 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabular Data: Deep Learning is Not All You Need
Jun 06, 2021
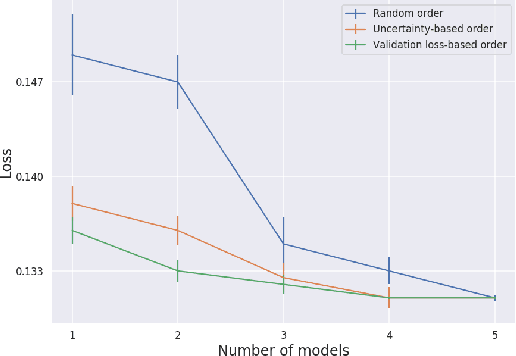
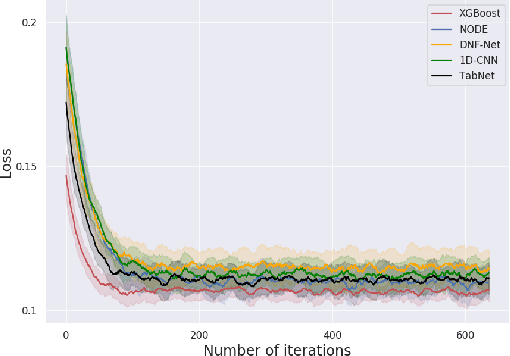

A key element of AutoML systems is setting the types of models that will be used for each type of task. For classification and regression problems with tabular data, the use of tree ensemble models (like XGBoost) is usually recommended. However, several deep learning models for tabular data have recently been proposed, claiming to outperform XGBoost for some use-cases. In this paper, we explore whether these deep models should be a recommended option for tabular data, by rigorously comparing the new deep models to XGBoost on a variety of datasets. In addition to systematically comparing their accuracy, we consider the tuning and computation they require. Our study shows that XGBoost outperforms these deep models across the datasets, including datasets used in the papers that proposed the deep models. We also demonstrate that XGBoost requires much less tuning. On the positive side, we show that an ensemble of the deep models and XGBoost performs better on these datasets than XGBoost alone.
Spatial-Temporal Convolutional Network for Spread Prediction of COVID-19
Dec 27, 2020
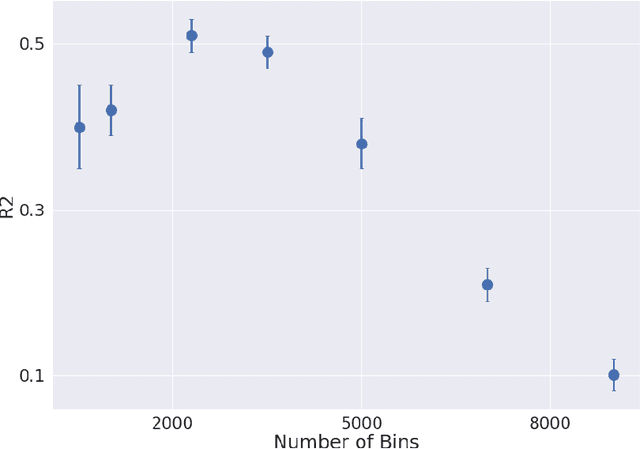
In this work we present a spatial-temporal convolutional neural network for predicting future COVID-19 related symptoms severity among a population, per region, given its past reported symptoms. This can help approximate the number of future Covid-19 patients in each region, thus enabling a faster response, e.g., preparing the local hospital or declaring a local lockdown where necessary. Our model is based on a national symptom survey distributed in Israel and can predict symptoms severity for different regions daily. The model includes two main parts - (1) learned region-based survey responders profiles used for aggregating questionnaires data into features (2) Spatial-Temporal 3D convolutional neural network which uses the above features to predict symptoms progression.
A Weak Supervision Approach to Detecting Visual Anomalies for Automated Testing of Graphics Units
Dec 09, 2019

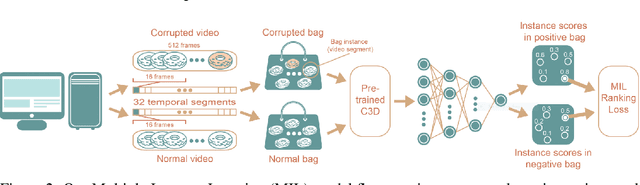
We present a deep learning system for testing graphics units by detecting novel visual corruptions in videos. Unlike previous work in which manual tagging was required to collect labeled training data, our weak supervision method is fully automatic and needs no human labelling. This is achieved by reproducing driver bugs that increase the probability of generating corruptions, and by making use of ideas and methods from the Multiple Instance Learning (MIL) setting. In our experiments, we significantly outperform unsupervised methods such as GAN-based models and discover novel corruptions undetected by baselines, while adhering to strict requirements on accuracy and efficiency of our real-time system.