 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantizer Design for Finite Model Approximations, Model Learning, and Quantized Q-Learning for MDPs with Unbounded Spaces
Oct 05, 2025In this paper, for Markov decision processes (MDPs) with unbounded state spaces we present refined upper bounds presented in [Kara et. al. JMLR'23] on finite model approximation errors via optimizing the quantizers used for finite model approximations. We also consider implications on quantizer design for quantized Q-learning and empirical model learning, and the performance of policies obtained via Q-learning where the quantized state is treated as the state itself. We highlight the distinctions between planning, where approximating MDPs can be independently designed, and learning (either via Q-learning or empirical model learning), where approximating MDPs are restricted to be defined by invariant measures of Markov chains under exploration policies, leading to significant subtleties on quantizer design performance, even though asymptotic near optimality can be established under both setups. In particular, under Lyapunov growth conditions, we obtain explicit upper bounds which decay to zero as the number of bins approaches infinity.
Kernel Mean Embedding Topology: Weak and Strong Forms for Stochastic Kernels and Implications for Model Learning
Feb 19, 2025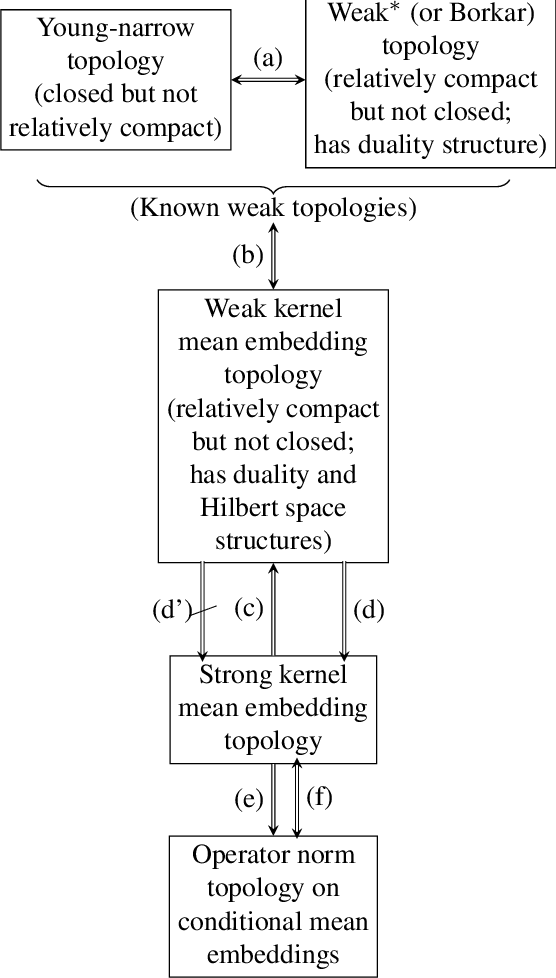

We introduce a novel topology, called Kernel Mean Embedding Topology, for stochastic kernels, in a weak and strong form. This topology, defined on the spaces of Bochner integrable functions from a signal space to a space of probability measures endowed with a Hilbert space structure, allows for a versatile formulation. This construction allows one to obtain both a strong and weak formulation. (i) For its weak formulation, we highlight the utility on relaxed policy spaces, and investigate connections with the Young narrow topology and Borkar (or \( w^* \))-topology, and establish equivalence properties. We report that, while both the \( w^* \)-topology and kernel mean embedding topology are relatively compact, they are not closed. Conversely, while the Young narrow topology is closed, it lacks relative compactness. (ii) We show that the strong form provides an appropriate formulation for placing topologies on spaces of models characterized by stochastic kernels with explicit robustness and learning theoretic implications on optimal stochastic control under discounted or average cost criteria. (iii) We show that this topology possesses several properties making it ideal to study optimality, approximations, robustness and continuity properties. In particular, the kernel mean embedding topology has a Hilbert space structure, which is particularly useful for approximating stochastic kernels through simulation data.
Q-Learning for Stochastic Control under General Information Structures and Non-Markovian Environments
Oct 31, 2023

As a primary contribution, we present a convergence theorem for stochastic iterations, and in particular, Q-learning iterates, under a general, possibly non-Markovian, stochastic environment. Our conditions for convergence involve an ergodicity and a positivity criterion. We provide a precise characterization on the limit of the iterates and conditions on the environment and initializations for convergence. As our second contribution, we discuss the implications and applications of this theorem to a variety of stochastic control problems with non-Markovian environments involving (i) quantized approximations of fully observed Markov Decision Processes (MDPs) with continuous spaces (where quantization break down the Markovian structure), (ii) quantized approximations of belief-MDP reduced partially observable MDPS (POMDPs) with weak Feller continuity and a mild version of filter stability (which requires the knowledge of the model by the controller), (iii) finite window approximations of POMDPs under a uniform controlled filter stability (which does not require the knowledge of the model), and (iv) for multi-agent models where convergence of learning dynamics to a new class of equilibria, subjective Q-learning equilibria, will be studied. In addition to the convergence theorem, some implications of the theorem above are new to the literature and others are interpreted as applications of the convergence theorem. Some open problems are noted.
Convergence of Finite Memory Q-Learning for POMDPs and Near Optimality of Learned Policies under Filter Stability
Mar 22, 2021
In this paper, for POMDPs, we provide the convergence of a Q learning algorithm for control policies using a finite history of past observations and control actions, and, consequentially, we establish near optimality of such limit Q functions under explicit filter stability conditions. We present explicit error bounds relating the approximation error to the length of the finite history window. We establish the convergence of such Q-learning iterations under mild ergodicity assumptions on the state process during the exploration phase. We further show that the limit fixed point equation gives an optimal solution for an approximate belief-MDP. We then provide bounds on the performance of the policy obtained using the limit Q values compared to the performance of the optimal policy for the POMDP, where we also present explicit conditions using recent results on filter stability in controlled POMDPs. While there exist many experimental results, (i) the rigorous asymptotic convergence (to an approximate MDP value function) for such finite-memory Q-learning algorithms, and (ii) the near optimality with an explicit rate of convergence (in the memory size) are results that are new to the literature, to our knowledge.
Near Optimality of Finite Memory Feedback Policies in Partially Observed Markov Decision Processes
Oct 15, 2020



In the theory of Partially Observed Markov Decision Processes (POMDPs), existence of optimal policies have in general been established via converting the original partially observed stochastic control problem to a fully observed one on the belief space, leading to a belief-MDP. However, computing an optimal policy for this fully observed model, and so for the original POMDP, using classical dynamic or linear programming methods is challenging even if the original system has finite state and action spaces, since the state space of the fully observed belief-MDP model is always uncountable. Furthermore, there exist very few rigorous approximation results, as regularity conditions needed often require a tedious study involving the spaces of probability measures leading to properties such as Feller continuity. In this paper, we rigorously establish near optimality of finite window control policies in POMDPs under mild non-linear filter stability conditions and the assumption that the measurement and action sets are finite (and the state space is real vector valued). We also establish a rate of convergence result which relates the finite window memory size and the approximation error bound, where the rate of convergence is exponential under explicit and testable geometric filter stability conditions. While there exist many experimental results and few rigorous asymptotic convergence results, an explicit rate of convergence result is new in the literature, to our knowledge.