 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Variational Autoencoders for Recommendation with Implicit Feedback
Paper and Code
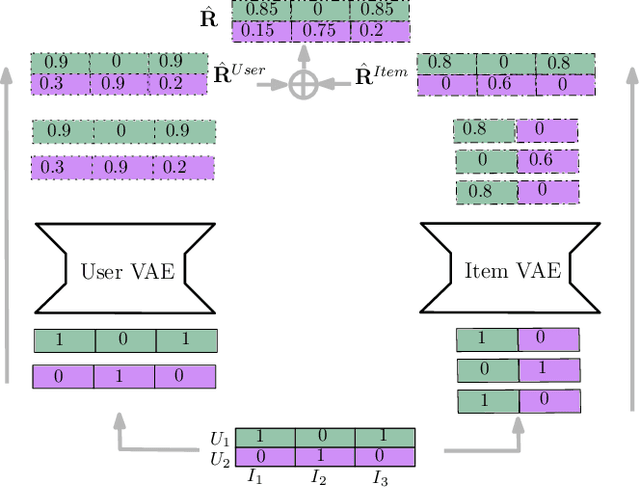
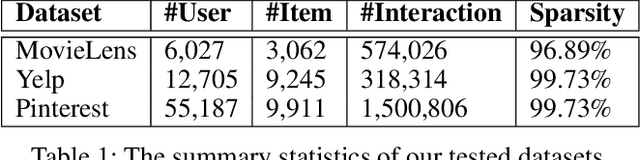

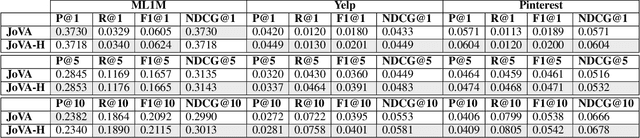
Variational Autoencoders (VAEs) have recently shown promising performance in collaborative filtering with implicit feedback. These existing recommendation models learn user representations to reconstruct or predict user preferences. We introduce joint variational autoencoders (JoVA), an ensemble of two VAEs, in which VAEs jointly learn both user and item representations and collectively reconstruct and predict user preferences. This design allows JoVA to capture user-user and item-item correlations simultaneously. By extending the objective function of JoVA with a hinge-based pairwise loss function (JoVA-Hinge), we further specialize it for top-k recommendation with implicit feedback. Our extensive experiments on several real-world datasets show that JoVA-Hinge outperforms a broad set of state-of-the-art collaborative filtering methods, under a variety of commonly-used metrics. Our empirical results also confirm the outperformance of JoVA-Hinge over existing methods for cold-start users with a limited number of training data.