 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of real-time transcriptions using end-to-end ASR models
Sep 11, 2024
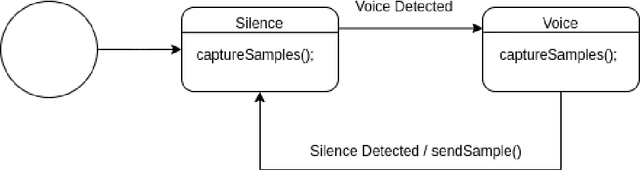


Automatic Speech Recognition (ASR) or Speech-to-text (STT) has greatly evolved in the last few years. Traditional architectures based on pipelines have been replaced by joint end-to-end (E2E) architectures that simplify and streamline the model training process. In addition, new AI training methods, such as weak-supervised learning have reduced the need for high-quality audio datasets for model training. However, despite all these advancements, little to no research has been done on real-time transcription. In real-time scenarios, the audio is not pre-recorded, and the input audio must be fragmented to be processed by the ASR systems. To achieve real-time requirements, these fragments must be as short as possible to reduce latency. However, audio cannot be split at any point as dividing an utterance into two separate fragments will generate an incorrect transcription. Also, shorter fragments provide less context for the ASR model. For this reason, it is necessary to design and test different splitting algorithms to optimize the quality and delay of the resulting transcription. In this paper, three audio splitting algorithms are evaluated with different ASR models to determine their impact on both the quality of the transcription and the end-to-end delay. The algorithms are fragmentation at fixed intervals, voice activity detection (VAD), and fragmentation with feedback. The results are compared to the performance of the same model, without audio fragmentation, to determine the effects of this division. The results show that VAD fragmentation provides the best quality with the highest delay, whereas fragmentation at fixed intervals provides the lowest quality and the lowest delay. The newly proposed feedback algorithm exchanges a 2-4% increase in WER for a reduction of 1.5-2s delay, respectively, to the VAD splitting.
Concurrent Classifier Error Detection (CCED) in Large Scale Machine Learning Systems
Jun 02, 2023



The complexity of Machine Learning (ML) systems increases each year, with current implementations of large language models or text-to-image generators having billions of parameters and requiring billions of arithmetic operations. As these systems are widely utilized, ensuring their reliable operation is becoming a design requirement. Traditional error detection mechanisms introduce circuit or time redundancy that significantly impacts system performance. An alternative is the use of Concurrent Error Detection (CED) schemes that operate in parallel with the system and exploit their properties to detect errors. CED is attractive for large ML systems because it can potentially reduce the cost of error detection. In this paper, we introduce Concurrent Classifier Error Detection (CCED), a scheme to implement CED in ML systems using a concurrent ML classifier to detect errors. CCED identifies a set of check signals in the main ML system and feeds them to the concurrent ML classifier that is trained to detect errors. The proposed CCED scheme has been implemented and evaluated on two widely used large-scale ML models: Contrastive Language Image Pretraining (CLIP) used for image classification and Bidirectional Encoder Representations from Transformers (BERT) used for natural language applications. The results show that more than 95 percent of the errors are detected when using a simple Random Forest classifier that is order of magnitude simpler than CLIP or BERT. These results illustrate the potential of CCED to implement error detection in large-scale ML models.