 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Sampling: Assessing Lexical Reachability in LLMs via the Word Coverage Score (WCS)
May 26, 2026Modern Large Language Models (LLMs) are often criticized for producing repetitive and homogeneous text, despite possessing vast latent vocabularies. While previous research has focused on model knowledge and training data, we investigate the role of decoding mechanics in suppressing linguistic diversity. We introduce the Word Coverage Score (WCS), a metric that quantifies the extent to which contextually appropriate human vocabulary is mathematically pruned by standard sampling filters (e.g., Top-$p$, Top-$k$, and Min-$p$). Rather than assessing static knowledge, the WCS measures the lexical survival rate of low-frequency, high-information human words as a function of sampling parameters. By auditing open-weight models on human-authored corpus fragments, we identify which logical lexical choices are rendered unreachable by the decoder, even when they reside within the probability space. Our results provide quantitative evidence that industry-standard sampling defaults act as unintended censorship mechanisms, smoothing the unique textures of human expression into a homogenized discourse. The WCS offers a rigorous framework for optimizing the trade-off between text coherence and lexical richness, providing a diagnostic tool for preserving the diversity of human language in generative models.
To Words and Beyond: Probing Large Language Models for Sentence-Level Psycholinguistic Norms of Memorability and Reading Times
Mar 12, 2026Large Language Models (LLMs) have recently been shown to produce estimates of psycholinguistic norms, such as valence, arousal, or concreteness, for words and multiword expressions, that correlate with human judgments. These estimates are obtained by prompting an LLM, in zero-shot fashion, with a question similar to those used in human studies. Meanwhile, for other norms such as lexical decision time or age of acquisition, LLMs require supervised fine-tuning to obtain results that align with ground-truth values. In this paper, we extend this approach to the previously unstudied features of sentence memorability and reading times, which involve the relationship between multiple words in a sentence-level context. Our results show that via fine-tuning, models can provide estimates that correlate with human-derived norms and exceed the predictive power of interpretable baseline predictors, demonstrating that LLMs contain useful information about sentence-level features. At the same time, our results show very mixed zero-shot and few-shot performance, providing further evidence that care is needed when using LLM-prompting as a proxy for human cognitive measures.
Adding LLMs to the psycholinguistic norming toolbox: A practical guide to getting the most out of human ratings
Sep 17, 2025


Word-level psycholinguistic norms lend empirical support to theories of language processing. However, obtaining such human-based measures is not always feasible or straightforward. One promising approach is to augment human norming datasets by using Large Language Models (LLMs) to predict these characteristics directly, a practice that is rapidly gaining popularity in psycholinguistics and cognitive science. However, the novelty of this approach (and the relative inscrutability of LLMs) necessitates the adoption of rigorous methodologies that guide researchers through this process, present the range of possible approaches, and clarify limitations that are not immediately apparent, but may, in some cases, render the use of LLMs impractical. In this work, we present a comprehensive methodology for estimating word characteristics with LLMs, enriched with practical advice and lessons learned from our own experience. Our approach covers both the direct use of base LLMs and the fine-tuning of models, an alternative that can yield substantial performance gains in certain scenarios. A major emphasis in the guide is the validation of LLM-generated data with human "gold standard" norms. We also present a software framework that implements our methodology and supports both commercial and open-weight models. We illustrate the proposed approach with a case study on estimating word familiarity in English. Using base models, we achieved a Spearman correlation of 0.8 with human ratings, which increased to 0.9 when employing fine-tuned models. This methodology, framework, and set of best practices aim to serve as a reference for future research on leveraging LLMs for psycholinguistic and lexical studies.
The Generative Energy Arena (GEA): Incorporating Energy Awareness in Large Language Model (LLM) Human Evaluations
Jul 17, 2025



The evaluation of large language models is a complex task, in which several approaches have been proposed. The most common is the use of automated benchmarks in which LLMs have to answer multiple-choice questions of different topics. However, this method has certain limitations, being the most concerning, the poor correlation with the humans. An alternative approach, is to have humans evaluate the LLMs. This poses scalability issues as there is a large and growing number of models to evaluate making it impractical (and costly) to run traditional studies based on recruiting a number of evaluators and having them rank the responses of the models. An alternative approach is the use of public arenas, such as the popular LM arena, on which any user can freely evaluate models on any question and rank the responses of two models. The results are then elaborated into a model ranking. An increasingly important aspect of LLMs is their energy consumption and, therefore, evaluating how energy awareness influences the decisions of humans in selecting a model is of interest. In this paper, we present GEA, the Generative Energy Arena, an arena that incorporates information on the energy consumption of the model in the evaluation process. Preliminary results obtained with GEA are also presented, showing that for most questions, when users are aware of the energy consumption, they favor smaller and more energy efficient models. This suggests that for most user interactions, the extra cost and energy incurred by the more complex and top-performing models do not provide an increase in the perceived quality of the responses that justifies their use.
Why Do Large Language Models (LLMs) Struggle to Count Letters?
Dec 19, 2024



Large Language Models (LLMs) have achieved unprecedented performance on many complex tasks, being able, for example, to answer questions on almost any topic. However, they struggle with other simple tasks, such as counting the occurrences of letters in a word, as illustrated by the inability of many LLMs to count the number of "r" letters in "strawberry". Several works have studied this problem and linked it to the tokenization used by LLMs, to the intrinsic limitations of the attention mechanism, or to the lack of character-level training data. In this paper, we conduct an experimental study to evaluate the relations between the LLM errors when counting letters with 1) the frequency of the word and its components in the training dataset and 2) the complexity of the counting operation. We present a comprehensive analysis of the errors of LLMs when counting letter occurrences by evaluating a representative group of models over a large number of words. The results show a number of consistent trends in the models evaluated: 1) models are capable of recognizing the letters but not counting them; 2) the frequency of the word and tokens in the word does not have a significant impact on the LLM errors; 3) there is a positive correlation of letter frequency with errors, more frequent letters tend to have more counting errors, 4) the errors show a strong correlation with the number of letters or tokens in a word and 5) the strongest correlation occurs with the number of letters with counts larger than one, with most models being unable to correctly count words in which letters appear more than twice.
Evaluation of real-time transcriptions using end-to-end ASR models
Sep 11, 2024
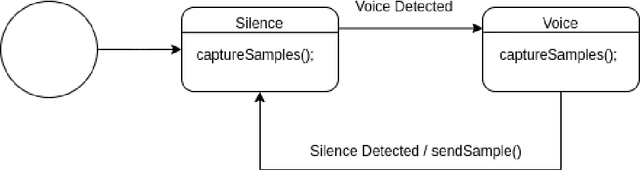


Automatic Speech Recognition (ASR) or Speech-to-text (STT) has greatly evolved in the last few years. Traditional architectures based on pipelines have been replaced by joint end-to-end (E2E) architectures that simplify and streamline the model training process. In addition, new AI training methods, such as weak-supervised learning have reduced the need for high-quality audio datasets for model training. However, despite all these advancements, little to no research has been done on real-time transcription. In real-time scenarios, the audio is not pre-recorded, and the input audio must be fragmented to be processed by the ASR systems. To achieve real-time requirements, these fragments must be as short as possible to reduce latency. However, audio cannot be split at any point as dividing an utterance into two separate fragments will generate an incorrect transcription. Also, shorter fragments provide less context for the ASR model. For this reason, it is necessary to design and test different splitting algorithms to optimize the quality and delay of the resulting transcription. In this paper, three audio splitting algorithms are evaluated with different ASR models to determine their impact on both the quality of the transcription and the end-to-end delay. The algorithms are fragmentation at fixed intervals, voice activity detection (VAD), and fragmentation with feedback. The results are compared to the performance of the same model, without audio fragmentation, to determine the effects of this division. The results show that VAD fragmentation provides the best quality with the highest delay, whereas fragmentation at fixed intervals provides the lowest quality and the lowest delay. The newly proposed feedback algorithm exchanges a 2-4% increase in WER for a reduction of 1.5-2s delay, respectively, to the VAD splitting.