 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning over the Behaviour of Objects in Video-Clips for Adverb-Type Recognition
Paper and Code
Jul 12, 2023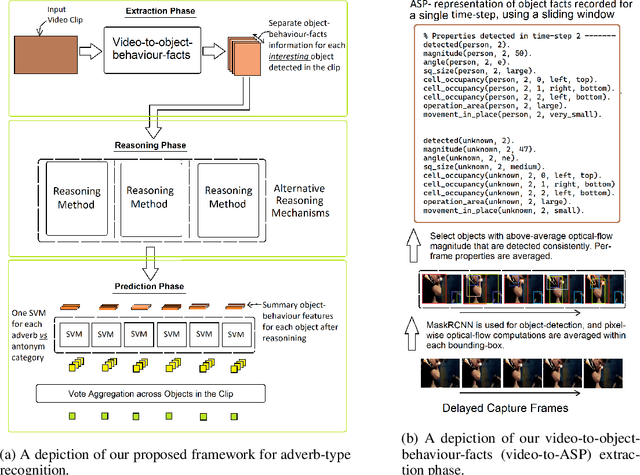
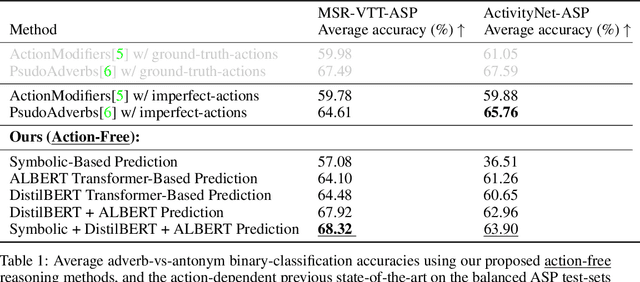


In this work, following the intuition that adverbs describing scene-sequences are best identified by reasoning over high-level concepts of object-behavior, we propose the design of a new framework that reasons over object-behaviours extracted from raw-video-clips to recognize the clip's corresponding adverb-types. Importantly, while previous works for general scene adverb-recognition assume knowledge of the clips underlying action-types, our method is directly applicable in the more general problem setting where the action-type of a video-clip is unknown. Specifically, we propose a novel pipeline that extracts human-interpretable object-behaviour-facts from raw video clips and propose novel symbolic and transformer based reasoning methods that operate over these extracted facts to identify adverb-types. Experiment results demonstrate that our proposed methods perform favourably against the previous state-of-the-art. Additionally, to support efforts in symbolic video-processing, we release two new datasets of object-behaviour-facts extracted from raw video clips - the MSR-VTT-ASP and ActivityNet-ASP datasets.