 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Counterfactual Explanations for Machine Learning-Controlled Mobile Robots using 2D LiDAR
May 11, 2025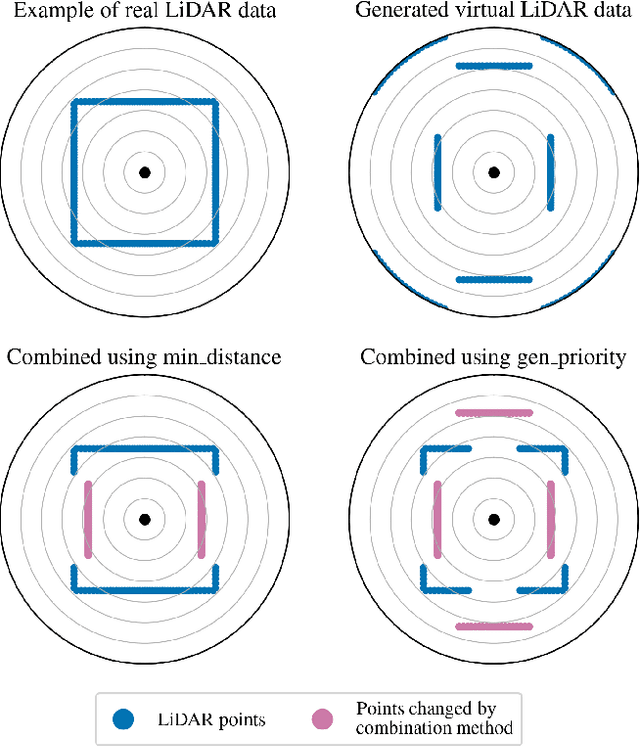
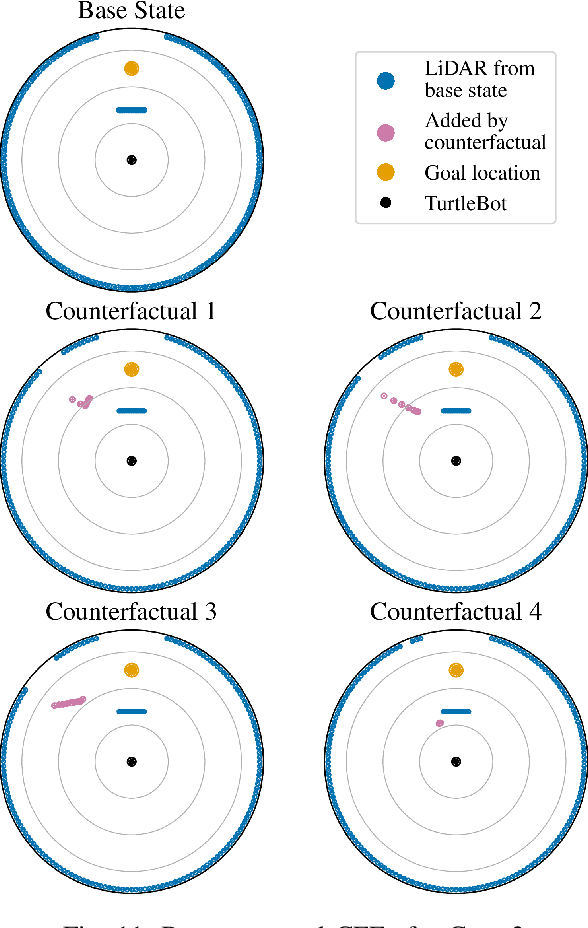
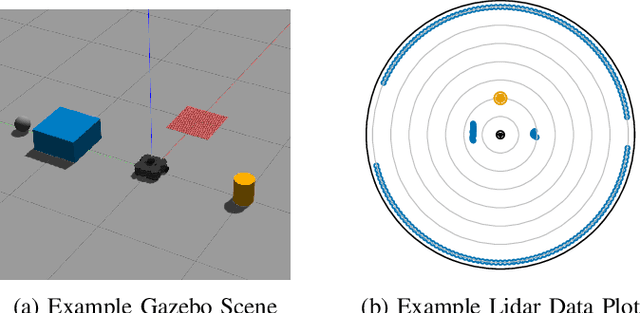
This paper presents a novel method for generating realistic counterfactual explanations (CFEs) in machine learning (ML)-based control for mobile robots using 2D LiDAR. ML models, especially artificial neural networks (ANNs), can provide advanced decision-making and control capabilities by learning from data. However, they often function as black boxes, making it challenging to interpret them. This is especially a problem in safety-critical control applications. To generate realistic CFEs, we parameterize the LiDAR space with simple shapes such as circles and rectangles, whose parameters are chosen by a genetic algorithm, and the configurations are transformed into LiDAR data by raycasting. Our model-agnostic approach generates CFEs in the form of synthetic LiDAR data that resembles a base LiDAR state but is modified to produce a pre-defined ML model control output based on a query from the user. We demonstrate our method on a mobile robot, the TurtleBot3, controlled using deep reinforcement learning (DRL) in real-world and simulated scenarios. Our method generates logical and realistic CFEs, which helps to interpret the DRL agent's decision making. This paper contributes towards advancing explainable AI in mobile robotics, and our method could be a tool for understanding, debugging, and improving ML-based autonomous control.
Deep Reinforcement Learning Behavioral Mode Switching Using Optimal Control Based on a Latent Space Objective
Jun 03, 2024In this work, we use optimal control to change the behavior of a deep reinforcement learning policy by optimizing directly in the policy's latent space. We hypothesize that distinct behavioral patterns, termed behavioral modes, can be identified within certain regions of a deep reinforcement learning policy's latent space, meaning that specific actions or strategies are preferred within these regions. We identify these behavioral modes using latent space dimension-reduction with \ac*{pacmap}. Using the actions generated by the optimal control procedure, we move the system from one behavioral mode to another. We subsequently utilize these actions as a filter for interpreting the neural network policy. The results show that this approach can impose desired behavioral modes in the policy, demonstrated by showing how a failed episode can be made successful and vice versa using the lunar lander reinforcement learning environment.
Discovering Behavioral Modes in Deep Reinforcement Learning Policies Using Trajectory Clustering in Latent Space
Feb 20, 2024



Understanding the behavior of deep reinforcement learning (DRL) agents is crucial for improving their performance and reliability. However, the complexity of their policies often makes them challenging to understand. In this paper, we introduce a new approach for investigating the behavior modes of DRL policies, which involves utilizing dimensionality reduction and trajectory clustering in the latent space of neural networks. Specifically, we use Pairwise Controlled Manifold Approximation Projection (PaCMAP) for dimensionality reduction and TRACLUS for trajectory clustering to analyze the latent space of a DRL policy trained on the Mountain Car control task. Our methodology helps identify diverse behavior patterns and suboptimal choices by the policy, thus allowing for targeted improvements. We demonstrate how our approach, combined with domain knowledge, can enhance a policy's performance in specific regions of the state space.
Real-Time Counterfactual Explanations For Robotic Systems With Multiple Continuous Outputs
Dec 08, 2022



Although many machine learning methods, especially from the field of deep learning, have been instrumental in addressing challenges within robotic applications, we cannot take full advantage of such methods before these can provide performance and safety guarantees. The lack of trust that impedes the use of these methods mainly stems from a lack of human understanding of what exactly machine learning models have learned, and how robust their behaviour is. This is the problem the field of explainable artificial intelligence aims to solve. Based on insights from the social sciences, we know that humans prefer contrastive explanations, i.e.\ explanations answering the hypothetical question "what if?". In this paper, we show that linear model trees are capable of producing answers to such questions, so-called counterfactual explanations, for robotic systems, including in the case of multiple, continuous inputs and outputs. We demonstrate the use of this method to produce counterfactual explanations for two robotic applications. Additionally, we explore the issue of infeasibility, which is of particular interest in systems governed by the laws of physics.
Approximating a deep reinforcement learning docking agent using linear model trees
Mar 01, 2022
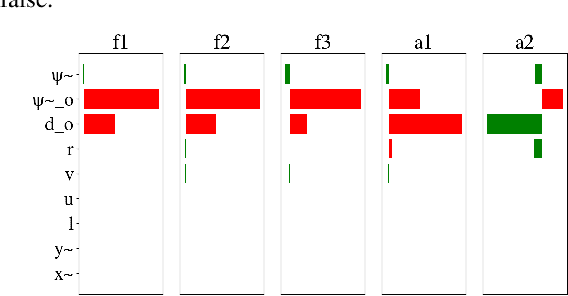
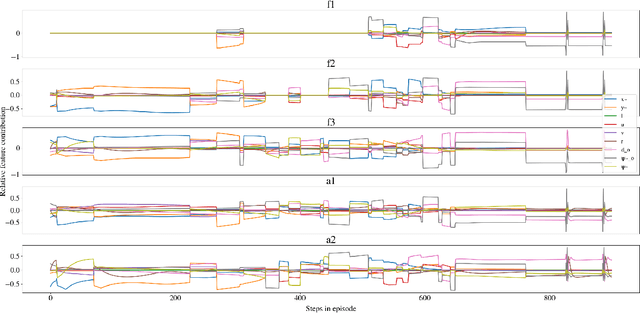
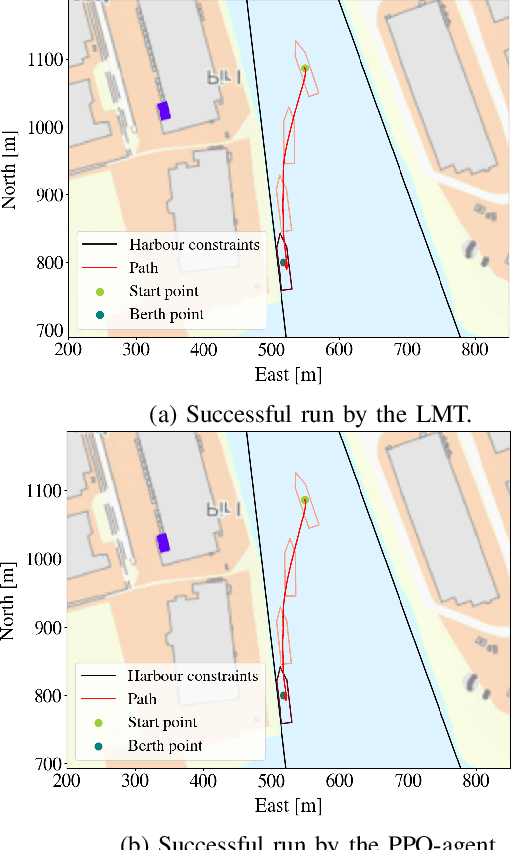
Deep reinforcement learning has led to numerous notable results in robotics. However, deep neural networks (DNNs) are unintuitive, which makes it difficult to understand their predictions and strongly limits their potential for real-world applications due to economic, safety, and assurance reasons. To remedy this problem, a number of explainable AI methods have been presented, such as SHAP and LIME, but these can be either be too costly to be used in real-time robotic applications or provide only local explanations. In this paper, the main contribution is the use of a linear model tree (LMT) to approximate a DNN policy, originally trained via proximal policy optimization(PPO), for an autonomous surface vehicle with five control inputs performing a docking operation. The two main benefits of the proposed approach are: a) LMTs are transparent which makes it possible to associate directly the outputs (control actions, in our case) with specific values of the input features, b) LMTs are computationally efficient and can provide information in real-time. In our simulations, the opaque DNN policy controls the vehicle and the LMT runs in parallel to provide explanations in the form of feature attributions. Our results indicate that LMTs can be a useful component within digital assurance frameworks for autonomous ships.
Explaining a Deep Reinforcement Learning Docking Agent Using Linear Model Trees with User Adapted Visualization
Mar 01, 2022
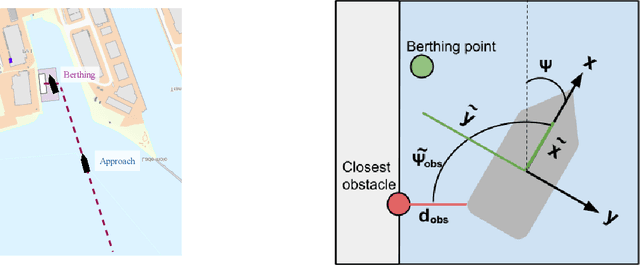
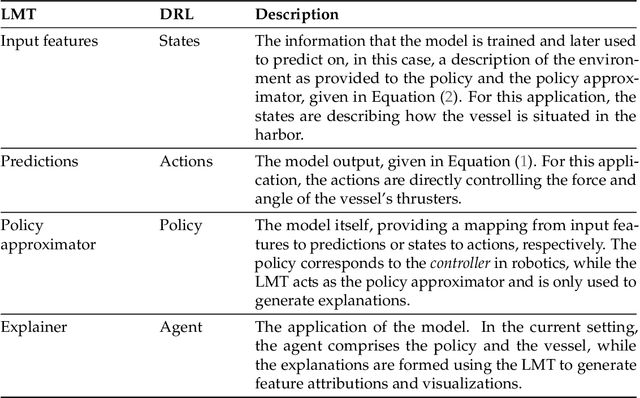
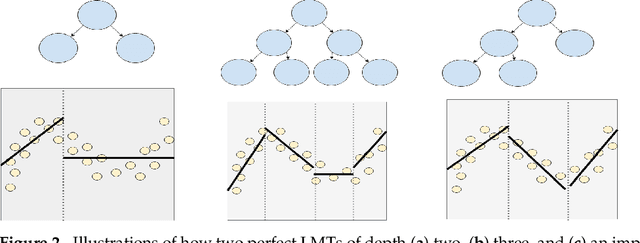
Deep neural networks (DNNs) can be useful within the marine robotics field, but their utility value is restricted by their black-box nature. Explainable artificial intelligence methods attempt to understand how such black-boxes make their decisions. In this work, linear model trees (LMTs) are used to approximate the DNN controlling an autonomous surface vessel (ASV) in a simulated environment and then run in parallel with the DNN to give explanations in the form of feature attributions in real-time. How well a model can be understood depends not only on the explanation itself, but also on how well it is presented and adapted to the receiver of said explanation. Different end-users may need both different types of explanations, as well as different representations of these. The main contributions of this work are (1) significantly improving both the accuracy and the build time of a greedy approach for building LMTs by introducing ordering of features in the splitting of the tree, (2) giving an overview of the characteristics of the seafarer/operator and the developer as two different end-users of the agent and receiver of the explanations, and (3) suggesting a visualization of the docking agent, the environment, and the feature attributions given by the LMT for when the developer is the end-user of the system, and another visualization for when the seafarer or operator is the end-user, based on their different characteristics.
Causal versus Marginal Shapley Values for Robotic Lever Manipulation Controlled using Deep Reinforcement Learning
Nov 04, 2021

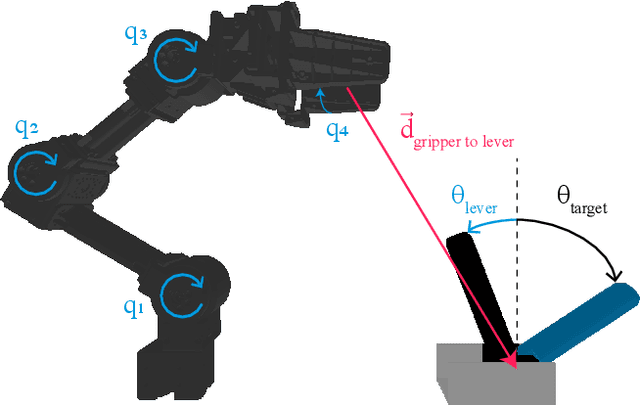
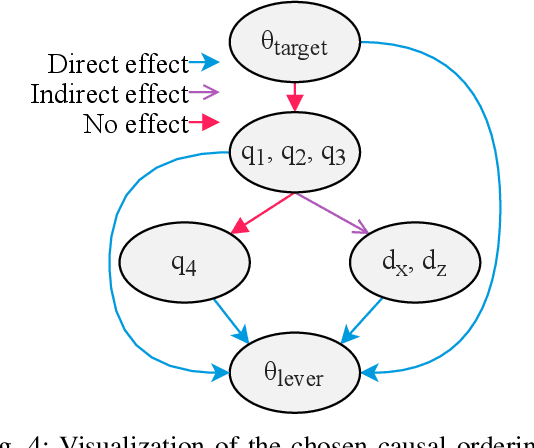
We investigate the effect of including domain knowledge about a robotic system's causal relations when generating explanations. To this end, we compare two methods from explainable artificial intelligence, the popular KernelSHAP and the recent causal SHAP, on a deep neural network trained using deep reinforcement learning on the task of controlling a lever using a robotic manipulator. A primary disadvantage of KernelSHAP is that its explanations represent only the features' direct effects on a model's output, not considering the indirect effects a feature can have on the output by affecting other features. Causal SHAP uses a partial causal ordering to alter KernelSHAP's sampling procedure to incorporate these indirect effects. This partial causal ordering defines the causal relations between the features, and we specify this using domain knowledge about the lever control task. We show that enabling an explanation method to account for indirect effects and incorporating some domain knowledge can lead to explanations that better agree with human intuition. This is especially favorable for a real-world robotics task, where there is considerable causality at play, and in addition, the required domain knowledge is often handily available.
Robotic Lever Manipulation using Hindsight Experience Replay and Shapley Additive Explanations
Oct 07, 2021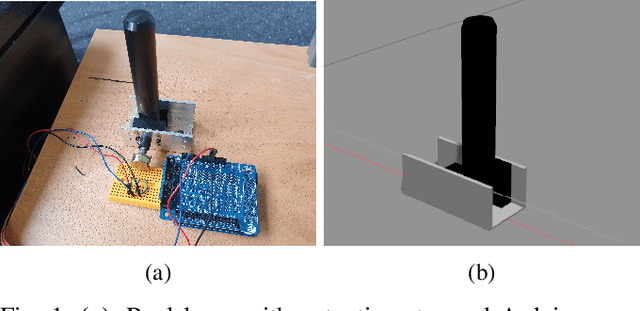

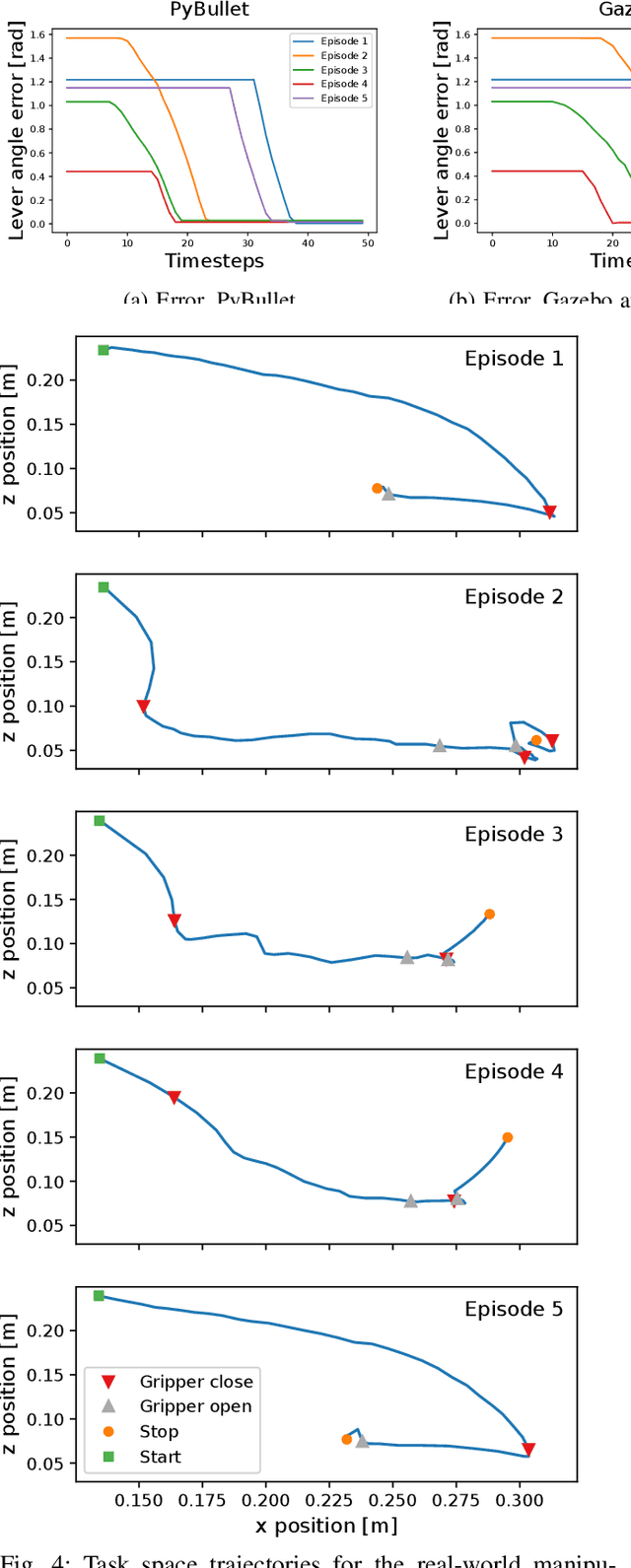

This paper deals with robotic lever control using Explainable Deep Reinforcement Learning. First, we train a policy by using the Deep Deterministic Policy Gradient algorithm and the Hindsight Experience Replay technique, where the goal is to control a robotic manipulator to manipulate a lever. This enables us both to use continuous states and actions and to learn with sparse rewards. Being able to learn from sparse rewards is especially desirable for Deep Reinforcement Learning because designing a reward function for complex tasks such as this is challenging. We first train in the PyBullet simulator, which accelerates the training procedure, but is not accurate on this task compared to the real-world environment. After completing the training in PyBullet, we further train in the Gazebo simulator, which runs more slowly than PyBullet, but is more accurate on this task. We then transfer the policy to the real-world environment, where it achieves comparable performance to the simulated environments for most episodes. To explain the decisions of the policy we use the SHAP method to create an explanation model based on the episodes done in the real-world environment. This gives us some results that agree with intuition, and some that do not. We also question whether the independence assumption made when approximating the SHAP values influences the accuracy of these values for a system such as this, where there are some correlations between the states.
Warm-Started Optimized Trajectory Planning for ASVs
Jul 05, 2019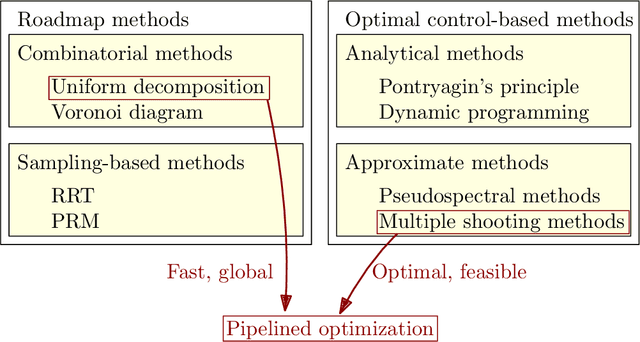
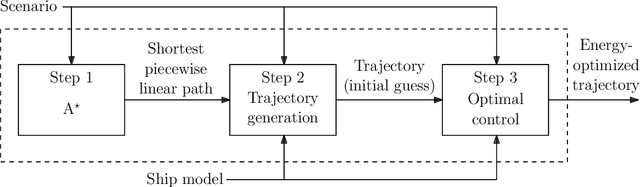
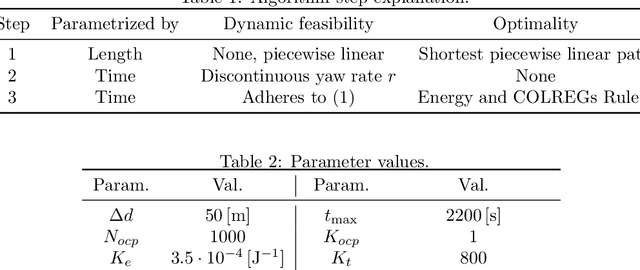
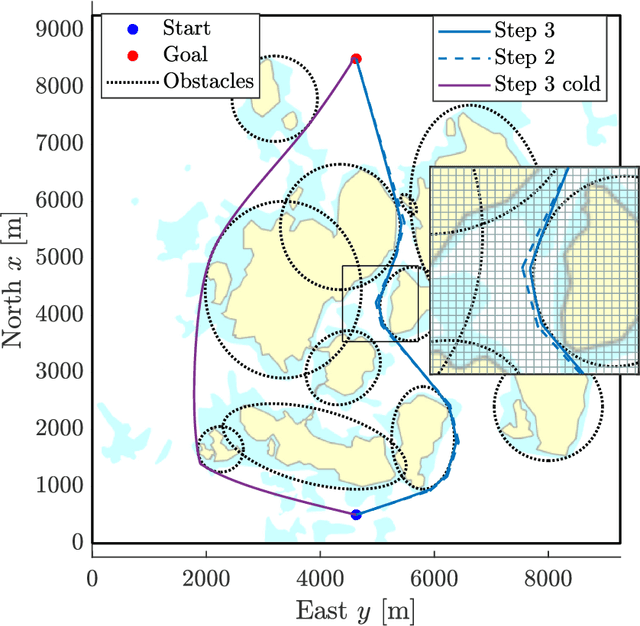
We consider warm-started optimized trajectory planning for autonomous surface vehicles (ASVs) by combining the advantages of two types of planners: an A* implementation that quickly finds the shortest piecewise linear path, and an optimal control-based trajectory planner. A nonlinear 3-degree-of-freedom underactuated model of an ASV is considered, along with an objective functional that promotes energy-efficient and readily observable maneuvers. The A* algorithm is guaranteed to find the shortest piecewise linear path to the goal position based on a uniformly decomposed map. Dynamic information is constructed and added to the A*-generated path, and provides an initial guess for warm starting the optimal control-based planner. The run time for the optimal control planner is greatly reduced by this initial guess and outputs a dynamically feasible and locally optimal trajectory.