 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Patterns in Historical OCR: A Comparative Analysis of TrOCR and a Vision-Language Model
Feb 16, 2026Optical Character Recognition (OCR) of eighteenth-century printed texts remains challenging due to degraded print quality, archaic glyphs, and non-standardized orthography. Although transformer-based OCR systems and Vision-Language Models (VLMs) achieve strong aggregate accuracy, metrics such as Character Error Rate (CER) and Word Error Rate (WER) provide limited insight into their reliability for scholarly use. We compare a dedicated OCR transformer (TrOCR) and a general-purpose Vision-Language Model (Qwen) on line-level historical English texts using length-weighted accuracy metrics and hypothesis driven error analysis. While Qwen achieves lower CER/WER and greater robustness to degraded input, it exhibits selective linguistic regularization and orthographic normalization that may silently alter historically meaningful forms. TrOCR preserves orthographic fidelity more consistently but is more prone to cascading error propagation. Our findings show that architectural inductive biases shape OCR error structure in systematic ways. Models with similar aggregate accuracy can differ substantially in error locality, detectability, and downstream scholarly risk, underscoring the need for architecture-aware evaluation in historical digitization workflows.
Reception Reader: Exploring Text Reuse in Early Modern British Publications
Feb 08, 2023The Reception Reader is a web tool for studying text reuse in the Early English Books Online (EEBO-TCP) and Eighteenth Century Collections Online (ECCO) data. Users can: 1) explore a visual overview of the reception of a work, or its incoming connections, across time based on shared text segments, 2) interactively survey the details of connected documents, and 3) examine the context of reused text for "close reading". We show examples of how the tool streamlines research and exploration tasks, and discuss the utility and limitations of the user interface along with its current data sources.
From Plenipotentiary to Puddingless: Users and Uses of New Words in Early English Letters
Mar 17, 2021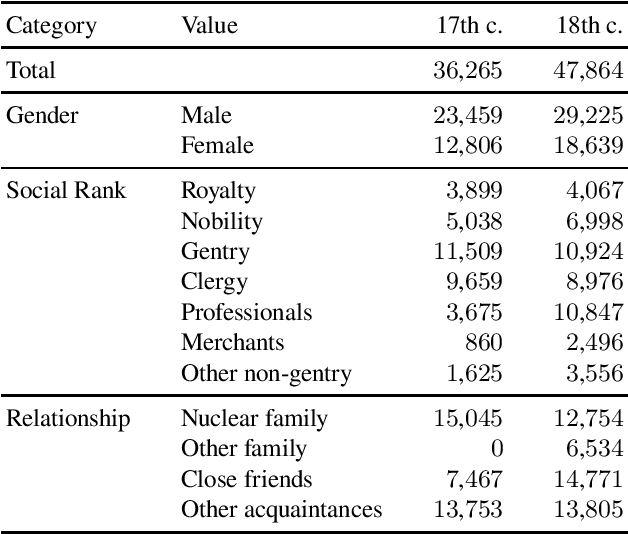

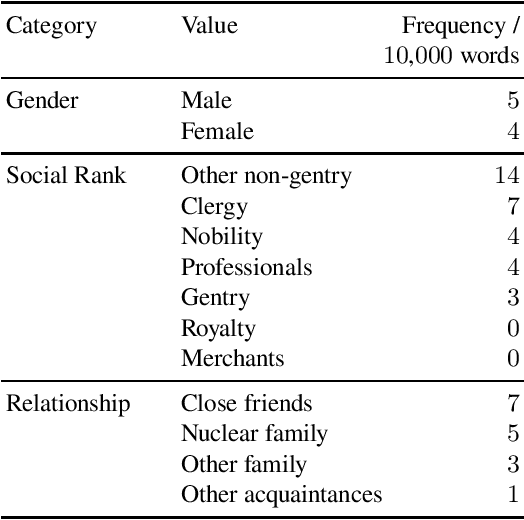
We study neologism use in two samples of early English correspondence, from 1640--1660 and 1760--1780. Of especial interest are the early adopters of new vocabulary, the social groups they represent, and the types and functions of their neologisms. We describe our computer-assisted approach and note the difficulties associated with massive variation in the corpus. Our findings include that while male letter-writers tend to use neologisms more frequently than women, the eighteenth century seems to have provided more opportunities for women and the lower ranks to participate in neologism use as well. In both samples, neologisms most frequently occur in letters written between close friends, which could be due to this less stable relationship triggering more creative language use. In the seventeenth-century sample, we observe the influence of the English Civil War, while the eighteenth-century sample appears to reflect the changing functions of letter-writing, as correspondence is increasingly being used as a tool for building and maintaining social relationships in addition to exchanging information.
Old Content and Modern Tools - Searching Named Entities in a Finnish OCRed Historical Newspaper Collection 1771-1910
Nov 09, 2016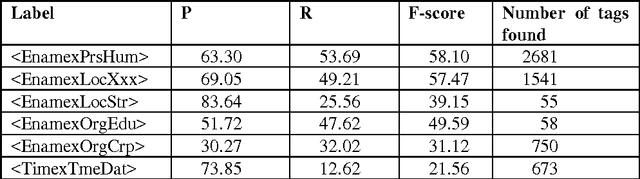
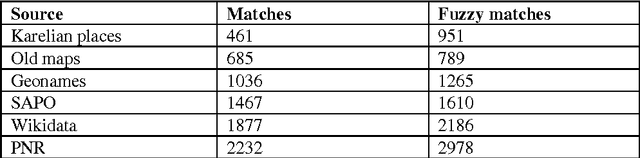

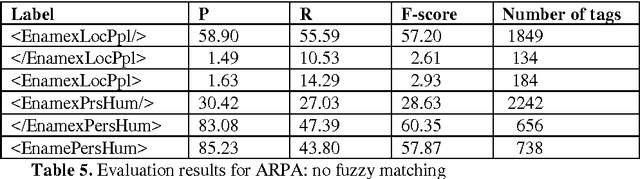
Named Entity Recognition (NER), search, classification and tagging of names and name like frequent informational elements in texts, has become a standard information extraction procedure for textual data. NER has been applied to many types of texts and different types of entities: newspapers, fiction, historical records, persons, locations, chemical compounds, protein families, animals etc. In general a NER system's performance is genre and domain dependent and also used entity categories vary (Nadeau and Sekine, 2007). The most general set of named entities is usually some version of three partite categorization of locations, persons and organizations. In this paper we report first large scale trials and evaluation of NER with data out of a digitized Finnish historical newspaper collection Digi. Experiments, results and discussion of this research serve development of the Web collection of historical Finnish newspapers. Digi collection contains 1,960,921 pages of newspaper material from years 1771-1910 both in Finnish and Swedish. We use only material of Finnish documents in our evaluation. The OCRed newspaper collection has lots of OCR errors; its estimated word level correctness is about 70-75 % (Kettunen and P\"a\"akk\"onen, 2016). Our principal NER tagger is a rule-based tagger of Finnish, FiNER, provided by the FIN-CLARIN consortium. We show also results of limited category semantic tagging with tools of the Semantic Computing Research Group (SeCo) of the Aalto University. Three other tools are also evaluated briefly. This research reports first published large scale results of NER in a historical Finnish OCRed newspaper collection. Results of the research supplement NER results of other languages with similar noisy data.