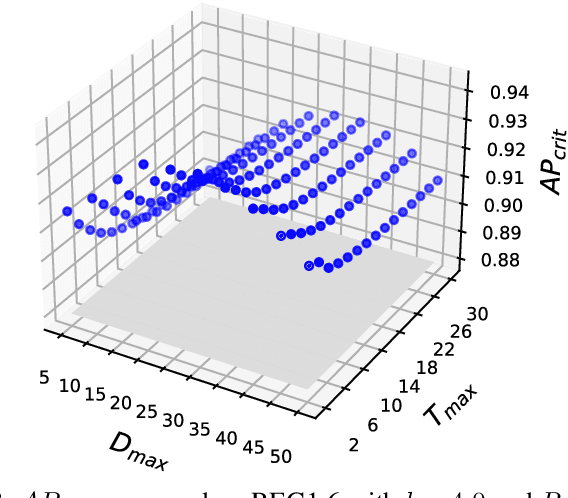
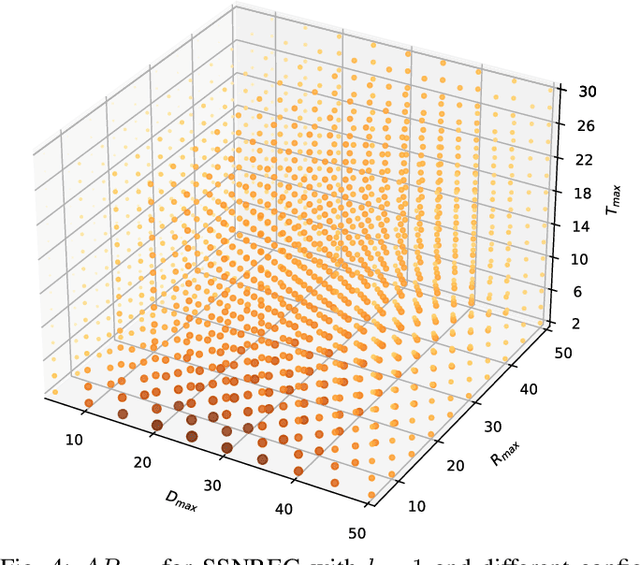
We argue that object detectors in the safety critical domain should prioritize detection of objects that are most likely to interfere with the actions of the autonomous actor. Especially, this applies to objects that can impact the actor's safety and reliability. In the context of autonomous driving, we propose new object detection metrics that reward the correct identification of objects that are most likely to interact with the subject vehicle (i.e., the actor), and that may affect its driving decision. To achieve this, we build a criticality model to reward the detection of the objects based on proximity, orientation, and relative velocity with respect to the subject vehicle. Then, we apply our model on the recent autonomous driving dataset nuScenes, and we compare eight different object detectors. Results show that, in several settings, object detectors that perform best according to the nuScenes ranking are not the preferable ones when the focus is shifted on safety and reliability.
Prepare for Trouble and Make it Double. Supervised and Unsupervised Stacking for AnomalyBased Intrusion Detection
Feb 28, 2022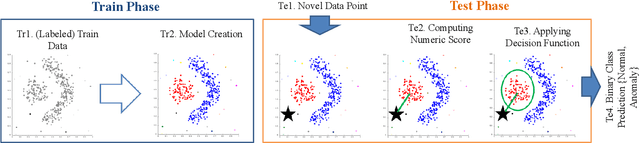
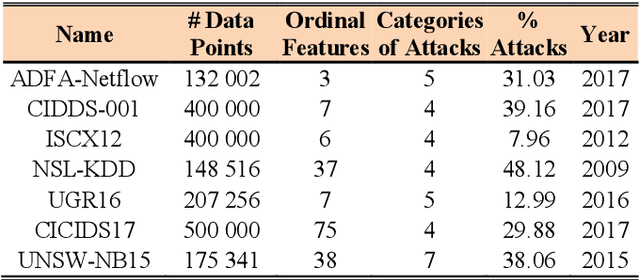
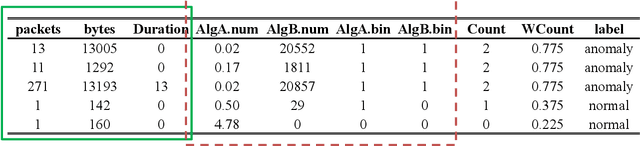

In the last decades, researchers, practitioners and companies struggled in devising mechanisms to detect malicious activities originating security threats. Amongst the many solutions, network intrusion detection emerged as one of the most popular to analyze network traffic and detect ongoing intrusions based on rules or by means of Machine Learners (MLs), which process such traffic and learn a model to suspect intrusions. Supervised MLs are very effective in detecting known threats, but struggle in identifying zero-day attacks (unknown during learning phase), which instead can be detected through unsupervised MLs. Unfortunately, there are no definitive answers on the combined use of both approaches for network intrusion detection. In this paper we first expand the problem of zero-day attacks and motivate the need to combine supervised and unsupervised algorithms. We propose the adoption of meta-learning, in the form of a two-layer Stacker, to create a mixed approach that detects both known and unknown threats. Then we implement and empirically evaluate our Stacker through an experimental campaign that allows i) debating on meta-features crafted through unsupervised base-level learners, ii) electing the most promising supervised meta-level classifiers, and iii) benchmarking classification scores of the Stacker with respect to supervised and unsupervised classifiers. Last, we compare our solution with existing works from the recent literature. Overall, our Stacker reduces misclassifications with respect to (un)supervised ML algorithms in all the 7 public datasets we considered, and outperforms existing studies in 6 out of those 7 datasets. In particular, it turns out to be more effective in detecting zero-day attacks than supervised algorithms, limiting their main weakness but still maintaining adequate capabilities in detecting known attacks.
* This is a pre-print version. Full version available at Elsevier JNCA
Attacks and Faults Injection in Self-Driving Agents on the Carla Simulator -- Experience Report
Feb 25, 2022
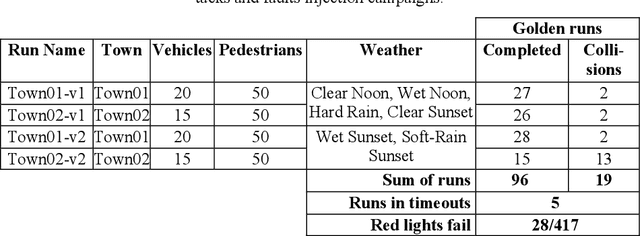
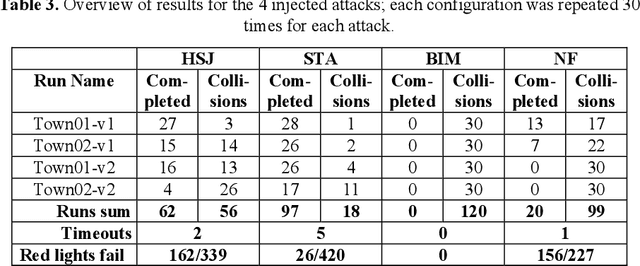
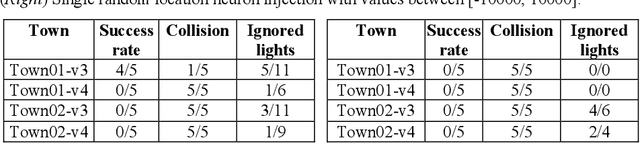
Machine Learning applications are acknowledged at the foundation of autonomous driving, because they are the enabling technology for most driving tasks. However, the inclusion of trained agents in automotive systems exposes the vehicle to novel attacks and faults, that can result in safety threats to the driv-ing tasks. In this paper we report our experimental campaign on the injection of adversarial attacks and software faults in a self-driving agent running in a driving simulator. We show that adversarial attacks and faults injected in the trained agent can lead to erroneous decisions and severely jeopardize safety. The paper shows a feasible and easily-reproducible approach based on open source simula-tor and tools, and the results clearly motivate the need of both protective measures and extensive testing campaigns.
On failures of RGB cameras and their effects in autonomous driving applications
Aug 13, 2020
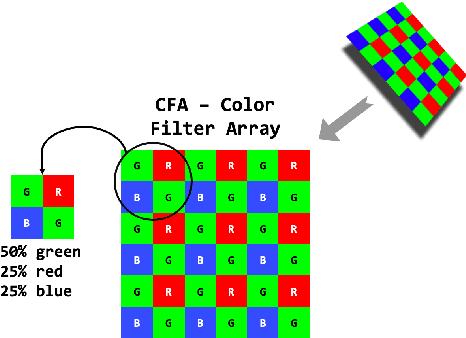


RGB cameras are arguably one of the most relevant sensors for autonomous driving applications. It is undeniable that failures of vehicle cameras may compromise the autonomous driving task, possibly leading to unsafe behaviors when images that are subsequently processed by the driving system are altered. To support the definition of safe and robust vehicle architectures and intelligent systems, in this paper we define the failures model of a vehicle camera, together with an analysis of effects and known mitigations. Further, we build a software library for the generation of the corresponding failed images and we feed them to the trained agent of an autonomous driving simulator: the misbehavior of the trained agent allows a better understanding of failures effects and especially of the resulting safety risk.