 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Image Restoration for Video Surveillance: A Real-Time Approach
May 19, 2025One of the major challenges in the field of computer vision especially for detection, segmentation, recognition, monitoring, and automated solutions, is the quality of images. Image degradation, often caused by factors such as rain, fog, lighting, etc., has a negative impact on automated decision-making.Furthermore, several image restoration solutions exist, including restoration models for single degradation and restoration models for multiple degradations. However, these solutions are not suitable for real-time processing. In this study, the aim was to develop a real-time image restoration solution for video surveillance. To achieve this, using transfer learning with ResNet_50, we developed a model for automatically identifying the types of degradation present in an image to reference the necessary treatment(s) for image restoration. Our solution has the advantage of being flexible and scalable.
Centroid Decision Forest
Mar 25, 2025This paper introduces the centroid decision forest (CDF), a novel ensemble learning framework that redefines the splitting strategy and tree building in the ordinary decision trees for high-dimensional classification. The splitting approach in CDF differs from the traditional decision trees in theat the class separability score (CSS) determines the selection of the most discriminative features at each node to construct centroids of the partitions (daughter nodes). The splitting criterion uses the Euclidean distance measurements from each class centroid to achieve a splitting mechanism that is more flexible and robust. Centroids are constructed by computing the mean feature values of the selected features for each class, ensuring a class-representative division of the feature space. This centroid-driven approach enables CDF to capture complex class structures while maintaining interpretability and scalability. To evaluate CDF, 23 high-dimensional datasets are used to assess its performance against different state-of-the-art classifiers through classification accuracy and Cohen's kappa statistic. The experimental results show that CDF outperforms the conventional methods establishing its effectiveness and flexibility for high-dimensional classification problems.
Feature Selection via Robust Weighted Score for High Dimensional Binary Class-Imbalanced Gene Expression Data
Jan 23, 2024In this paper, a robust weighted score for unbalanced data (ROWSU) is proposed for selecting the most discriminative feature for high dimensional gene expression binary classification with class-imbalance problem. The method addresses one of the most challenging problems of highly skewed class distributions in gene expression datasets that adversely affect the performance of classification algorithms. First, the training dataset is balanced by synthetically generating data points from minority class observations. Second, a minimum subset of genes is selected using a greedy search approach. Third, a novel weighted robust score, where the weights are computed by support vectors, is introduced to obtain a refined set of genes. The highest-scoring genes based on this approach are combined with the minimum subset of genes selected by the greedy search approach to form the final set of genes. The novel method ensures the selection of the most discriminative genes, even in the presence of skewed class distribution, thus improving the performance of the classifiers. The performance of the proposed ROWSU method is evaluated on $6$ gene expression datasets. Classification accuracy and sensitivity are used as performance metrics to compare the proposed ROWSU algorithm with several other state-of-the-art methods. Boxplots and stability plots are also constructed for a better understanding of the results. The results show that the proposed method outperforms the existing feature selection procedures based on classification performance from k nearest neighbours (kNN) and random forest (RF) classifiers.
A Random Projection k Nearest Neighbours Ensemble for Classification via Extended Neighbourhood Rule
Mar 21, 2023Ensembles based on k nearest neighbours (kNN) combine a large number of base learners, each constructed on a sample taken from a given training data. Typical kNN based ensembles determine the k closest observations in the training data bounded to a test sample point by a spherical region to predict its class. In this paper, a novel random projection extended neighbourhood rule (RPExNRule) ensemble is proposed where bootstrap samples from the given training data are randomly projected into lower dimensions for additional randomness in the base models and to preserve features information. It uses the extended neighbourhood rule (ExNRule) to fit kNN as base learners on randomly projected bootstrap samples.
An Optimal k Nearest Neighbours Ensemble for Classification Based on Extended Neighbourhood Rule with Features subspace
Nov 21, 2022To minimize the effect of outliers, kNN ensembles identify a set of closest observations to a new sample point to estimate its unknown class by using majority voting in the labels of the training instances in the neighbourhood. Ordinary kNN based procedures determine k closest training observations in the neighbourhood region (enclosed by a sphere) by using a distance formula. The k nearest neighbours procedure may not work in a situation where sample points in the test data follow the pattern of the nearest observations that lie on a certain path not contained in the given sphere of nearest neighbours. Furthermore, these methods combine hundreds of base kNN learners and many of them might have high classification errors thereby resulting in poor ensembles. To overcome these problems, an optimal extended neighbourhood rule based ensemble is proposed where the neighbours are determined in k steps. It starts from the first nearest sample point to the unseen observation. The second nearest data point is identified that is closest to the previously selected data point. This process is continued until the required number of the k observations are obtained. Each base model in the ensemble is constructed on a bootstrap sample in conjunction with a random subset of features. After building a sufficiently large number of base models, the optimal models are then selected based on their performance on out-of-bag (OOB) data.
A k nearest neighbours classifiers ensemble based on extended neighbourhood rule and features subsets
May 30, 2022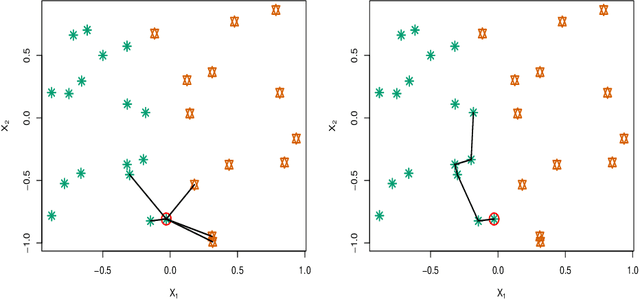
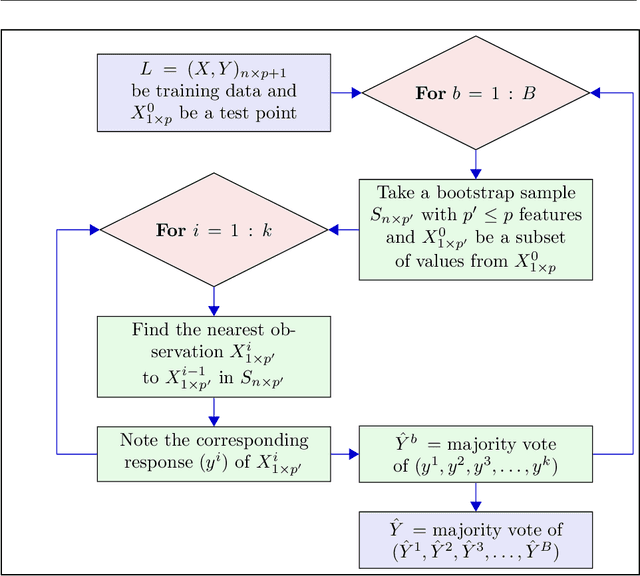

kNN based ensemble methods minimise the effect of outliers by identifying a set of data points in the given feature space that are nearest to an unseen observation in order to predict its response by using majority voting. The ordinary ensembles based on kNN find out the k nearest observations in a region (bounded by a sphere) based on a predefined value of k. This scenario, however, might not work in situations when the test observation follows the pattern of the closest data points with the same class that lie on a certain path not contained in the given sphere. This paper proposes a k nearest neighbour ensemble where the neighbours are determined in k steps. Starting from the first nearest observation of the test point, the algorithm identifies a single observation that is closest to the observation at the previous step. At each base learner in the ensemble, this search is extended to k steps on a random bootstrap sample with a random subset of features selected from the feature space. The final predicted class of the test point is determined by using a majority vote in the predicted classes given by all base models. This new ensemble method is applied on 17 benchmark datasets and compared with other classical methods, including kNN based models, in terms of classification accuracy, kappa and Brier score as performance metrics. Boxplots are also utilised to illustrate the difference in the results given by the proposed and other state-of-the-art methods. The proposed method outperformed the rest of the classical methods in the majority of cases. The paper gives a detailed simulation study for further assessment.
Statistical Descriptors-based Automatic Fingerprint Identification: Machine Learning Approaches
Jul 18, 2019
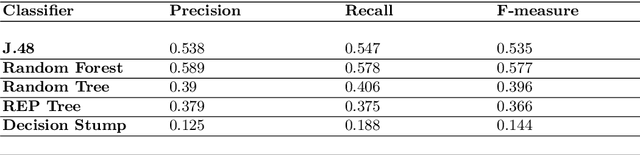

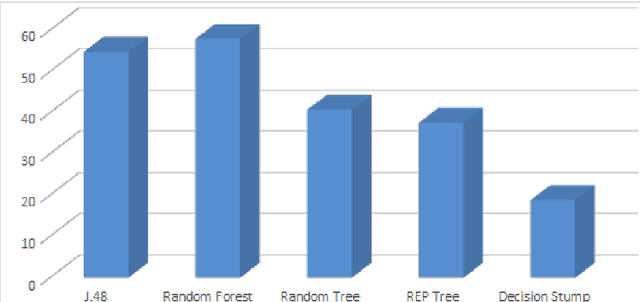
Identification of a person from fingerprints of good quality has been used by commercial applications and law enforcement agencies for many years, however identification of a person from latent fingerprints is very difficult and challenging. A latent fingerprint is a fingerprint left on a surface by deposits of oils and/or perspiration from the finger. It is not usually visible to the naked eye but may be detected with special techniques such as dusting with fine powder and then lifting the pattern of powder with transparent tape. We have evaluated the quality of machine learning techniques that has been implemented in automatic fingerprint identification. In this paper, we use fingerprints of low quality from database DB1 of Fingerprint Verification Competition (FVC 2002) to conduct our experiments. Fingerprints are processed to find its core point using Poincare index and carry out enhancement using Diffusion coherence filter whose performance is known to be good in the high curvature regions of fingerprints. Grey-level Co-Occurrence Matrix (GLCM) based seven statistical descriptors with four different inter pixel distances are then extracted as features and put forward to train and test REPTree, RandomTree, J48, Decision Stump and Random Forest Machine Learning techniques for personal identification. Experiments are conducted on 80 instances and 28 attributes. Our experiments proved that Random Forests and J48 give good results for latent fingerprints as compared to other machine learning techniques and can help improve the identification accuracy.