 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLP-VRAIN UPV system for the IWSLT 2025 Simultaneous Speech Translation Translation task
Jun 23, 2025This work describes the participation of the MLLP-VRAIN research group in the shared task of the IWSLT 2025 Simultaneous Speech Translation track. Our submission addresses the unique challenges of real-time translation of long-form speech by developing a modular cascade system that adapts strong pre-trained models to streaming scenarios. We combine Whisper Large-V3-Turbo for ASR with the multilingual NLLB-3.3B model for MT, implementing lightweight adaptation techniques rather than training new end-to-end models from scratch. Our approach employs document-level adaptation with prefix training to enhance the MT model's ability to handle incomplete inputs, while incorporating adaptive emission policies including a wait-$k$ strategy and RALCP for managing the translation stream. Specialized buffer management techniques and segmentation strategies ensure coherent translations across long audio sequences. Experimental results on the ACL60/60 dataset demonstrate that our system achieves a favorable balance between translation quality and latency, with a BLEU score of 31.96 and non-computational-aware StreamLAAL latency of 2.94 seconds. Our final model achieves a preliminary score on the official test set (IWSLT25Instruct) of 29.8 BLEU. Our work demonstrates that carefully adapted pre-trained components can create effective simultaneous translation systems for long-form content without requiring extensive in-domain parallel data or specialized end-to-end training.
HOFT: Householder Orthogonal Fine-tuning
May 22, 2025Adaptation of foundation models using low-rank methods is a widespread approach. Another way to adapt these models is to employ orthogonal fine-tuning methods, which are less time and memory efficient despite their good generalization properties. In this work, we propose Householder Orthogonal Fine-tuning (HOFT), a novel orthogonal fine-tuning method that aims to alleviate time and space complexity. Moreover, some theoretical properties of the orthogonal fine-tuning paradigm are explored. From this exploration, Scaled Householder Orthogonal Fine-tuning (SHOFT) is proposed. Both HOFT and SHOFT are evaluated in downstream tasks, namely commonsense reasoning, machine translation, subject-driven generation and mathematical reasoning. Compared with state-of-the-art adaptation methods, HOFT and SHOFT show comparable or better results.
Segmentation-Free Streaming Machine Translation
Sep 26, 2023Streaming Machine Translation (MT) is the task of translating an unbounded input text stream in real-time. The traditional cascade approach, which combines an Automatic Speech Recognition (ASR) and an MT system, relies on an intermediate segmentation step which splits the transcription stream into sentence-like units. However, the incorporation of a hard segmentation constrains the MT system and is a source of errors. This paper proposes a Segmentation-Free framework that enables the model to translate an unsegmented source stream by delaying the segmentation decision until the translation has been generated. Extensive experiments show how the proposed Segmentation-Free framework has better quality-latency trade-off than competing approaches that use an independent segmentation model. Software, data and models will be released upon paper acceptance.
From Simultaneous to Streaming Machine Translation by Leveraging Streaming History
Mar 31, 2022


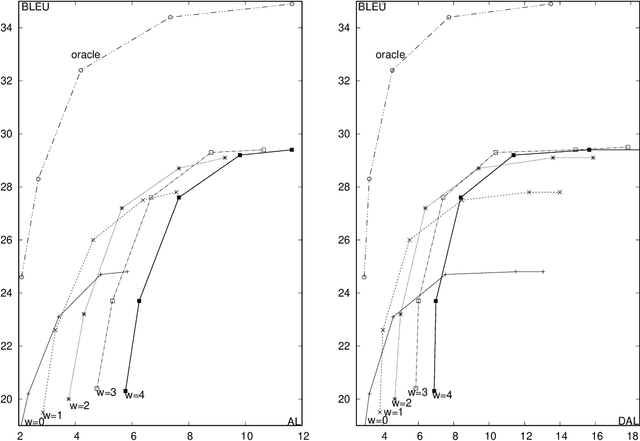
Simultaneous Machine Translation is the task of incrementally translating an input sentence before it is fully available. Currently, simultaneous translation is carried out by translating each sentence independently of the previously translated text. More generally, Streaming MT can be understood as an extension of Simultaneous MT to the incremental translation of a continuous input text stream. In this work, a state-of-the-art simultaneous sentence-level MT system is extended to the streaming setup by leveraging the streaming history. Extensive empirical results are reported on IWSLT Translation Tasks, showing that leveraging the streaming history leads to significant quality gains. In particular, the proposed system proves to compare favorably to the best performing systems.
VRAIN-UPV MLLP's system for the Blizzard Challenge 2021
Oct 29, 2021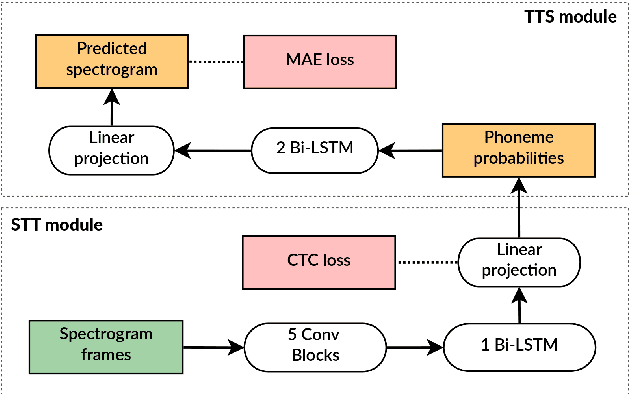


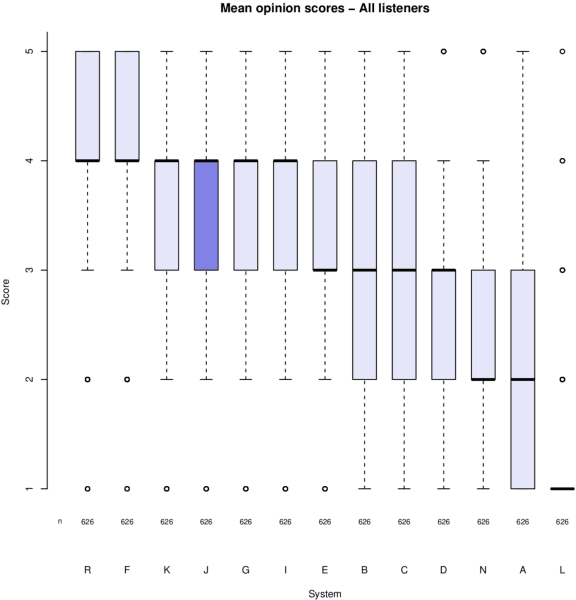
This paper presents the VRAIN-UPV MLLP's speech synthesis system for the SH1 task of the Blizzard Challenge 2021. The SH1 task consisted in building a Spanish text-to-speech system trained on (but not limited to) the corpus released by the Blizzard Challenge 2021 organization. It included 5 hours of studio-quality recordings from a native Spanish female speaker. In our case, this dataset was solely used to build a two-stage neural text-to-speech pipeline composed of a non-autoregressive acoustic model with explicit duration modeling and a HiFi-GAN neural vocoder. Our team is identified as J in the evaluation results. Our system obtained very good results in the subjective evaluation tests. Only one system among other 11 participants achieved better naturalness than ours. Concretely, it achieved a naturalness MOS of 3.61 compared to 4.21 for real samples.
Stream-level Latency Evaluation for Simultaneous Machine Translation
Apr 18, 2021
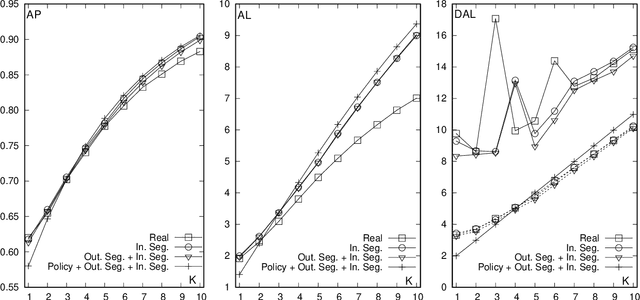
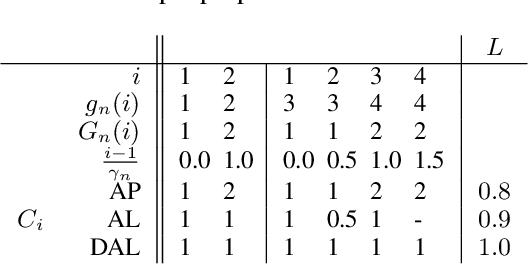
Simultaneous machine translation has recently gained traction thanks to significant quality improvements and the advent of streaming applications. Simultaneous translation systems need to find a trade-off between translation quality and response time, and with this purpose multiple latency measures have been proposed. However, latency evaluations for simultaneous translation are estimated at the sentence level, not taking into account the sequential nature of a streaming scenario. Indeed, these sentence-level latency measures are not well suited for continuous stream translation resulting in figures that are not coherent with the simultaneous translation policy of the system being assessed. This work proposes a stream-level adaptation of the current latency measures based on a re-segmentation approach applied to the output translation, that is successfully evaluated on streaming conditions for a reference IWSLT task.
Europarl-ST: A Multilingual Corpus For Speech Translation Of Parliamentary Debates
Nov 08, 2019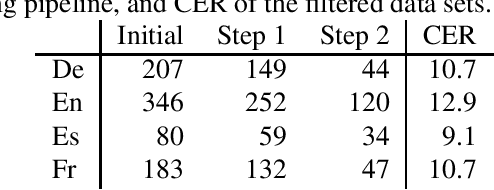
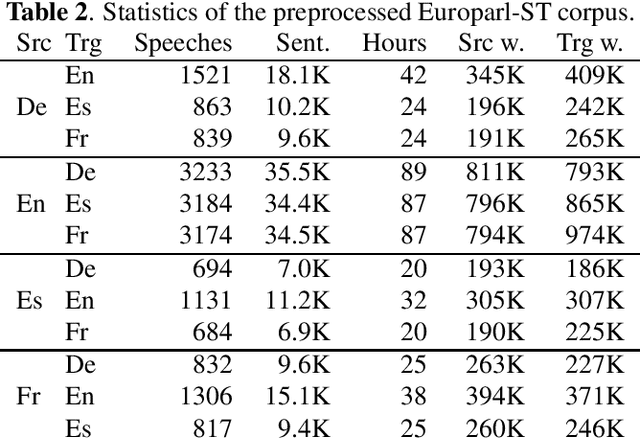
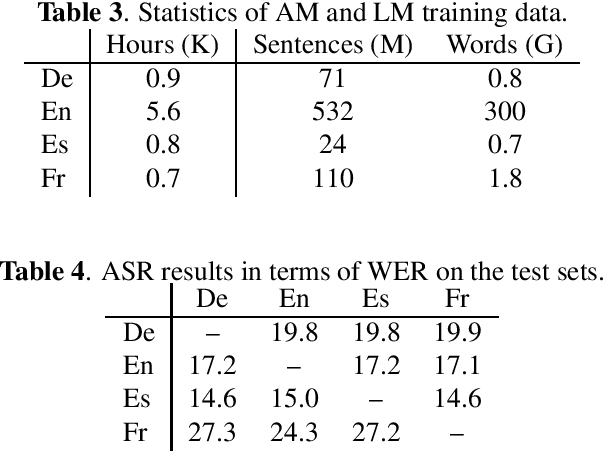
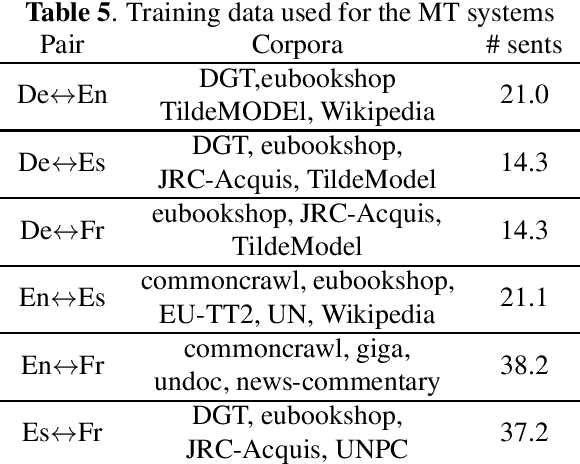
Current research into spoken language translation (SLT) is often hampered by the lack of specific data resources for this task, as currently available SLT datasets are restricted to a limited set of language pairs. In this paper we present Europarl-ST, a novel multilingual SLT corpus containing paired audio-text samples for SLT from and into 6 European languages, for a total of 30 different translation directions. This corpus has been compiled using the debates held in the European Parliament in the period between 2008 and 2012. This paper describes the corpus creation process and presents a series of automatic speech recognition, machine translation and spoken language translation experiments that highlight the potential of this new resource. The corpus is released under a Creative Commons license and is freely accessible and downloadable.