 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADE: Random Add-Drop Edge as a Regularizer
May 30, 2026Graph Neural Networks (GNNs) suffer from overfitting and over-squashing of long-range information. Stochastic graph augmentations (e.g., edge deletion) regularize training against overfitting but can introduce train-inference misalignment and do not improve over-squashing. In contrast, rewiring methods improve connectivity to mitigate over-squashing, but are not designed to regularize training. We propose Random Add-Drop Edge (RADE), a stochastic graph augmentation method that jointly drops and adds edges to address both overfitting and over-squashing simultaneously. RADE is provably designed to align training and inference so that random augmentations regularize training without distribution shift, while supporting long-range communication at inference. We further propose and study a mini-batch gradient-norm balancing algorithm that adapts deletion and addition rates during training, rendering RADE hyperparameter-free in practice. Experiments on node- and graph-classification benchmarks show that RADE is a strong regularizer and mitigates over-squashing. Ablations support the roles of train-inference alignment, adaptive rate selection, and the complementary effects of random edge deletion and edge addition.
Scalable Expressiveness through Preprocessed Graph Perturbations
Jun 17, 2024Graph Neural Networks (GNNs) have emerged as the predominant method for analyzing graph-structured data. However, canonical GNNs have limited expressive power and generalization capability, thus triggering the development of more expressive yet computationally intensive methods. One such approach is to create a series of perturbed versions of input graphs and then repeatedly conduct multiple message-passing operations on all variations during training. Despite their expressive power, this approach does not scale well on larger graphs. To address this scalability issue, we introduce Scalable Expressiveness through Preprocessed Graph Perturbation (SE2P). This model offers a flexible, configurable balance between scalability and generalizability with four distinct configuration classes. At one extreme, the configuration prioritizes scalability through minimal learnable feature extraction and extensive preprocessing; at the other extreme, it enhances generalizability with more learnable feature extractions, though this increases scalability costs. We conduct extensive experiments on real-world datasets to evaluate the generalizability and scalability of SE2P variants compared to various state-of-the-art benchmarks. Our results indicate that, depending on the chosen SE2P configuration, the model can enhance generalizability compared to benchmarks while achieving significant speed improvements of up to 8-fold.
Stochastic Subgraph Neighborhood Pooling for Subgraph Classification
Apr 17, 2023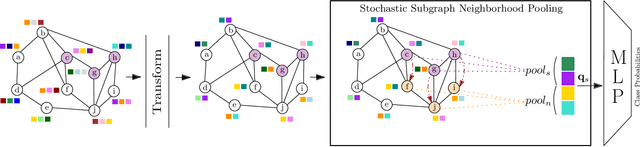
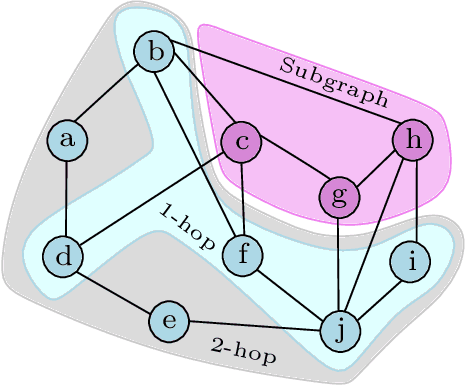
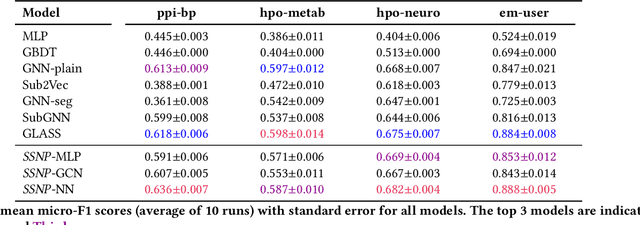
Subgraph classification is an emerging field in graph representation learning where the task is to classify a group of nodes (i.e., a subgraph) within a graph. Subgraph classification has applications such as predicting the cellular function of a group of proteins or identifying rare diseases given a collection of phenotypes. Graph neural networks (GNNs) are the de facto solution for node, link, and graph-level tasks but fail to perform well on subgraph classification tasks. Even GNNs tailored for graph classification are not directly transferable to subgraph classification as they ignore the external topology of the subgraph, thus failing to capture how the subgraph is located within the larger graph. The current state-of-the-art models for subgraph classification address this shortcoming through either labeling tricks or multiple message-passing channels, both of which impose a computation burden and are not scalable to large graphs. To address the scalability issue while maintaining generalization, we propose Stochastic Subgraph Neighborhood Pooling (SSNP), which jointly aggregates the subgraph and its neighborhood (i.e., external topology) information without any computationally expensive operations such as labeling tricks. To improve scalability and generalization further, we also propose a simple data augmentation pre-processing step for SSNP that creates multiple sparse views of the subgraph neighborhood. We show that our model is more expressive than GNNs without labeling tricks. Our extensive experiments demonstrate that our models outperform current state-of-the-art methods (with a margin of up to 2%) while being up to 3X faster in training.
Simplifying Subgraph Representation Learning for Scalable Link Prediction
Jan 29, 2023Link prediction on graphs is a fundamental problem in graph representation learning. Subgraph representation learning approaches (SGRLs), by transforming link prediction to graph classification on the subgraphs around the target links, have advanced the learning capability of Graph Neural Networks (GNNs) for link prediction. Despite their state-of-the-art performance, SGRLs are computationally expensive, and not scalable to large-scale graphs due to their expensive subgraph-level operations for each target link. To unlock the scalability of SGRLs, we propose a new class of SGRLs, that we call Scalable Simplified SGRL (S3GRL). Aimed at faster training and inference, S3GRL simplifies the message passing and aggregation operations in each link's subgraph. S3GRL, as a scalability framework, flexibly accommodates various subgraph sampling strategies and diffusion operators to emulate computationally-expensive SGRLs. We further propose and empirically study multiple instances of S3GRL. Our extensive experiments demonstrate that the proposed S3GRL models scale up SGRLs without any significant performance compromise (even with considerable gains in some cases), while offering substantially lower computational footprints (e.g., multi-fold inference and training speedup).
Sampling Enclosing Subgraphs for Link Prediction
Jun 23, 2022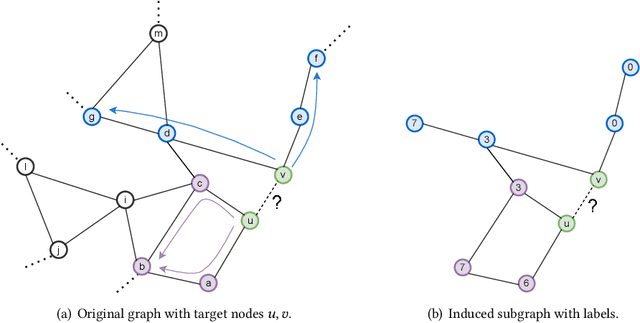
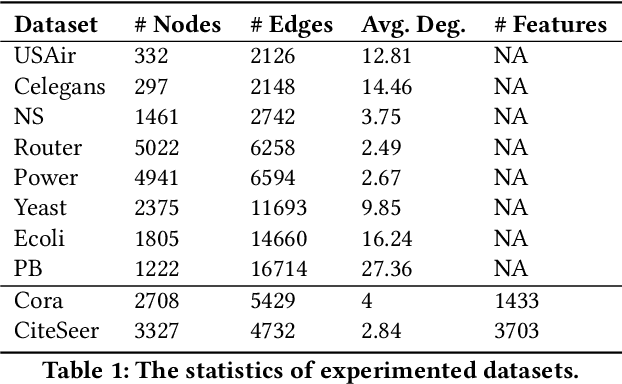
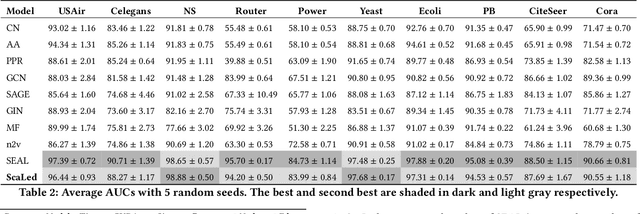
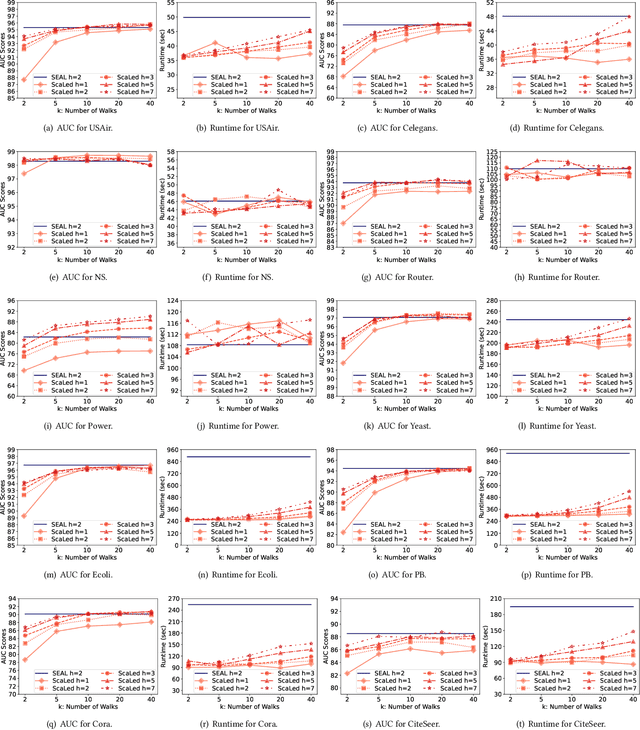
Link prediction is a fundamental problem for graph-structured data (e.g., social networks, drug side-effect networks, etc.). Graph neural networks have offered robust solutions for this problem, specifically by learning the representation of the subgraph enclosing the target link (i.e., pair of nodes). However, these solutions do not scale well to large graphs as extraction and operation on enclosing subgraphs are computationally expensive, especially for large graphs. This paper presents a scalable link prediction solution, that we call ScaLed, which utilizes sparse enclosing subgraphs to make predictions. To extract sparse enclosing subgraphs, ScaLed takes multiple random walks from a target pair of nodes, then operates on the sampled enclosing subgraph induced by all visited nodes. By leveraging the smaller sampled enclosing subgraph, ScaLed can scale to larger graphs with much less overhead while maintaining high accuracy. ScaLed further provides the flexibility to control the trade-off between computation overhead and accuracy. Through comprehensive experiments, we have shown that ScaLed can produce comparable accuracy to those reported by the existing subgraph representation learning frameworks while being less computationally demanding.
Improving Peer Assessment with Graph Convolutional Networks
Nov 04, 2021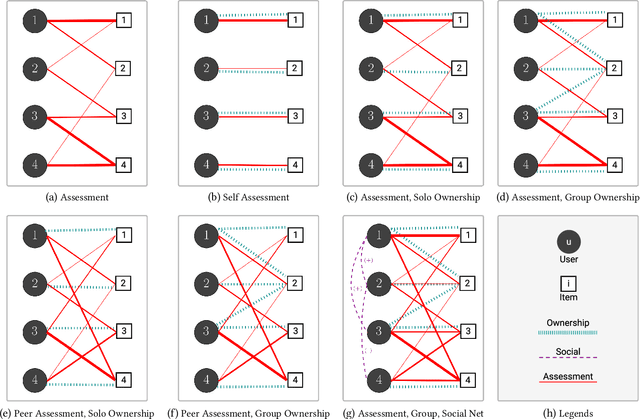
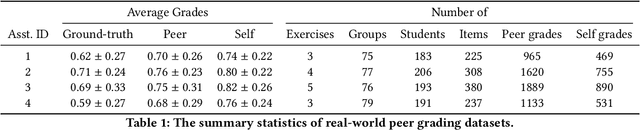
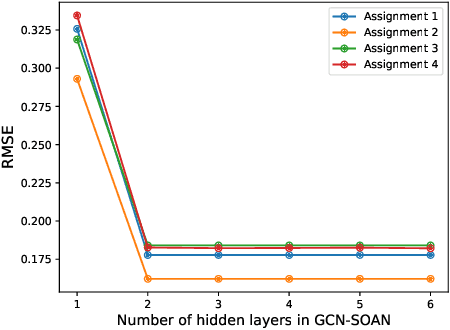
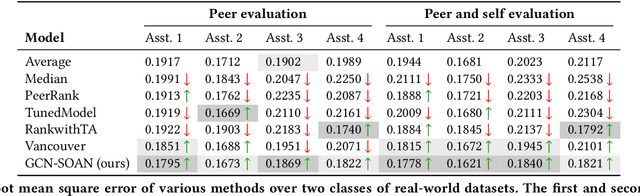
Peer assessment systems are emerging in many social and multi-agent settings, such as peer grading in large (online) classes, peer review in conferences, peer art evaluation, etc. However, peer assessments might not be as accurate as expert evaluations, thus rendering these systems unreliable. The reliability of peer assessment systems is influenced by various factors such as assessment ability of peers, their strategic assessment behaviors, and the peer assessment setup (e.g., peer evaluating group work or individual work of others). In this work, we first model peer assessment as multi-relational weighted networks that can express a variety of peer assessment setups, plus capture conflicts of interest and strategic behaviors. Leveraging our peer assessment network model, we introduce a graph convolutional network which can learn assessment patterns and user behaviors to more accurately predict expert evaluations. Our extensive experiments on real and synthetic datasets demonstrate the efficacy of our proposed approach, which outperforms existing peer assessment methods.
DeepGroup: Representation Learning for Group Recommendation with Implicit Feedback
Mar 13, 2021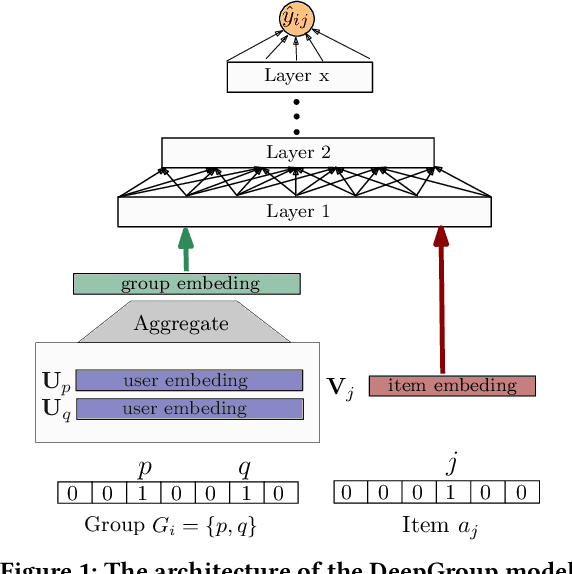
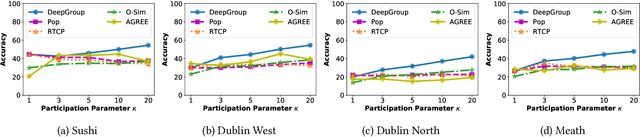


Group recommender systems facilitate group decision making for a set of individuals (e.g., a group of friends, a team, a corporation, etc.). Many of these systems, however, either assume that (i) user preferences can be elicited (or inferred) and then aggregated into group preferences or (ii) group preferences are partially observed/elicited. We focus on making recommendations for a new group of users whose preferences are unknown, but we are given the decisions/choices of other groups. By formulating this problem as group recommendation from group implicit feedback, we focus on two of its practical instances: group decision prediction and reverse social choice. Given a set of groups and their observed decisions, group decision prediction intends to predict the decision of a new group of users, whereas reverse social choice aims to infer the preferences of those users involved in observed group decisions. These two problems are of interest to not only group recommendation, but also to personal privacy when the users intend to conceal their personal preferences but have participated in group decisions. To tackle these two problems, we propose and study DeepGroup -- a deep learning approach for group recommendation with group implicit data. We empirically assess the predictive power of DeepGroup on various real-world datasets, group conditions (e.g., homophily or heterophily), and group decision (or voting) rules. Our extensive experiments not only demonstrate the efficacy of DeepGroup, but also shed light on the privacy-leakage concerns of some decision making processes.
Distilling Knowledge via Intermediate Classifier Heads
Feb 28, 2021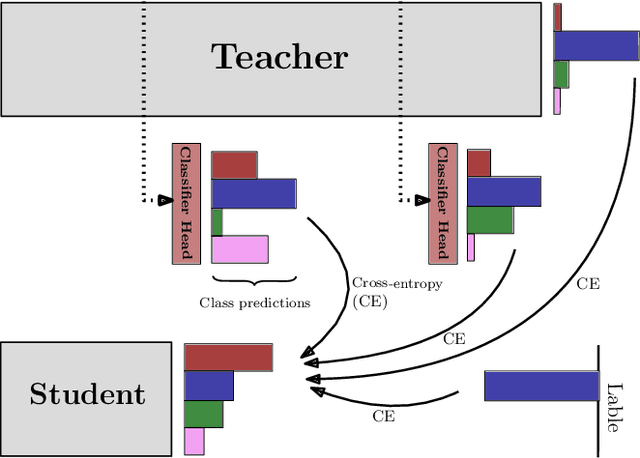


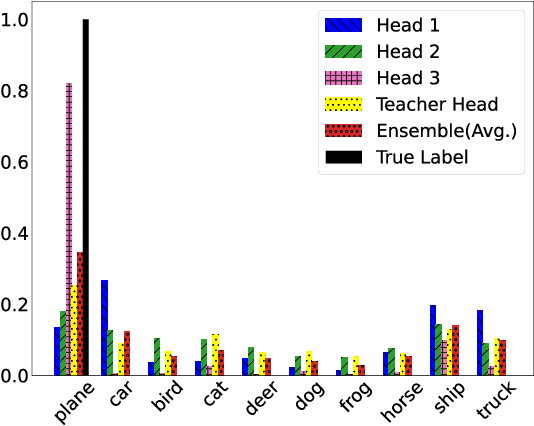
The crux of knowledge distillation -- as a transfer-learning approach -- is to effectively train a resource-limited student model with the guide of a pre-trained larger teacher model. However, when there is a large difference between the model complexities of teacher and student (i.e., capacity gap), knowledge distillation loses its strength in transferring knowledge from the teacher to the student, thus training a weaker student. To mitigate the impact of the capacity gap, we introduce knowledge distillation via intermediate heads. By extending the intermediate layers of the teacher (at various depths) with classifier heads, we cheaply acquire a cohort of heterogeneous pre-trained teachers. The intermediate classifier heads can all together be efficiently learned while freezing the backbone of the pre-trained teacher. The cohort of teachers (including the original teacher) co-teach the student simultaneously. Our experiments on various teacher-student pairs and datasets have demonstrated that the proposed approach outperforms the canonical knowledge distillation approach and its extensions.
Joint Variational Autoencoders for Recommendation with Implicit Feedback
Aug 17, 2020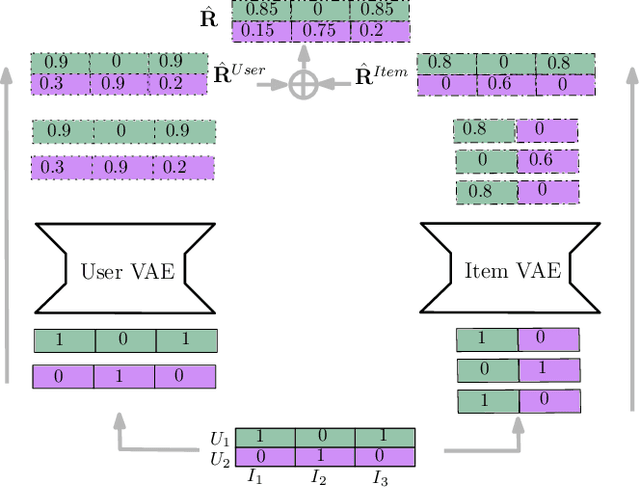
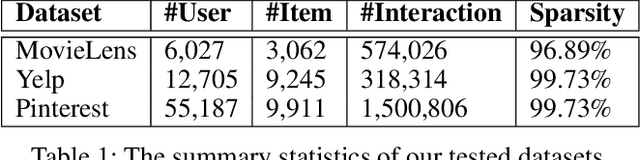

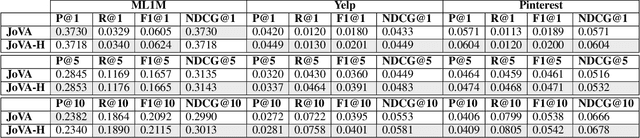
Variational Autoencoders (VAEs) have recently shown promising performance in collaborative filtering with implicit feedback. These existing recommendation models learn user representations to reconstruct or predict user preferences. We introduce joint variational autoencoders (JoVA), an ensemble of two VAEs, in which VAEs jointly learn both user and item representations and collectively reconstruct and predict user preferences. This design allows JoVA to capture user-user and item-item correlations simultaneously. By extending the objective function of JoVA with a hinge-based pairwise loss function (JoVA-Hinge), we further specialize it for top-k recommendation with implicit feedback. Our extensive experiments on several real-world datasets show that JoVA-Hinge outperforms a broad set of state-of-the-art collaborative filtering methods, under a variety of commonly-used metrics. Our empirical results also confirm the outperformance of JoVA-Hinge over existing methods for cold-start users with a limited number of training data.