 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-based marker tracking and registration for intraoperative 3D image-guided interventions using augmented reality
Aug 08, 2019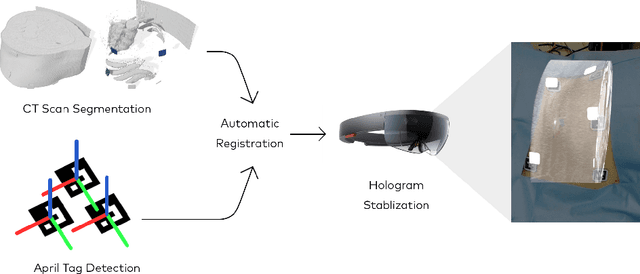
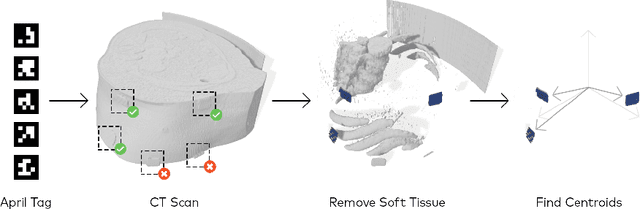
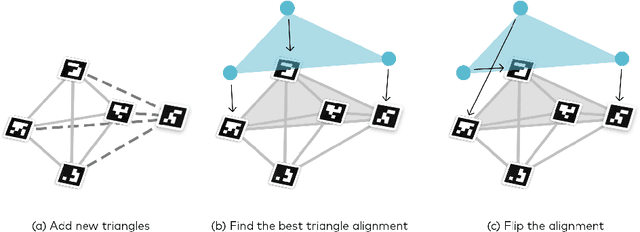
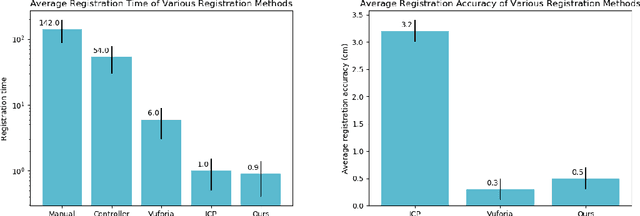
Augmented reality has the potential to improve operating room workflow by allowing physicians to "see" inside a patient through the projection of imaging directly onto the surgical field. For this to be useful the acquired imaging must be quickly and accurately registered with patient and the registration must be maintained. Here we describe a method for projecting a CT scan with Microsoft Hololens and then aligning that projection to a set of fiduciary markers. Radio-opaque stickers with unique QR-codes are placed on an object prior to acquiring a CT scan. The location of the markers in the CT scan are extracted and the CT scan is converted into a 3D surface object. The 3D object is then projected using the Hololens onto a table on which the same markers are placed. We designed an algorithm that aligns the markers on the 3D object with the markers on the table. To extract the markers and convert the CT into a 3D object took less than 5 seconds. To align three markers, it took $0.9 \pm 0.2$ seconds to achieve an accuracy of $5 \pm 2$ mm. These findings show that it is feasible to use a combined radio-opaque optical marker, placed on a patient prior to a CT scan, to subsequently align the acquired CT scan with the patient.
Neural Embedding for Physical Manipulations
Jul 13, 2019

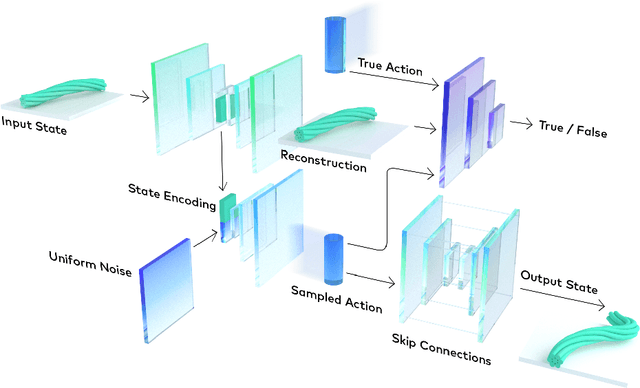

In common real-world robotic operations, action and state spaces can be vast and sometimes unknown, and observations are often relatively sparse. How do we learn the full topology of action and state spaces when given only few and sparse observations? Inspired by the properties of grid cells in mammalian brains, we build a generative model that enforces a normalized pairwise distance constraint between the latent space and output space to achieve data-efficient discovery of output spaces. This method achieves substantially better results than prior generative models, such as Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs). Prior models have the common issue of mode collapse and thus fail to explore the full topology of output space. We demonstrate the effectiveness of our model on various datasets both qualitatively and quantitatively.