 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Jump Is All You Need: Short-Cutting Transformers for Early Exit Prediction with One Jump to Fit All Exit Levels
Apr 18, 2025To reduce the time and computational costs of inference of large language models, there has been interest in parameter-efficient low-rank early-exit casting of transformer hidden-representations to final-representations. Such low-rank short-cutting has been shown to outperform identity shortcuts at early model stages while offering parameter-efficiency in shortcut jumps. However, current low-rank methods maintain a separate early-exit shortcut jump to final-representations for each transformer intermediate block-level during inference. In this work, we propose selection of a single One-Jump-Fits-All (OJFA) low-rank shortcut that offers over a 30x reduction in shortcut parameter costs during inference. We show that despite this extreme reduction, our OJFA choice largely matches the performance of maintaining multiple shortcut jumps during inference and offers stable precision from all transformer block-levels for GPT2-XL, Phi3-Mini and Llama2-7B transformer models.
Normalized Narrow Jump To Conclusions: Normalized Narrow Shortcuts for Parameter Efficient Early Exit Transformer Prediction
Sep 21, 2024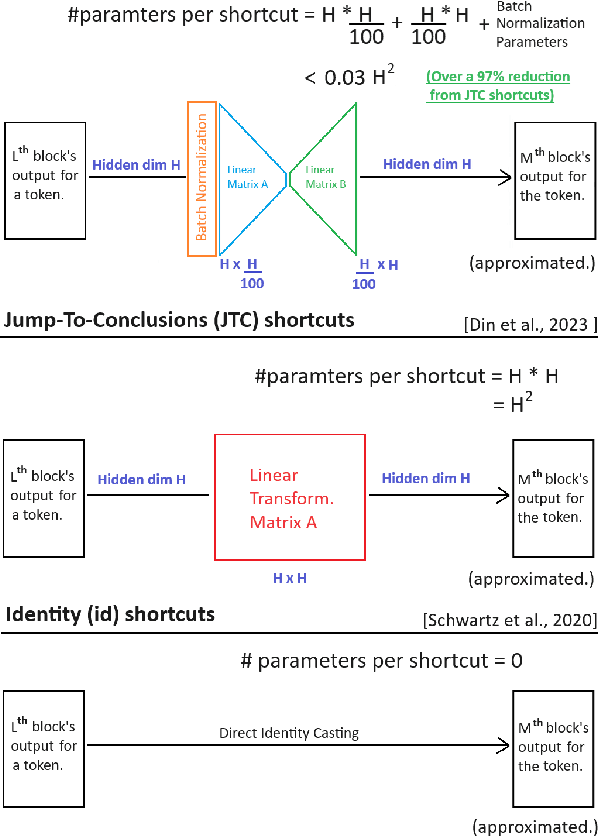
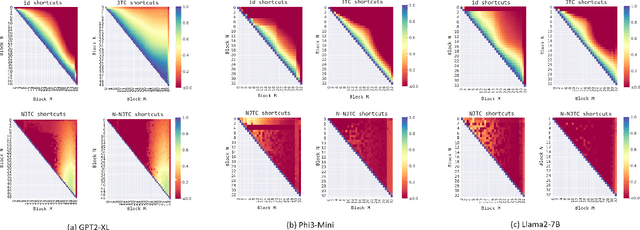
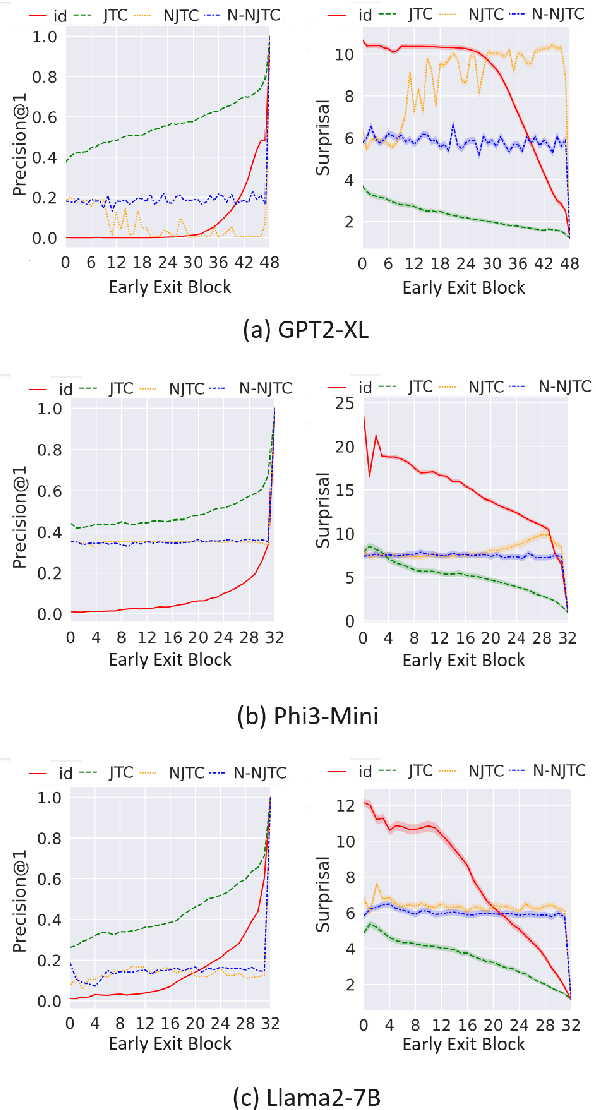
With the size and cost of large transformer-based language models growing, recently, there has been interest in shortcut casting of early transformer hidden-representations to final-representations for cheaper model inference. In particular, shortcutting pre-trained transformers with linear transformations over early layers has been shown to improve precision in early inference. However, for large language models, even this becomes computationally expensive. In this work, we propose Narrow Jump to Conclusions (NJTC) and Normalized Narrow Jump to Conclusions (N-NJTC) - parameter efficient alternatives to standard linear shortcutting that reduces shortcut parameter count by over 97%. We show that N-NJTC reliably outperforms Identity shortcuts at early stages and offers stable precision from all transformer block levels for GPT-2-XL, Phi3-Mini and Llama2-7B transformer models, demonstrating the viability of more parameter efficient short-cutting approaches.
Reasoning over the Behaviour of Objects in Video-Clips for Adverb-Type Recognition
Jul 12, 2023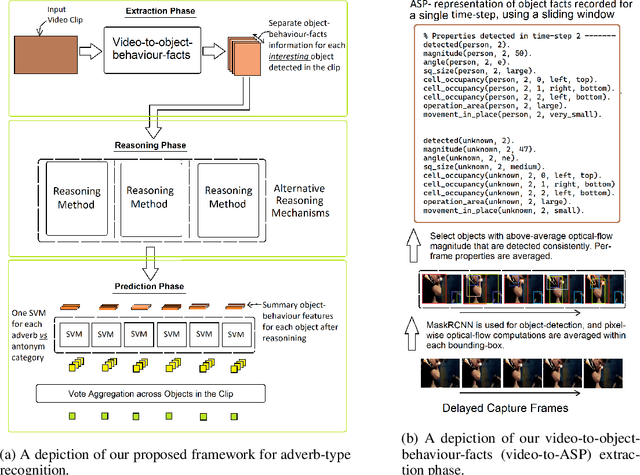
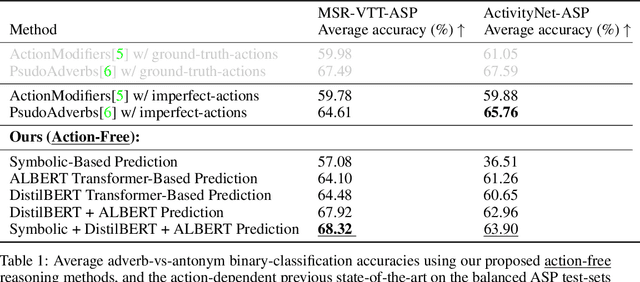


In this work, following the intuition that adverbs describing scene-sequences are best identified by reasoning over high-level concepts of object-behavior, we propose the design of a new framework that reasons over object-behaviours extracted from raw-video-clips to recognize the clip's corresponding adverb-types. Importantly, while previous works for general scene adverb-recognition assume knowledge of the clips underlying action-types, our method is directly applicable in the more general problem setting where the action-type of a video-clip is unknown. Specifically, we propose a novel pipeline that extracts human-interpretable object-behaviour-facts from raw video clips and propose novel symbolic and transformer based reasoning methods that operate over these extracted facts to identify adverb-types. Experiment results demonstrate that our proposed methods perform favourably against the previous state-of-the-art. Additionally, to support efforts in symbolic video-processing, we release two new datasets of object-behaviour-facts extracted from raw video clips - the MSR-VTT-ASP and ActivityNet-ASP datasets.
Multi-Tailed, Multi-Headed, Spatial Dynamic Memory refined Text-to-Image Synthesis
Oct 15, 2021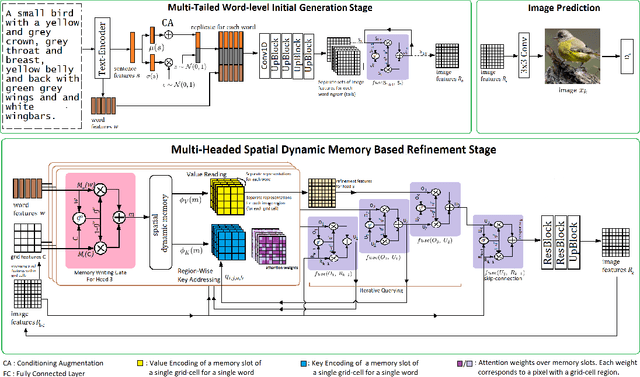


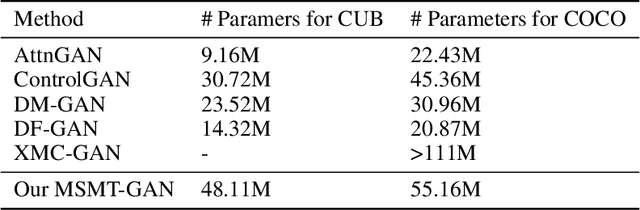
Synthesizing high-quality, realistic images from text-descriptions is a challenging task, and current methods synthesize images from text in a multi-stage manner, typically by first generating a rough initial image and then refining image details at subsequent stages. However, existing methods that follow this paradigm suffer from three important limitations. Firstly, they synthesize initial images without attempting to separate image attributes at a word-level. As a result, object attributes of initial images (that provide a basis for subsequent refinement) are inherently entangled and ambiguous in nature. Secondly, by using common text-representations for all regions, current methods prevent us from interpreting text in fundamentally different ways at different parts of an image. Different image regions are therefore only allowed to assimilate the same type of information from text at each refinement stage. Finally, current methods generate refinement features only once at each refinement stage and attempt to address all image aspects in a single shot. This single-shot refinement limits the precision with which each refinement stage can learn to improve the prior image. Our proposed method introduces three novel components to address these shortcomings: (1) An initial generation stage that explicitly generates separate sets of image features for each word n-gram. (2) A spatial dynamic memory module for refinement of images. (3) An iterative multi-headed mechanism to make it easier to improve upon multiple image aspects. Experimental results demonstrate that our Multi-Headed Spatial Dynamic Memory image refinement with our Multi-Tailed Word-level Initial Generation (MSMT-GAN) performs favourably against the previous state of the art on the CUB and COCO datasets.