 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLABR: A Large Scale Arabic Sentiment Analysis Benchmark
May 03, 2015

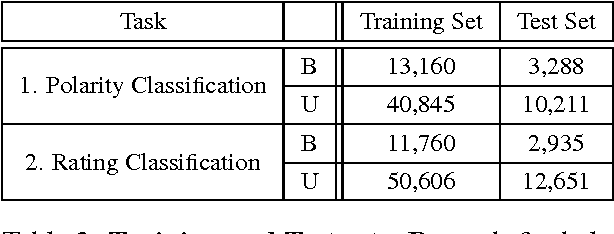

We introduce LABR, the largest sentiment analysis dataset to-date for the Arabic language. It consists of over 63,000 book reviews, each rated on a scale of 1 to 5 stars. We investigate the properties of the dataset, and present its statistics. We explore using the dataset for two tasks: (1) sentiment polarity classification; and (2) ratings classification. Moreover, we provide standard splits of the dataset into training, validation and testing, for both polarity and ratings classification, in both balanced and unbalanced settings. We extend our previous work by performing a comprehensive analysis on the dataset. In particular, we perform an extended survey of the different classifiers typically used for the sentiment polarity classification problem. We also construct a sentiment lexicon from the dataset that contains both single and compound sentiment words and we explore its effectiveness. We make the dataset and experimental details publicly available.
Arabic Spelling Correction using Supervised Learning
Sep 29, 2014

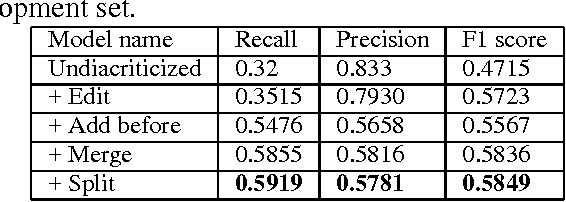
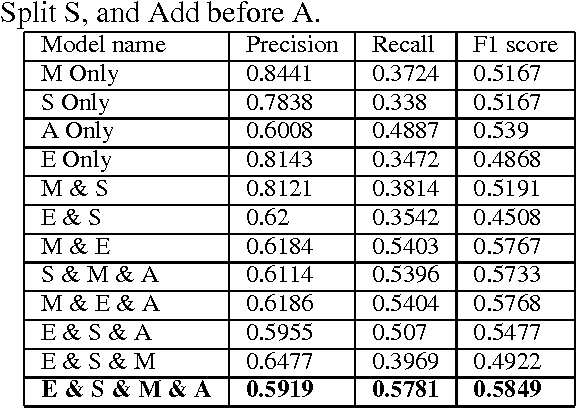
In this work, we address the problem of spelling correction in the Arabic language utilizing the new corpus provided by QALB (Qatar Arabic Language Bank) project which is an annotated corpus of sentences with errors and their corrections. The corpus contains edit, add before, split, merge, add after, move and other error types. We are concerned with the first four error types as they contribute more than 90% of the spelling errors in the corpus. The proposed system has many models to address each error type on its own and then integrating all the models to provide an efficient and robust system that achieves an overall recall of 0.59, precision of 0.58 and F1 score of 0.58 including all the error types on the development set. Our system participated in the QALB 2014 shared task "Automatic Arabic Error Correction" and achieved an F1 score of 0.6, earning the sixth place out of nine participants.
A review and comparison of strategies for multi-step ahead time series forecasting based on the NN5 forecasting competition
Aug 16, 2011

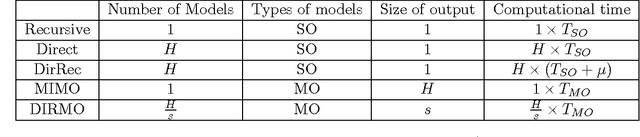
Multi-step ahead forecasting is still an open challenge in time series forecasting. Several approaches that deal with this complex problem have been proposed in the literature but an extensive comparison on a large number of tasks is still missing. This paper aims to fill this gap by reviewing existing strategies for multi-step ahead forecasting and comparing them in theoretical and practical terms. To attain such an objective, we performed a large scale comparison of these different strategies using a large experimental benchmark (namely the 111 series from the NN5 forecasting competition). In addition, we considered the effects of deseasonalization, input variable selection, and forecast combination on these strategies and on multi-step ahead forecasting at large. The following three findings appear to be consistently supported by the experimental results: Multiple-Output strategies are the best performing approaches, deseasonalization leads to uniformly improved forecast accuracy, and input selection is more effective when performed in conjunction with deseasonalization.
Round Trip Time Prediction Using the Symbolic Function Network Approach
Aug 09, 2008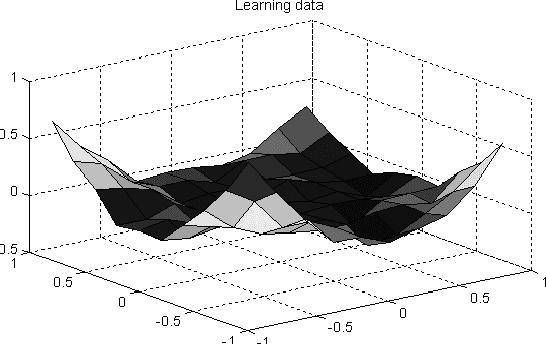

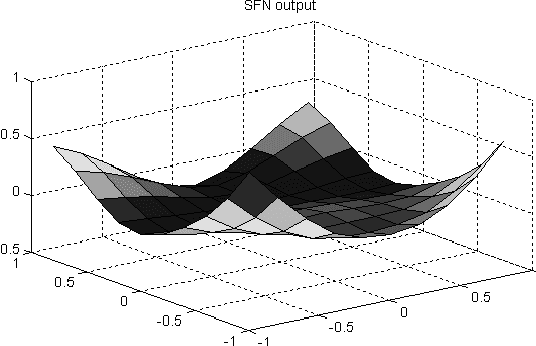
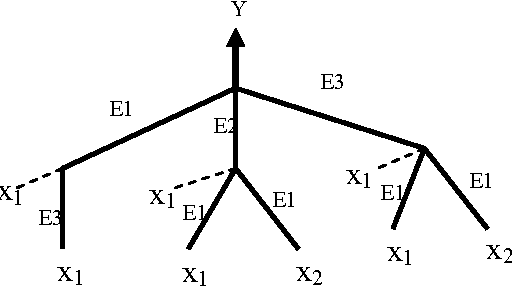
In this paper, we develop a novel approach to model the Internet round trip time using a recently proposed symbolic type neural network model called symbolic function network. The developed predictor is shown to have good generalization performance and simple representation compared to the multilayer perceptron based predictors.