 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMICRO: A Lightweight Middleware for Optimizing Cross-store Cross-model Graph-Relation Joins [Technical Report]
Mar 14, 2026Modern data applications increasingly involve heterogeneous data managed in different models and stored across disparate database engines, often deployed as separate installs. Limited research has addressed cross-model query processing in federated environments. This paper takes a step toward bridging this gap by: (1) formally defining a class of cross-model join queries between a graph store and a relational store by proposing a unified algebra; (2) introducing one real-world benchmark and four semi-synthetic benchmarks to evaluate such queries; and (3) proposing a lightweight middleware, MICRO, for efficient query execution. At the core of MICRO is CMLero, a learning-to-rank-based query optimizer that selects efficient execution plans without requiring exact cost estimation. By avoiding the need to materialize or convert all data into a single model, which is often infeasible due to third-party data control or cost, MICRO enables native querying across heterogeneous systems. Experimental results on the benchmark workloads demonstrate that MICRO outperforms the state-of-the-art federated relational system XDB by up to 2.1x in total runtime across the full test set. On the 93 test queries of real-world benchmark, 14 queries achieve over 100 speedup, including 4 queries with more than 100x speedup; however, 4 queries experienced slowdowns of over 5 seconds, highlighting opportunities for future improvement of MICRO. Further comparisons show that CMLero consistently outperforms rule-based and regression-based optimizers, highlighting the advantage of learning-to-rank in complex cross-model optimization.
Minimally Supervised Hierarchical Domain Intent Learning for CRS
May 04, 2025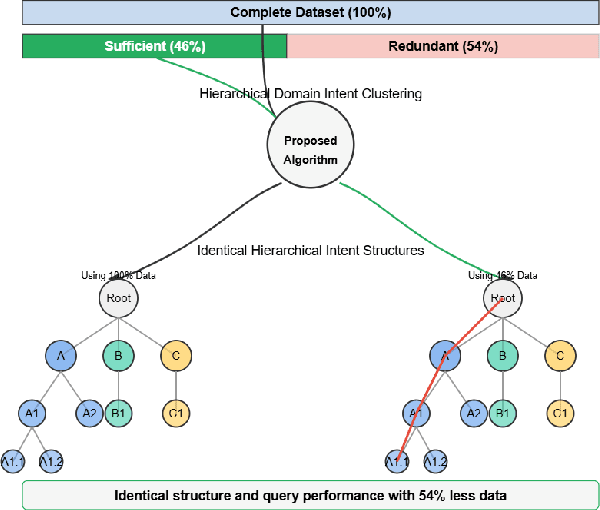

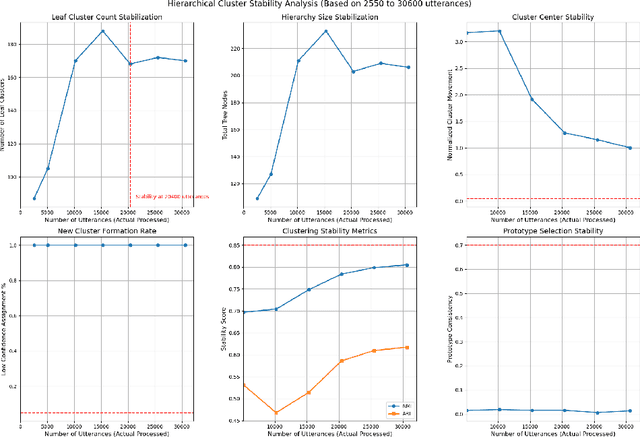
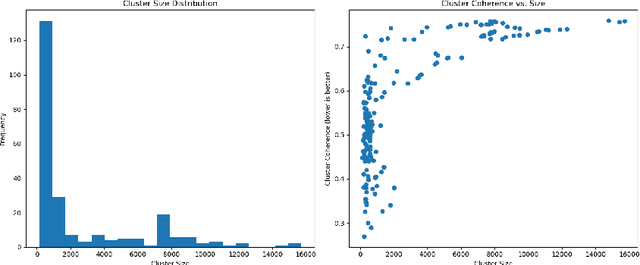
Modeling domain intent within an evolving domain structure presents a significant challenge for domain-specific conversational recommendation systems (CRS). The conventional approach involves training an intent model using utterance-intent pairs. However, as new intents and patterns emerge, the model must be continuously updated while preserving existing relationships and maintaining efficient retrieval. This process leads to substantial growth in utterance-intent pairs, making manual labeling increasingly costly and impractical. In this paper, we propose an efficient solution for constructing a dynamic hierarchical structure that minimizes the number of user utterances required to achieve adequate domain knowledge coverage. To this end, we introduce a neural network-based attention-driven hierarchical clustering algorithm designed to optimize intent grouping using minimal data. The proposed method builds upon and integrates concepts from two existing flat clustering algorithms DEC and NAM, both of which utilize neural attention mechanisms. We apply our approach to a curated subset of 44,000 questions from the business food domain. Experimental results demonstrate that constructing the hierarchy using a stratified sampling strategy significantly reduces the number of questions needed to represent the evolving intent structure. Our findings indicate that this approach enables efficient coverage of dynamic domain knowledge without frequent retraining, thereby enhancing scalability and adaptability in domain-specific CSRs.
MISCON: A Mission-Driven Conversational Consultant for Pre-Venture Entrepreneurs in Food Deserts
Jan 24, 2025This work-in-progress report describes MISCON, a conversational consultant being developed for a public mission project called NOURISH. With MISCON, aspiring small business owners in a food-insecure region and their advisors in Community-based organizations would be able to get information, recommendation and analysis regarding setting up food businesses. MISCON conversations are modeled as state machine that uses a heterogeneous knowledge graph as well as several analytical tools and services including a variety of LLMs. In this short report, we present the functional architecture and some design considerations behind MISCON.
Temporal Relation Extraction with a Graph-Based Deep Biaffine Attention Model
Jan 16, 2022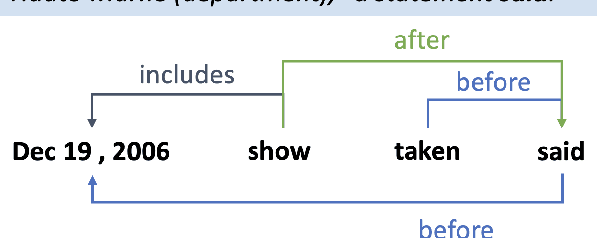

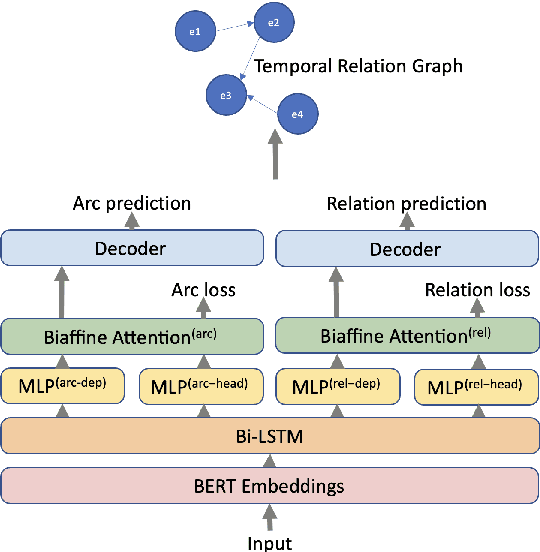
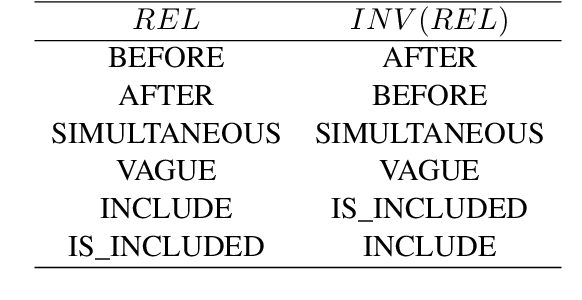
Temporal information extraction plays a critical role in natural language understanding. Previous systems have incorporated advanced neural language models and have successfully enhanced the accuracy of temporal information extraction tasks. However, these systems have two major shortcomings. First, they fail to make use of the two-sided nature of temporal relations in prediction. Second, they involve non-parallelizable pipelines in inference process that bring little performance gain. To this end, we propose a novel temporal information extraction model based on deep biaffine attention to extract temporal relationships between events in unstructured text efficiently and accurately. Our model is performant because we perform relation extraction tasks directly instead of considering event annotation as a prerequisite of relation extraction. Moreover, our architecture uses Multilayer Perceptrons (MLP) with biaffine attention to predict arcs and relation labels separately, improving relation detecting accuracy by exploiting the two-sided nature of temporal relationships. We experimentally demonstrate that our model achieves state-of-the-art performance in temporal relation extraction.
Discovering Technology Gaps using the IntSight Knowledge Navigator
Sep 11, 2021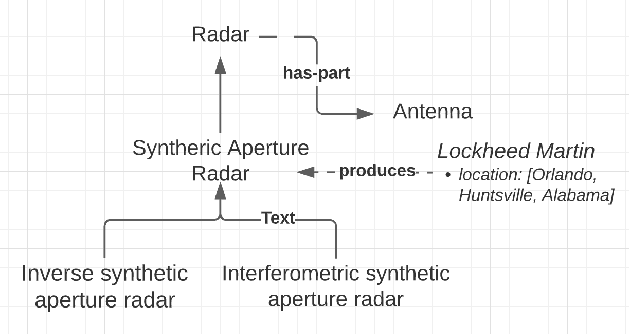
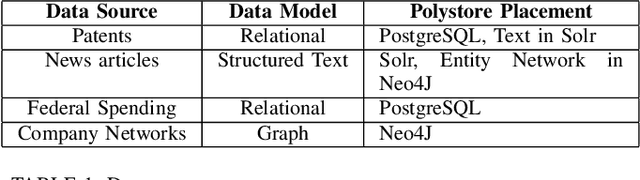
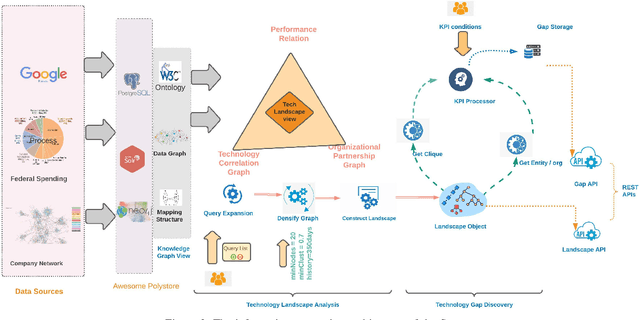
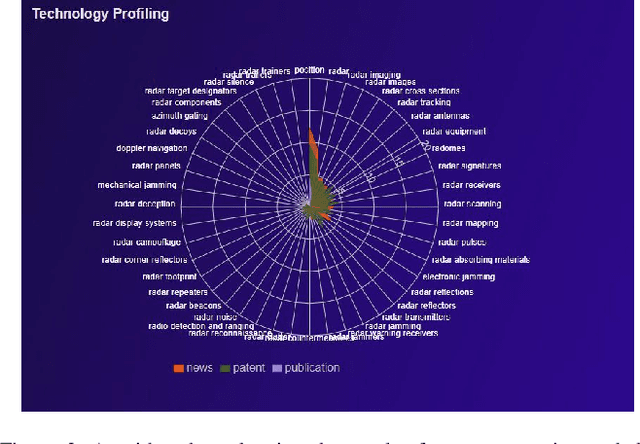
Knowledge analysis is an important application of knowledge graphs. In this paper, we present a complex knowledge analysis problem that discovers the gaps in the technology areas of interest to an organization. Our knowledge graph is developed on a heterogeneous data management platform. The analysis combines semantic search, graph analytics, and polystore query optimization.
News Meets Microblog: Hashtag Annotation via Retriever-Generator
Apr 18, 2021
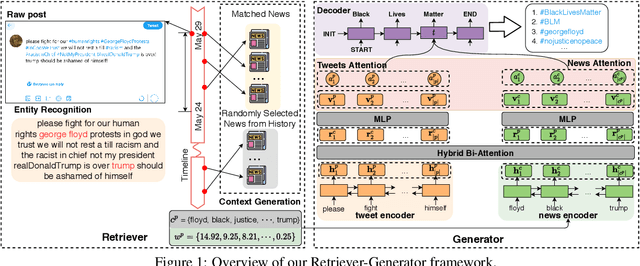
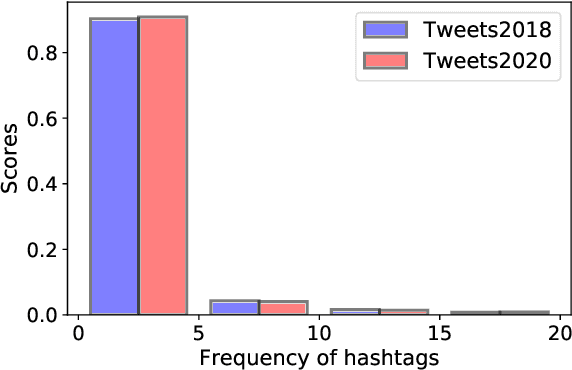
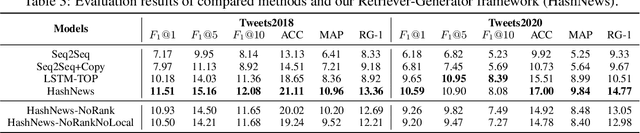
Hashtag annotation for microblog posts has been recently formulated as a sequence generation problem to handle emerging hashtags that are unseen in the training set. The state-of-the-art method leverages conversations initiated by posts to enrich contextual information for the short posts. However, it is unrealistic to assume the existence of conversations before the hashtag annotation itself. Therefore, we propose to leverage news articles published before the microblog post to generate hashtags following a Retriever-Generator framework. Extensive experiments on English Twitter datasets demonstrate superior performance and significant advantages of leveraging news articles to generate hashtags.
Ingesting High-Velocity Streaming Graphs from Social Media Sources
May 20, 2019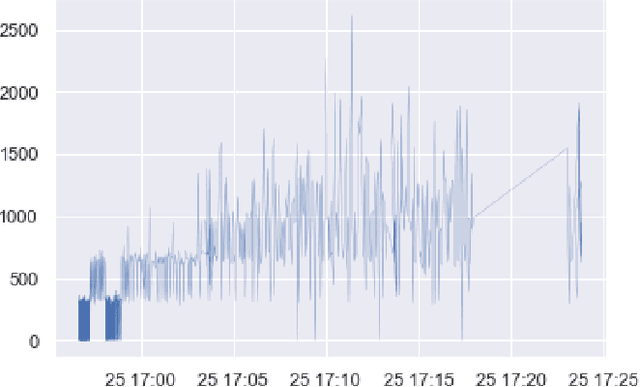
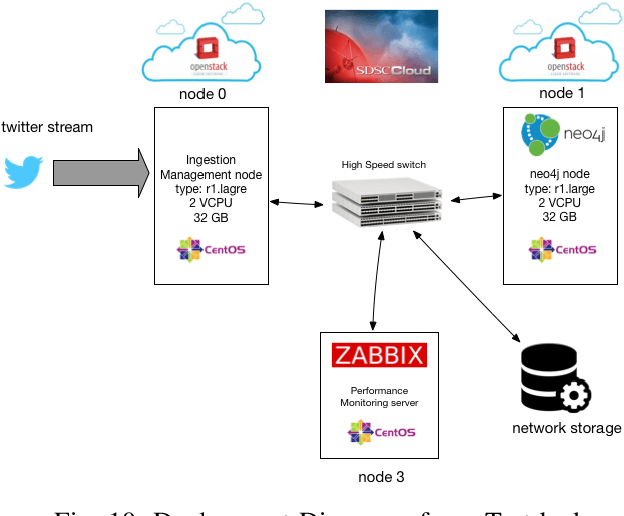
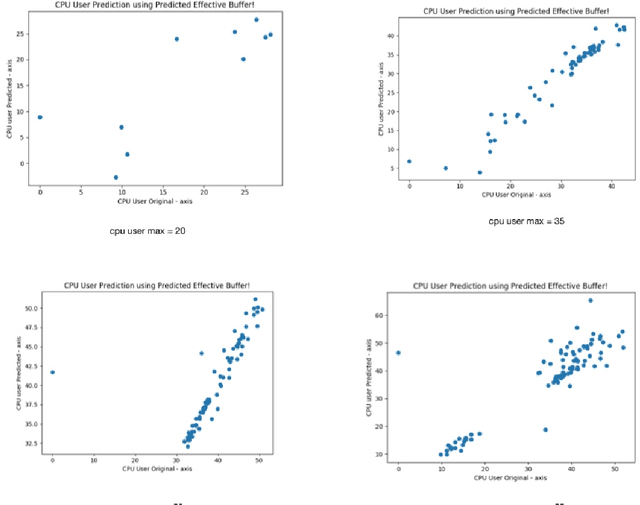
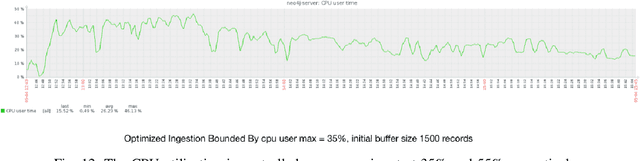
Many data science applications like social network analysis use graphs as their primary form of data. However, acquiring graph-structured data from social media presents some interesting challenges. The first challenge is the high data velocity and bursty nature of the social media data. The second challenge is that the complex nature of the data makes the ingestion process expensive. If we want to store the streaming graph data in a graph database, we face a third challenge -- the database is very often unable to sustain the ingestion of high-velocity, high-burst data. We have developed an adaptive buffering mechanism and a graph compression technique that effectively mitigates the problem. A novel aspect of our method is that the adaptive buffering algorithm uses the data rate, the data content as well as the CPU resources of the database machine to determine an optimal data ingestion mechanism. We further show that an ingestion-time graph-compression strategy improves the efficiency of the data ingestion into the database. We have verified the efficacy of our ingestion optimization strategy through extensive experiments.