 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Knowledge via Intermediate Classifier Heads
Paper and Code
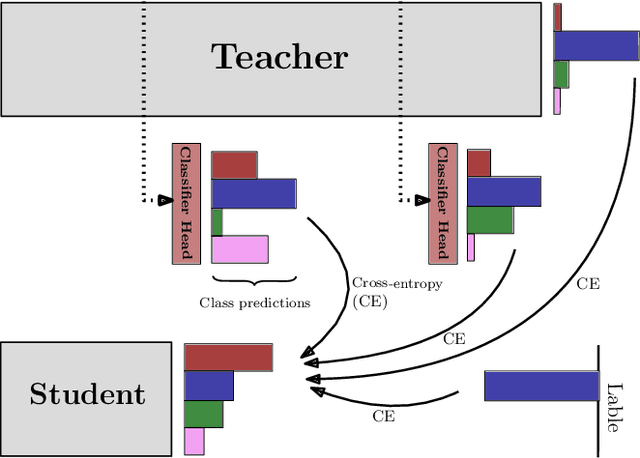


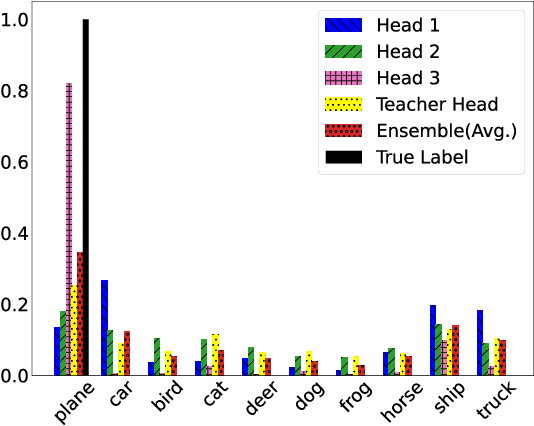
The crux of knowledge distillation -- as a transfer-learning approach -- is to effectively train a resource-limited student model with the guide of a pre-trained larger teacher model. However, when there is a large difference between the model complexities of teacher and student (i.e., capacity gap), knowledge distillation loses its strength in transferring knowledge from the teacher to the student, thus training a weaker student. To mitigate the impact of the capacity gap, we introduce knowledge distillation via intermediate heads. By extending the intermediate layers of the teacher (at various depths) with classifier heads, we cheaply acquire a cohort of heterogeneous pre-trained teachers. The intermediate classifier heads can all together be efficiently learned while freezing the backbone of the pre-trained teacher. The cohort of teachers (including the original teacher) co-teach the student simultaneously. Our experiments on various teacher-student pairs and datasets have demonstrated that the proposed approach outperforms the canonical knowledge distillation approach and its extensions.