 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Train Your Resistive Network: Generalized Equilibrium Propagation and Analytical Learning
Feb 03, 2026Machine learning is a powerful method of extracting meaning from data; unfortunately, current digital hardware is extremely energy-intensive. There is interest in an alternative analog computing implementation that could match the performance of traditional machine learning while being significantly more energy-efficient. However, it remains unclear how to train such analog computing systems while adhering to locality constraints imposed by the physical (as opposed to digital) nature of these systems. Local learning algorithms such as Equilibrium Propagation and Coupled Learning have been proposed to address this issue. In this paper, we develop an algorithm to exactly calculate gradients using a graph theoretic and analytical framework for Kirchhoff's laws. We also introduce Generalized Equilibrium Propagation, a framework encompassing a broad class of Hebbian learning algorithms, including Coupled Learning and Equilibrium Propagation, and show how our algorithm compares. We demonstrate our algorithm using numerical simulations and show that we can train resistor networks without the need for a replica or readout over all resistors, only at the output layer. We also show that under the analytical gradient approach, it is possible to update only a subset of the resistance values without a strong degradation in performance.
Autonomous Learning of Attractors for Neuromorphic Computing with Wien Bridge Oscillator Networks
Dec 16, 2025


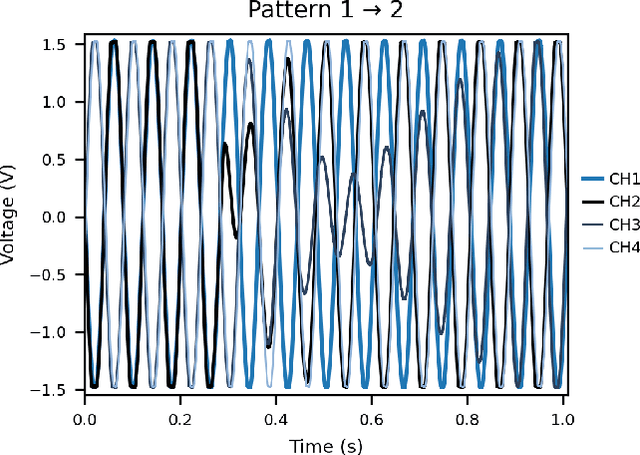
We present an oscillatory neuromorphic primitive implemented with networks of coupled Wien bridge oscillators and tunable resistive couplings. Phase relationships between oscillators encode patterns, and a local Hebbian learning rule continuously adapts the couplings, allowing learning and recall to emerge from the same ongoing analog dynamics rather than from separate training and inference phases. Using a Kuramoto-style phase model with an effective energy function, we show that learned phase patterns form attractor states and validate this behavior in simulation and hardware. We further realize a 2-4-2 architecture with a hidden layer of oscillators, whose bipartite visible-hidden coupling allows multiple internal configurations to produce the same visible phase states. When inputs are switched, transient spikes in energy followed by relaxation indicate how the network can reduce surprise by reshaping its energy landscape. These results support coupled oscillator circuits as a hardware platform for energy-based neuromorphic computing with autonomous, continuous learning.
Carbon Emission Prediction on the World Bank Dataset for Canada
Nov 26, 2022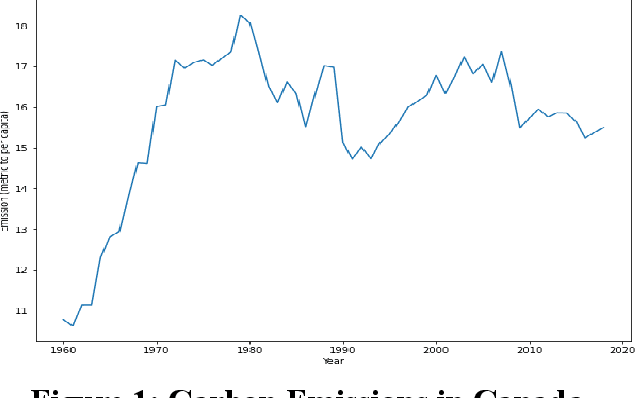
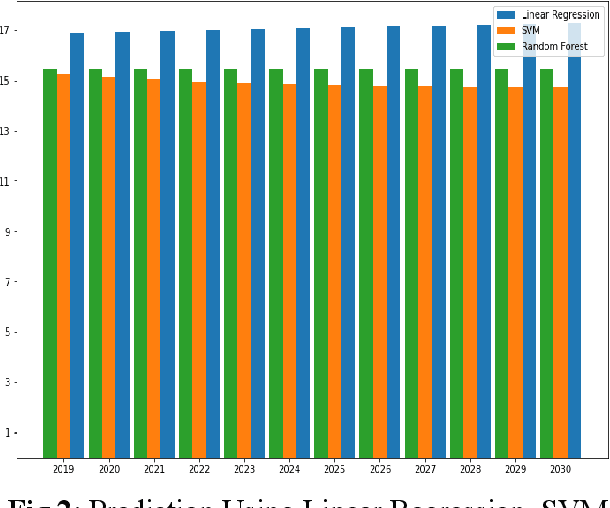
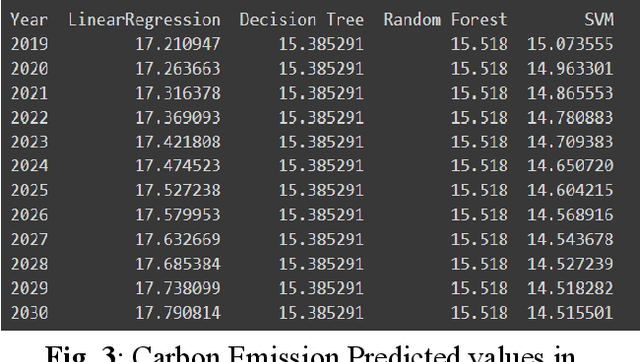
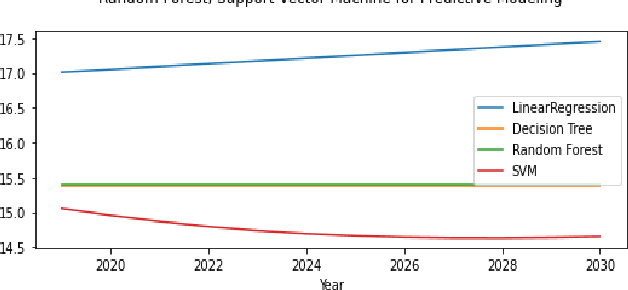
The continuous rise in CO2 emission into the environment is one of the most crucial issues facing the whole world. Many countries are making crucial decisions to control their carbon footprints to escape some of their catastrophic outcomes. There has been a lot of research going on to project the amount of carbon emissions in the future, which can help us to develop innovative techniques to deal with it in advance. Machine learning is one of the most advanced and efficient techniques for predicting the amount of carbon emissions from current data. This paper provides the methods for predicting carbon emissions (CO2 emissions) for the next few years. The predictions are based on data from the past 50 years. The dataset, which is used for making the prediction, is collected from World Bank datasets. This dataset contains CO2 emissions (metric tons per capita) of all the countries from 1960 to 2018. Our method consists of using machine learning techniques to take the idea of what carbon emission measures will look like in the next ten years and project them onto the dataset taken from the World Bank's data repository. The purpose of this research is to compare how different machine learning models (Decision Tree, Linear Regression, Random Forest, and Support Vector Machine) perform on a similar dataset and measure the difference between their predictions.
Learning Personal Food Preferences via Food Logs Embedding
Nov 22, 2021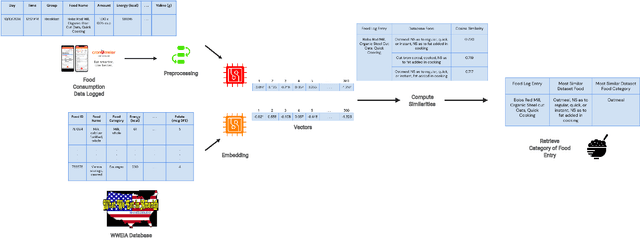
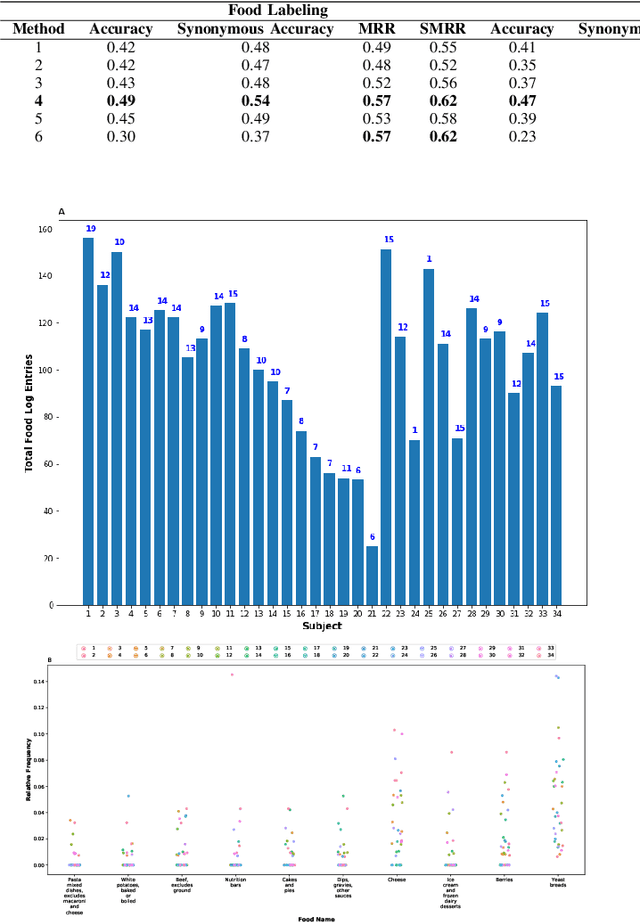

Diet management is key to managing chronic diseases such as diabetes. Automated food recommender systems may be able to assist by providing meal recommendations that conform to a user's nutrition goals and food preferences. Current recommendation systems suffer from a lack of accuracy that is in part due to a lack of knowledge of food preferences, namely foods users like to and are able to eat frequently. In this work, we propose a method for learning food preferences from food logs, a comprehensive but noisy source of information about users' dietary habits. We also introduce accompanying metrics. The method generates and compares word embeddings to identify the parent food category of each food entry and then calculates the most popular. Our proposed approach identifies 82% of a user's ten most frequently eaten foods. Our method is publicly available on (https://github.com/aametwally/LearningFoodPreferences)