 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill Learning Using Process Mining for Large Language Model Plan Generation
Oct 14, 2024Large language models (LLMs) hold promise for generating plans for complex tasks, but their effectiveness is limited by sequential execution, lack of control flow models, and difficulties in skill retrieval. Addressing these issues is crucial for improving the efficiency and interpretability of plan generation as LLMs become more central to automation and decision-making. We introduce a novel approach to skill learning in LLMs by integrating process mining techniques, leveraging process discovery for skill acquisition, process models for skill storage, and conformance checking for skill retrieval. Our methods enhance text-based plan generation by enabling flexible skill discovery, parallel execution, and improved interpretability. Experimental results suggest the effectiveness of our approach, with our skill retrieval method surpassing state-of-the-art accuracy baselines under specific conditions.
ProcessTBench: An LLM Plan Generation Dataset for Process Mining
Sep 13, 2024Large Language Models (LLMs) have shown significant promise in plan generation. Yet, existing datasets often lack the complexity needed for advanced tool use scenarios - such as handling paraphrased query statements, supporting multiple languages, and managing actions that can be done in parallel. These scenarios are crucial for evaluating the evolving capabilities of LLMs in real-world applications. Moreover, current datasets don't enable the study of LLMs from a process perspective, particularly in scenarios where understanding typical behaviors and challenges in executing the same process under different conditions or formulations is crucial. To address these gaps, we present the ProcessTBench dataset, an extension of the TaskBench dataset specifically designed to evaluate LLMs within a process mining framework.
A Monitoring and Discovery Approach for Declarative Processes Based on Streams
Aug 10, 2022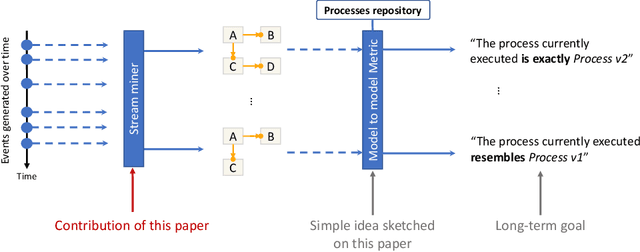



Process discovery is a family of techniques that helps to comprehend processes from their data footprints. Yet, as processes change over time so should their corresponding models, and failure to do so will lead to models that under- or over-approximate behavior. We present a discovery algorithm that extracts declarative processes as Dynamic Condition Response (DCR) graphs from event streams. Streams are monitored to generate temporal representations of the process, later processed to generate declarative models. We validated the technique via quantitative and qualitative evaluations. For the quantitative evaluation, we adopted an extended Jaccard similarity measure to account for process change in a declarative setting. For the qualitative evaluation, we showcase how changes identified by the technique correspond to real changes in an existing process. The technique and the data used for testing are available online.
Online Soft Conformance Checking: Any Perspective Can Indicate Deviations
Jan 23, 2022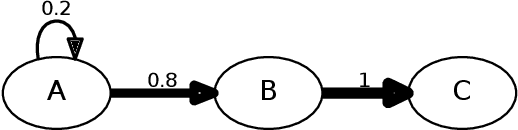


Within process mining, a relevant activity is conformance checking. Such activity consists of establishing the extent to which actual executions of a process conform the expected behavior of a reference model. Current techniques focus on prescriptive models of the control-flow as references. In certain scenarios, however, a prescriptive model might not be available and, additionally, the control-flow perspective might not be ideal for this purpose. This paper tackles these two problems by suggesting a conformance approach that uses a descriptive model (i.e., a pattern of the observed behavior over a certain amount of time) which is not necessarily referring to the control-flow (e.g., it can be based on the social network of handover of work). Additionally, the entire approach can work both offline and online, thus providing feedback in real time. The approach, which is implemented in ProM, has been tested and results from 3 experiments with real world as well as synthetic data are reported.
Time and Activity Sequence Prediction of Business Process Instances
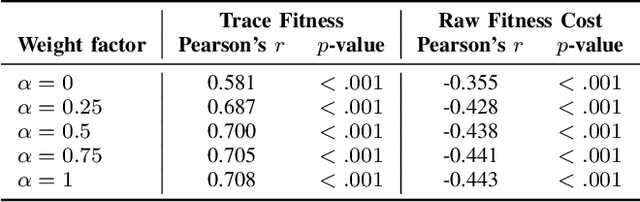
Feb 24, 2016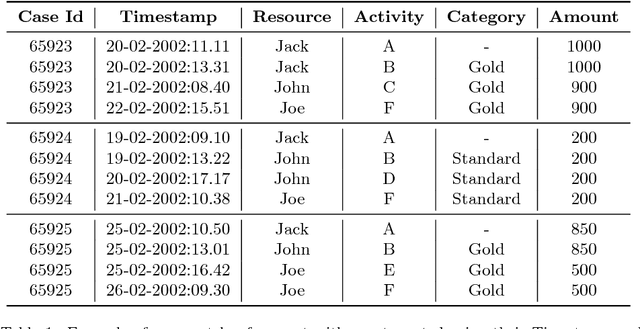
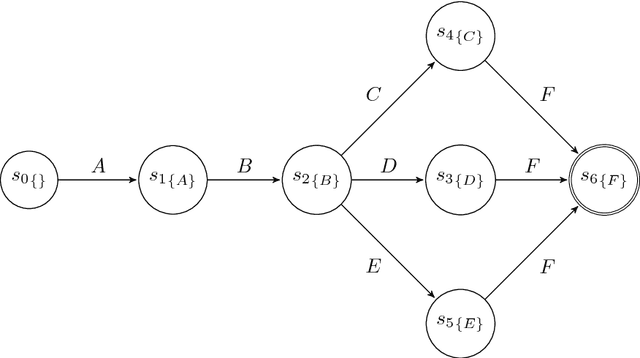
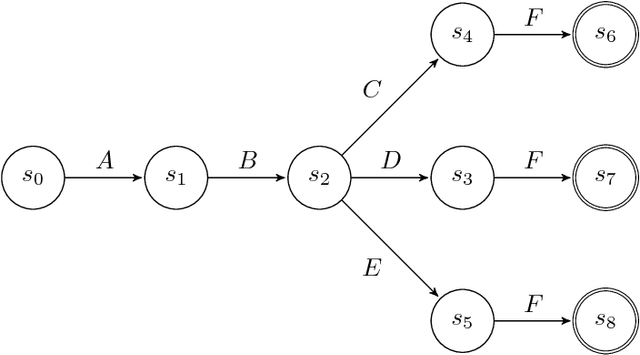

The ability to know in advance the trend of running process instances, with respect to different features, such as the expected completion time, would allow business managers to timely counteract to undesired situations, in order to prevent losses. Therefore, the ability to accurately predict future features of running business process instances would be a very helpful aid when managing processes, especially under service level agreement constraints. However, making such accurate forecasts is not easy: many factors may influence the predicted features. Many approaches have been proposed to cope with this problem but all of them assume that the underling process is stationary. However, in real cases this assumption is not always true. In this work we present new methods for predicting the remaining time of running cases. In particular we propose a method, assuming process stationarity, which outperforms the state-of-the-art and two other methods which are able to make predictions even with non-stationary processes. We also describe an approach able to predict the full sequence of activities that a running case is going to take. All these methods are extensively evaluated on two real case studies.