 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Learning for Stochastic Control under General Information Structures and Non-Markovian Environments
Oct 31, 2023

As a primary contribution, we present a convergence theorem for stochastic iterations, and in particular, Q-learning iterates, under a general, possibly non-Markovian, stochastic environment. Our conditions for convergence involve an ergodicity and a positivity criterion. We provide a precise characterization on the limit of the iterates and conditions on the environment and initializations for convergence. As our second contribution, we discuss the implications and applications of this theorem to a variety of stochastic control problems with non-Markovian environments involving (i) quantized approximations of fully observed Markov Decision Processes (MDPs) with continuous spaces (where quantization break down the Markovian structure), (ii) quantized approximations of belief-MDP reduced partially observable MDPS (POMDPs) with weak Feller continuity and a mild version of filter stability (which requires the knowledge of the model by the controller), (iii) finite window approximations of POMDPs under a uniform controlled filter stability (which does not require the knowledge of the model), and (iv) for multi-agent models where convergence of learning dynamics to a new class of equilibria, subjective Q-learning equilibria, will be studied. In addition to the convergence theorem, some implications of the theorem above are new to the literature and others are interpreted as applications of the convergence theorem. Some open problems are noted.
Q-Learning for MDPs with General Spaces: Convergence and Near Optimality via Quantization under Weak Continuity
Nov 12, 2021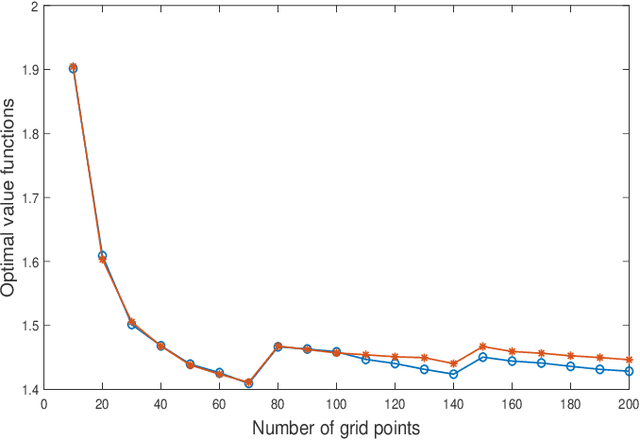
Reinforcement learning algorithms often require finiteness of state and action spaces in Markov decision processes (MDPs) and various efforts have been made in the literature towards the applicability of such algorithms for continuous state and action spaces. In this paper, we show that under very mild regularity conditions (in particular, involving only weak continuity of the transition kernel of an MDP), Q-learning for standard Borel MDPs via quantization of states and actions converge to a limit, and furthermore this limit satisfies an optimality equation which leads to near optimality with either explicit performance bounds or which are guaranteed to be asymptotically optimal. Our approach builds on (i) viewing quantization as a measurement kernel and thus a quantized MDP as a POMDP, (ii) utilizing near optimality and convergence results of Q-learning for POMDPs, and (iii) finally, near-optimality of finite state model approximations for MDPs with weakly continuous kernels which we show to correspond to the fixed point of the constructed POMDP. Thus, our paper presents a very general convergence and approximation result for the applicability of Q-learning for continuous MDPs.
Convergence of Finite Memory Q-Learning for POMDPs and Near Optimality of Learned Policies under Filter Stability
Mar 22, 2021
In this paper, for POMDPs, we provide the convergence of a Q learning algorithm for control policies using a finite history of past observations and control actions, and, consequentially, we establish near optimality of such limit Q functions under explicit filter stability conditions. We present explicit error bounds relating the approximation error to the length of the finite history window. We establish the convergence of such Q-learning iterations under mild ergodicity assumptions on the state process during the exploration phase. We further show that the limit fixed point equation gives an optimal solution for an approximate belief-MDP. We then provide bounds on the performance of the policy obtained using the limit Q values compared to the performance of the optimal policy for the POMDP, where we also present explicit conditions using recent results on filter stability in controlled POMDPs. While there exist many experimental results, (i) the rigorous asymptotic convergence (to an approximate MDP value function) for such finite-memory Q-learning algorithms, and (ii) the near optimality with an explicit rate of convergence (in the memory size) are results that are new to the literature, to our knowledge.
Near Optimality of Finite Memory Feedback Policies in Partially Observed Markov Decision Processes
Oct 15, 2020



In the theory of Partially Observed Markov Decision Processes (POMDPs), existence of optimal policies have in general been established via converting the original partially observed stochastic control problem to a fully observed one on the belief space, leading to a belief-MDP. However, computing an optimal policy for this fully observed model, and so for the original POMDP, using classical dynamic or linear programming methods is challenging even if the original system has finite state and action spaces, since the state space of the fully observed belief-MDP model is always uncountable. Furthermore, there exist very few rigorous approximation results, as regularity conditions needed often require a tedious study involving the spaces of probability measures leading to properties such as Feller continuity. In this paper, we rigorously establish near optimality of finite window control policies in POMDPs under mild non-linear filter stability conditions and the assumption that the measurement and action sets are finite (and the state space is real vector valued). We also establish a rate of convergence result which relates the finite window memory size and the approximation error bound, where the rate of convergence is exponential under explicit and testable geometric filter stability conditions. While there exist many experimental results and few rigorous asymptotic convergence results, an explicit rate of convergence result is new in the literature, to our knowledge.