 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Before Constraining: A Unified Decoding Framework for Large Language Models
Jan 12, 2026Natural generation allows Language Models (LMs) to produce free-form responses with rich reasoning, but the lack of guaranteed structure makes outputs difficult to parse or verify. Structured generation, or constrained decoding, addresses this drawback by producing content in standardized formats such as JSON, ensuring consistency and guaranteed-parsable outputs, but it can inadvertently restrict the model's reasoning capabilities. In this work, we propose a simple approach that combines the advantages of both natural and structured generation. By allowing LLMs to reason freely until specific trigger tokens are generated, and then switching to structured generation, our method preserves the expressive power of natural language reasoning while ensuring the reliability of structured outputs. We further evaluate our approach on several datasets, covering both classification and reasoning tasks, to demonstrate its effectiveness, achieving a substantial gain of up to 27% in accuracy compared to natural generation, while requiring only a small overhead of 10-20 extra tokens.
Certainty-Guided Reasoning in Large Language Models: A Dynamic Thinking Budget Approach
Sep 09, 2025
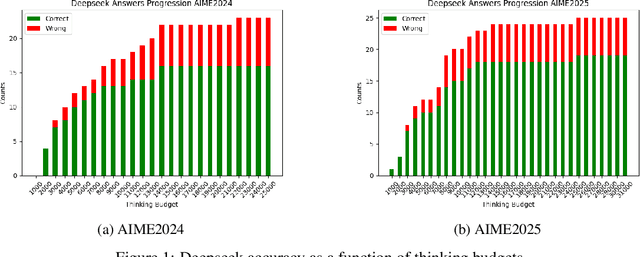

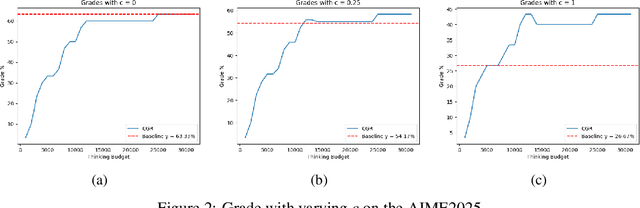
The rise of large reasoning language models (LRLMs) has unlocked new potential for solving complex tasks. These models operate with a thinking budget, that is, a predefined number of reasoning tokens used to arrive at a solution. We propose a novel approach, inspired by the generator/discriminator framework in generative adversarial networks, in which a critic model periodically probes its own reasoning to assess whether it has reached a confident conclusion. If not, reasoning continues until a target certainty threshold is met. This mechanism adaptively balances efficiency and reliability by allowing early termination when confidence is high, while encouraging further reasoning when uncertainty persists. Through experiments on the AIME2024 and AIME2025 datasets, we show that Certainty-Guided Reasoning (CGR) improves baseline accuracy while reducing token usage. Importantly, extended multi-seed evaluations over 64 runs demonstrate that CGR is stable, reducing variance across seeds and improving exam-like performance under penalty-based grading. Additionally, our token savings analysis shows that CGR can eliminate millions of tokens in aggregate, with tunable trade-offs between certainty thresholds and efficiency. Together, these findings highlight certainty as a powerful signal for reasoning sufficiency. By integrating confidence into the reasoning process, CGR makes large reasoning language models more adaptive, trustworthy, and resource efficient, paving the way for practical deployment in domains where both accuracy and computational cost matter.
Structured Thinking Matters: Improving LLMs Generalization in Causal Inference Tasks
May 23, 2025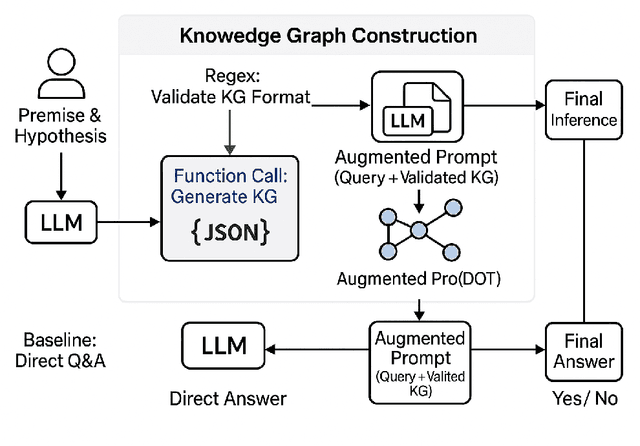


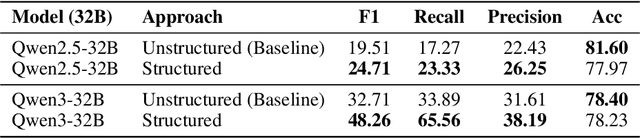
Despite remarkable advances in the field, LLMs remain unreliable in distinguishing causation from correlation. Recent results from the Corr2Cause dataset benchmark reveal that state-of-the-art LLMs -- such as GPT-4 (F1 score: 29.08) -- only marginally outperform random baselines (Random Uniform, F1 score: 20.38), indicating limited capacity of generalization. To tackle this limitation, we propose a novel structured approach: rather than directly answering causal queries, we provide the model with the capability to structure its thinking by guiding the model to build a structured knowledge graph, systematically encoding the provided correlational premises, to answer the causal queries. This intermediate representation significantly enhances the model's causal capabilities. Experiments on the test subset of the Corr2Cause dataset benchmark with Qwen3-32B model (reasoning model) show substantial gains over standard direct prompting methods, improving F1 scores from 32.71 to 48.26 (over 47.5% relative increase), along with notable improvements in precision and recall. These results underscore the effectiveness of providing the model with the capability to structure its thinking and highlight its promising potential for broader generalization across diverse causal inference tasks.
Large Language Models Playing Mixed Strategy Nash Equilibrium Games
Jun 15, 2024Generative artificial intelligence (Generative AI), and in particular Large Language Models (LLMs) have gained significant popularity among researchers and industrial communities, paving the way for integrating LLMs in different domains, such as robotics, telecom, and healthcare. In this paper, we study the intersection of game theory and generative artificial intelligence, focusing on the capabilities of LLMs to find the Nash equilibrium in games with a mixed strategy Nash equilibrium and no pure strategy Nash equilibrium (that we denote mixed strategy Nash equilibrium games). The study reveals a significant enhancement in the performance of LLMs when they are equipped with the possibility to run code and are provided with a specific prompt to incentivize them to do so. However, our research also highlights the limitations of LLMs when the randomization strategy of the game is not easy to deduce. It is evident that while LLMs exhibit remarkable proficiency in well-known standard games, their performance dwindles when faced with slight modifications of the same games. This paper aims to contribute to the growing body of knowledge on the intersection of game theory and generative artificial intelligence while providing valuable insights into LLMs strengths and weaknesses. It also underscores the need for further research to overcome the limitations of LLMs, particularly in dealing with even slightly more complex scenarios, to harness their full potential.
Experimental Comparison of Ensemble Methods and Time-to-Event Analysis Models Through Integrated Brier Score and Concordance Index
Mar 12, 2024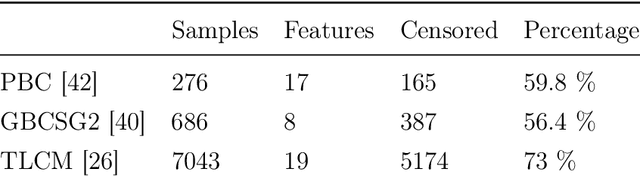
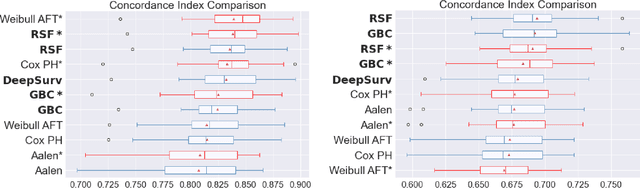
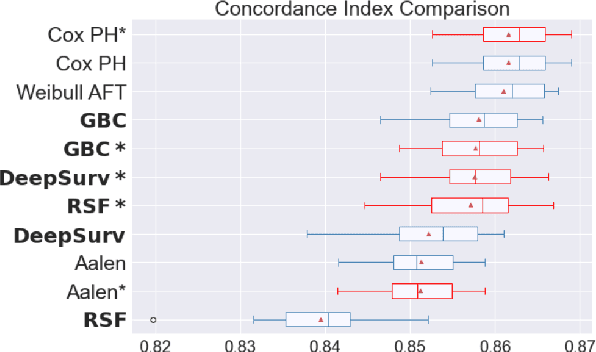
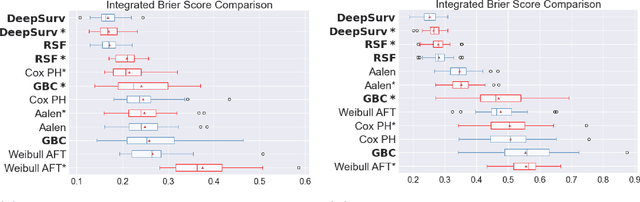
Time-to-event analysis is a branch of statistics that has increased in popularity during the last decades due to its many application fields, such as predictive maintenance, customer churn prediction and population lifetime estimation. In this paper, we review and compare the performance of several prediction models for time-to-event analysis. These consist of semi-parametric and parametric statistical models, in addition to machine learning approaches. Our study is carried out on three datasets and evaluated in two different scores (the integrated Brier score and concordance index). Moreover, we show how ensemble methods, which surprisingly have not yet been much studied in time-to-event analysis, can improve the prediction accuracy and enhance the robustness of the prediction performance. We conclude the analysis with a simulation experiment in which we evaluate the factors influencing the performance ranking of the methods using both scores.
Experimental Comparison of Semi-parametric, Parametric, and Machine Learning Models for Time-to-Event Analysis Through the Concordance Index
Mar 13, 2020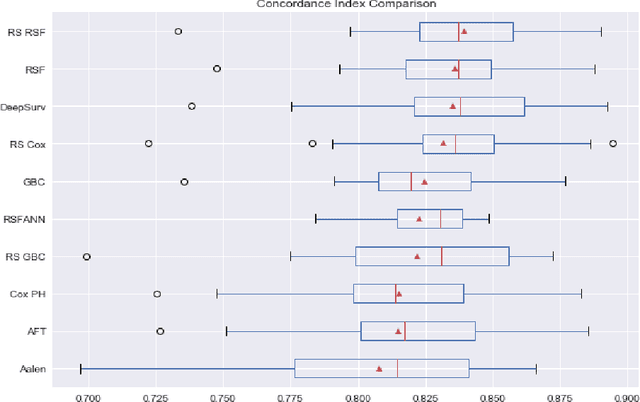
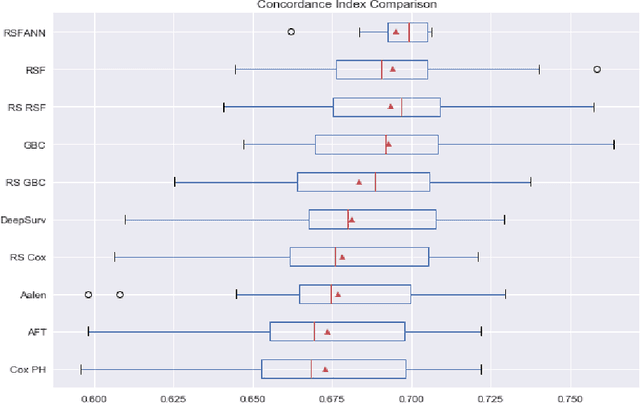
In this paper, we make an experimental comparison of semi-parametric (Cox proportional hazards model, Aalen's additive regression model), parametric (Weibull AFT model), and machine learning models (Random Survival Forest, Gradient Boosting with Cox Proportional Hazards Loss, DeepSurv) through the concordance index on two different datasets (PBC and GBCSG2). We present two comparisons: one with the default hyper-parameters of these models and one with the best hyper-parameters found by randomized search.
Colonel Blotto and Hide-and-Seek Games as Path Planning Problems with Side Observations
Jun 03, 2019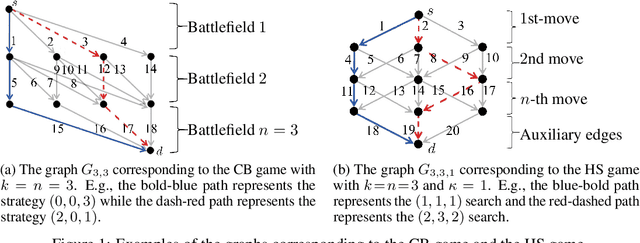
Resource allocation games such as the famous Colonel Blotto (CB) and Hide-and-Seek (HS) games are often used to model a large variety of practical problems, but only in their one-shot versions. Indeed, due to their extremely large strategy space, it remains an open question how one can efficiently learn in these games. In this work, we show that the online CB and HS games can be cast as path planning problems with side-observations (SOPPP): at each stage, a learner chooses a path on a directed acyclic graph and suffers the sum of losses that are adversarially assigned to the corresponding edges; and she then receives semi-bandit feedback with side-observations (i.e., she observes the losses on the chosen edges plus some others). Then, we propose a novel algorithm, EXP3-OE, the first-of-its-kind with guaranteed efficient running time for SOPPP without requiring any auxiliary oracle. We provide an expected-regret bound of EXP3-OE in SOPPP matching the order of the best benchmark in the literature. Moreover, we introduce additional assumptions on the observability model under which we can further improve the regret bounds of EXP3-OE. We illustrate the benefit of using EXP3-OE in SOPPP by applying it to the online CB and HS games.