 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScenario theory for multi-criteria data-driven decision making
Apr 01, 2026The scenario approach provides a powerful data-driven framework for designing solutions under uncertainty with rigorous probabilistic robustness guarantees. Existing theory, however, primarily addresses assessing robustness with respect to a single appropriateness criterion for the solution based on a dataset, whereas many practical applications - including multi-agent decision problems - require the simultaneous consideration of multiple criteria and the assessment of their robustness based on multiple datasets, one per criterion. This paper develops a general scenario theory for multi-criteria data-driven decision making. A central innovation lies in the collective treatment of the risks associated with violations of individual criteria, which yields substantially more accurate robustness certificates than those derived from a naive application of standard results. In turn, this approach enables a sharper quantification of the robustness level with which all criteria are simultaneously satisfied. The proposed framework applies broadly to multi-criteria data-driven decision problems, providing a principled, scalable, and theoretically grounded methodology for design under uncertainty.
Scenario Approach with Post-Design Certification of User-Specified Properties
Feb 17, 2026The scenario approach is an established data-driven design framework that comes equipped with a powerful theory linking design complexity to generalization properties. In this approach, data are simultaneously used both for design and for certifying the design's reliability, without resorting to a separate test dataset. This paper takes a step further by guaranteeing additional properties, useful in post-design usage but not considered during the design phase. To this end, we introduce a two-level framework of appropriateness: baseline appropriateness, which guides the design process, and post-design appropriateness, which serves as a criterion for a posteriori evaluation. We provide distribution-free upper bounds on the risk of failing to meet the post-design appropriateness; these bounds are computable without using any additional test data. Under additional assumptions, lower bounds are also derived. As part of an effort to demonstrate the usefulness of the proposed methodology, the paper presents two practical examples in H2 and pole-placement problems. Moreover, a method is provided to infer comprehensive distributional knowledge of relevant performance indexes from the available dataset.
Risk Analysis and Design Against Adversarial Actions
May 02, 2025Learning models capable of providing reliable predictions in the face of adversarial actions has become a central focus of the machine learning community in recent years. This challenge arises from observing that data encountered at deployment time often deviate from the conditions under which the model was trained. In this paper, we address deployment-time adversarial actions and propose a versatile, well-principled framework to evaluate the model's robustness against attacks of diverse types and intensities. While we initially focus on Support Vector Regression (SVR), the proposed approach extends naturally to the broad domain of learning via relaxed optimization techniques. Our results enable an assessment of the model vulnerability without requiring additional test data and operate in a distribution-free setup. These results not only provide a tool to enhance trust in the model's applicability but also aid in selecting among competing alternatives. Later in the paper, we show that our findings also offer useful insights for establishing new results within the out-of-distribution framework.
Signed-Perturbed Sums Estimation of ARX Systems: Exact Coverage and Strong Consistency (Extended Version)
Feb 18, 2024



Sign-Perturbed Sums (SPS) is a system identification method that constructs confidence regions for the unknown system parameters. In this paper, we study SPS for ARX systems, and establish that the confidence regions are guaranteed to include the true model parameter with exact, user-chosen, probability under mild statistical assumptions, a property that holds true for any finite number of observed input-output data. Furthermore, we prove the strong consistency of the method, that is, as the number of data points increases, the confidence region gets smaller and smaller and will asymptotically almost surely exclude any parameter value different from the true one. In addition, we also show that, asymptotically, the SPS region is included in an ellipsoid which is marginally larger than the confidence ellipsoid obtained from the asymptotic theory of system identification. The results are theoretically proven and illustrated in a simulation example.
Estimation of Accurate and Calibrated Uncertainties in Deterministic models
Mar 11, 2020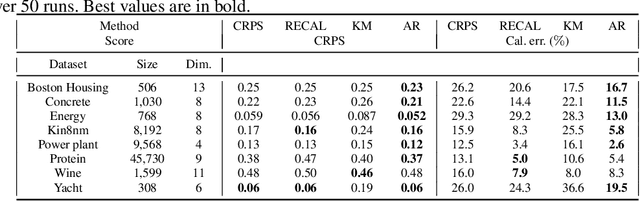
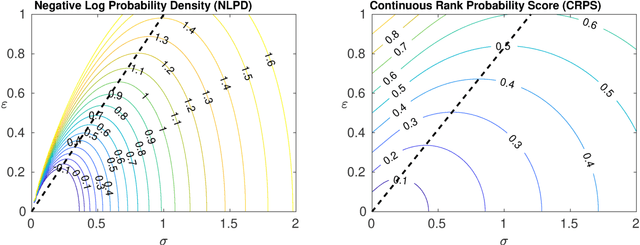
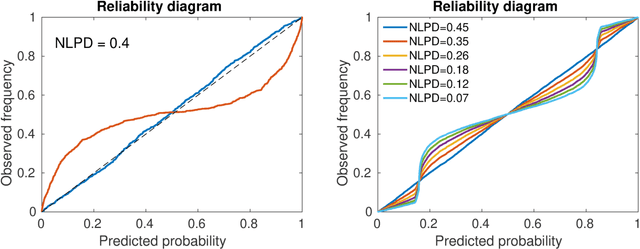
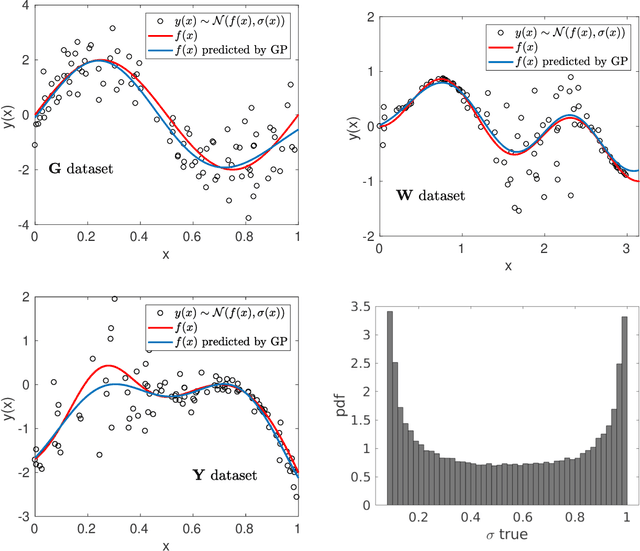
In this paper we focus on the problem of assigning uncertainties to single-point predictions generated by a deterministic model that outputs a continuous variable. This problem applies to any state-of-the-art physics or engineering models that have a computational cost that does not readily allow to run ensembles and to estimate the uncertainty associated to single-point predictions. Essentially, we devise a method to easily transform a deterministic prediction into a probabilistic one. We show that for doing so, one has to compromise between the accuracy and the reliability (calibration) of such a probabilistic model. Hence, we introduce a cost function that encodes their trade-off. We use the Continuous Rank Probability Score to measure accuracy and we derive an analytic formula for the reliability, in the case of forecasts of continuous scalar variables expressed in terms of Gaussian distributions. The new Accuracy-Reliability cost function is then used to estimate the input-dependent variance, given a black-box mean function, by solving a two-objective optimization problem. The simple philosophy behind this strategy is that predictions based on the estimated variances should not only be accurate, but also reliable (i.e. statistical consistent with observations). Conversely, early works based on the minimization of classical cost functions, such as the negative log probability density, cannot simultaneously enforce both accuracy and reliability. We show several examples both with synthetic data, where the underlying hidden noise can accurately be recovered, and with large real-world datasets.