 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Meaning at Scale: Evaluating Semantic Search for 18th-Century Intellectual History through the Case of Locke
May 10, 2026While digitized corpora have transformed the study of intellectual transmission, current methods rely heavily on lexical text reuse detection, capturing verbatim quotations but fundamentally missing paraphrases and complex implicit engagement. This paper evaluates semantic search in 18th-century intellectual history through the reception of John Locke's foundational work. Using expert annotation grounded in a semantic taxonomy, we examine whether an off-the-shelf semantic search pipeline can surface meaning-level correspondences overlooked by lexical methods. Our results demonstrate that semantic search retrieves substantially more implicit receptions than lexical baselines. However, linguistic diagnostics also reveal a "lexical gatekeeping" effect, where retrieval remains partially constrained by surface vocabulary overlap. These findings highlight both the potential and the limitations of semantic retrieval for analyzing the circulation of ideas in large historical corpora. The data is available at https://github.com/COMHIS/locke-sim-data.
Cost-Effective Retraining of Machine Learning Models
Oct 06, 2023It is important to retrain a machine learning (ML) model in order to maintain its performance as the data changes over time. However, this can be costly as it usually requires processing the entire dataset again. This creates a trade-off between retraining too frequently, which leads to unnecessary computing costs, and not retraining often enough, which results in stale and inaccurate ML models. To address this challenge, we propose ML systems that make automated and cost-effective decisions about when to retrain an ML model. We aim to optimize the trade-off by considering the costs associated with each decision. Our research focuses on determining whether to retrain or keep an existing ML model based on various factors, including the data, the model, and the predictive queries answered by the model. Our main contribution is a Cost-Aware Retraining Algorithm called Cara, which optimizes the trade-off over streams of data and queries. To evaluate the performance of Cara, we analyzed synthetic datasets and demonstrated that Cara can adapt to different data drifts and retraining costs while performing similarly to an optimal retrospective algorithm. We also conducted experiments with real-world datasets and showed that Cara achieves better accuracy than drift detection baselines while making fewer retraining decisions, ultimately resulting in lower total costs.
Reception Reader: Exploring Text Reuse in Early Modern British Publications
Feb 08, 2023The Reception Reader is a web tool for studying text reuse in the Early English Books Online (EEBO-TCP) and Eighteenth Century Collections Online (ECCO) data. Users can: 1) explore a visual overview of the reception of a work, or its incoming connections, across time based on shared text segments, 2) interactively survey the details of connected documents, and 3) examine the context of reused text for "close reading". We show examples of how the tool streamlines research and exploration tasks, and discuss the utility and limitations of the user interface along with its current data sources.
Certifiable Machine Unlearning for Linear Models
Jul 28, 2021
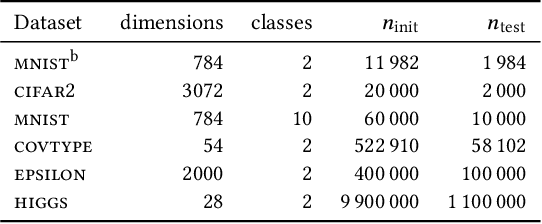

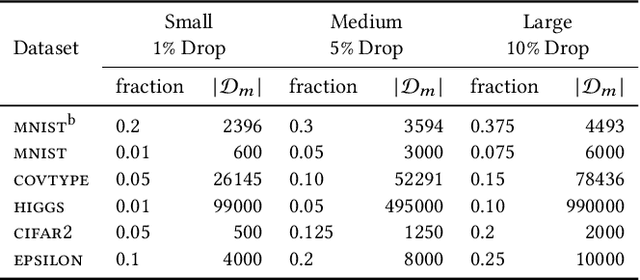
Machine unlearning is the task of updating machine learning (ML) models after a subset of the training data they were trained on is deleted. Methods for the task are desired to combine effectiveness and efficiency, i.e., they should effectively "unlearn" deleted data, but in a way that does not require excessive computation effort (e.g., a full retraining) for a small amount of deletions. Such a combination is typically achieved by tolerating some amount of approximation in the unlearning. In addition, laws and regulations in the spirit of "the right to be forgotten" have given rise to requirements for certifiability, i.e., the ability to demonstrate that the deleted data has indeed been unlearned by the ML model. In this paper, we present an experimental study of the three state-of-the-art approximate unlearning methods for linear models and demonstrate the trade-offs between efficiency, effectiveness and certifiability offered by each method. In implementing the study, we extend some of the existing works and describe a common ML pipeline to compare and evaluate the unlearning methods on six real-world datasets and a variety of settings. We provide insights into the effect of the quantity and distribution of the deleted data on ML models and the performance of each unlearning method in different settings. We also propose a practical online strategy to determine when the accumulated error from approximate unlearning is large enough to warrant a full retrain of the ML model.