 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR$\vert$GRADUATE: uncertainty-aware deep learning-based diabetic retinopathy grading in eye fundus images
Oct 25, 2019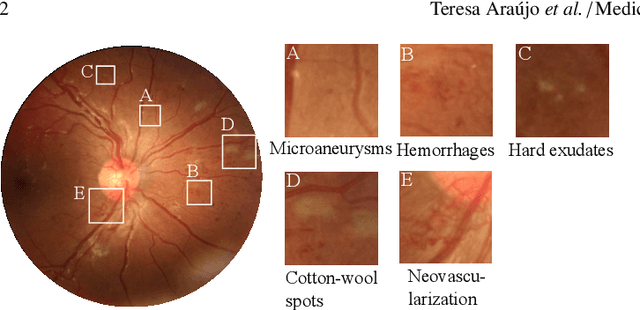
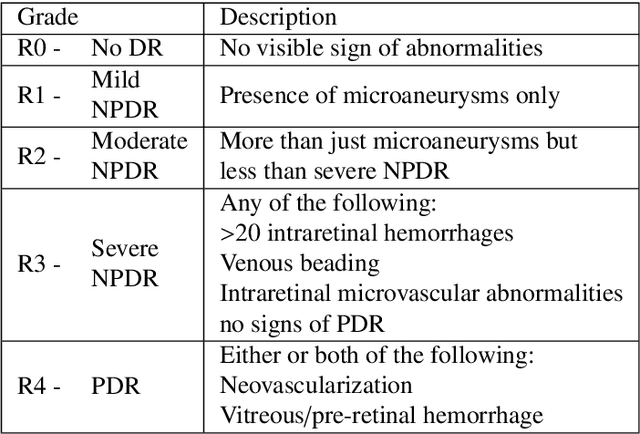
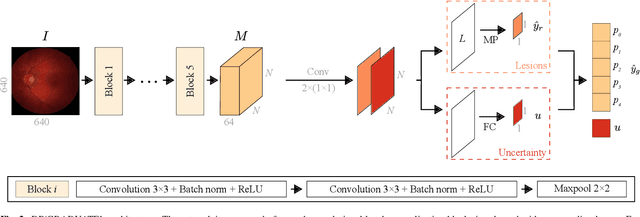

Diabetic retinopathy (DR) grading is crucial in determining the patients' adequate treatment and follow up, but the screening process can be tiresome and prone to errors. Deep learning approaches have shown promising performance as computer-aided diagnosis(CAD) systems, but their black-box behaviour hinders the clinical application. We propose DR$\vert$GRADUATE, a novel deep learning-based DR grading CAD system that supports its decision by providing a medically interpretable explanation and an estimation of how uncertain that prediction is, allowing the ophthalmologist to measure how much that decision should be trusted. We designed DR$\vert$GRADUATE taking into account the ordinal nature of the DR grading problem. A novel Gaussian-sampling approach built upon a Multiple Instance Learning framework allow DR$\vert$GRADUATE to infer an image grade associated with an explanation map and a prediction uncertainty while being trained only with image-wise labels. DR$\vert$GRADUATE was trained on the Kaggle training set and evaluated across multiple datasets. In DR grading, a quadratic-weighted Cohen's kappa (QWK) between 0.71 and 0.84 was achieved in five different datasets. We show that high QWK values occur for images with low prediction uncertainty, thus indicating that this uncertainty is a valid measure of the predictions' quality. Further, bad quality images are generally associated with higher uncertainties, showing that images not suitable for diagnosis indeed lead to less trustworthy predictions. Additionally, tests on unfamiliar medical image data types suggest that DR$\vert$GRADUATE allows outlier detection. The attention maps generally highlight regions of interest for diagnosis. These results show the great potential of DR$\vert$GRADUATE as a second-opinion system in DR severity grading.
UOLO - automatic object detection and segmentation in biomedical images
Oct 09, 2018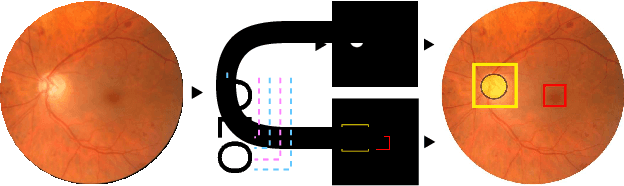
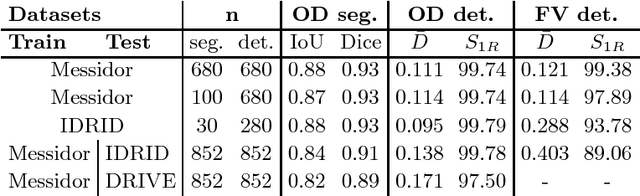
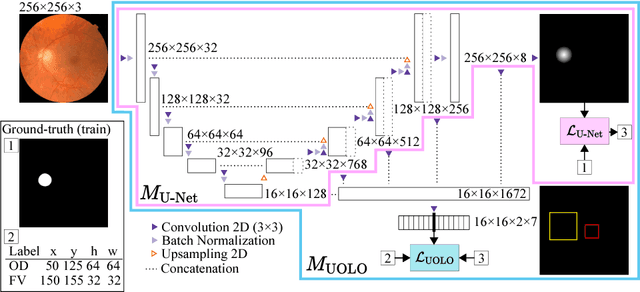
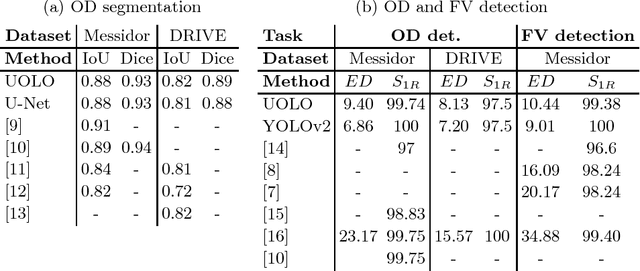
We propose UOLO, a novel framework for the simultaneous detection and segmentation of structures of interest in medical images. UOLO consists of an object segmentation module which intermediate abstract representations are processed and used as input for object detection. The resulting system is optimized simultaneously for detecting a class of objects and segmenting an optionally different class of structures. UOLO is trained on a set of bounding boxes enclosing the objects to detect, as well as pixel-wise segmentation information, when available. A new loss function is devised, taking into account whether a reference segmentation is accessible for each training image, in order to suitably backpropagate the error. We validate UOLO on the task of simultaneous optic disc (OD) detection, fovea detection, and OD segmentation from retinal images, achieving state-of-the-art performance on public datasets.
* Publised on DLMIA 2018. Licensed under the Creative Commons CC-BY-NC-ND 4.0 license: http://creativecommons.org/licenses/by-nc-nd/4.0/
Towards Adversarial Retinal Image Synthesis
Jan 31, 2017
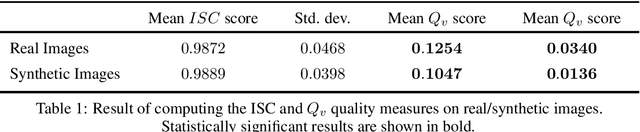


Synthesizing images of the eye fundus is a challenging task that has been previously approached by formulating complex models of the anatomy of the eye. New images can then be generated by sampling a suitable parameter space. In this work, we propose a method that learns to synthesize eye fundus images directly from data. For that, we pair true eye fundus images with their respective vessel trees, by means of a vessel segmentation technique. These pairs are then used to learn a mapping from a binary vessel tree to a new retinal image. For this purpose, we use a recent image-to-image translation technique, based on the idea of adversarial learning. Experimental results show that the original and the generated images are visually different in terms of their global appearance, in spite of sharing the same vessel tree. Additionally, a quantitative quality analysis of the synthetic retinal images confirms that the produced images retain a high proportion of the true image set quality.