 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing to Translate: The Effectiveness of Speech Modality Integration into LLMs
Dec 24, 2025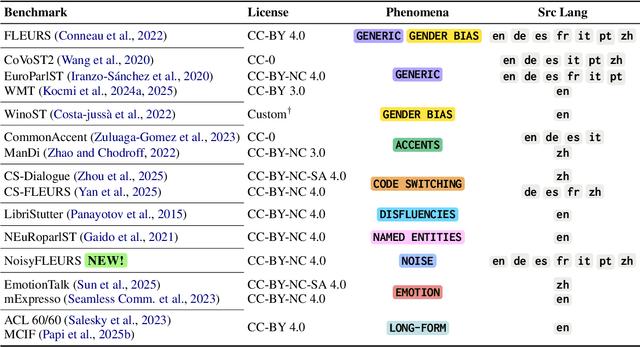
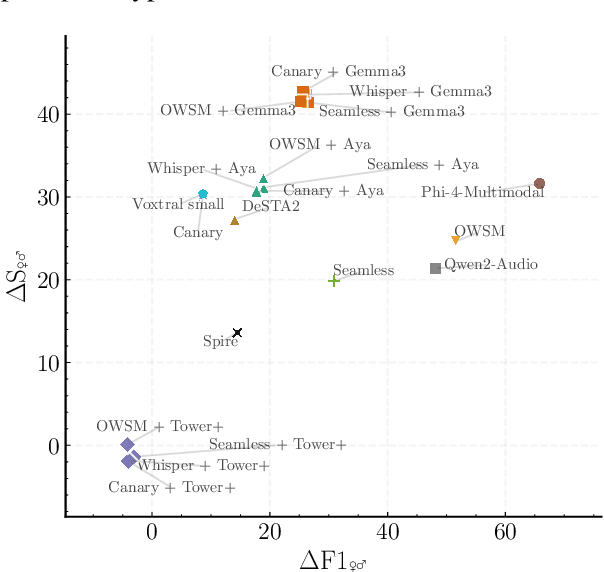
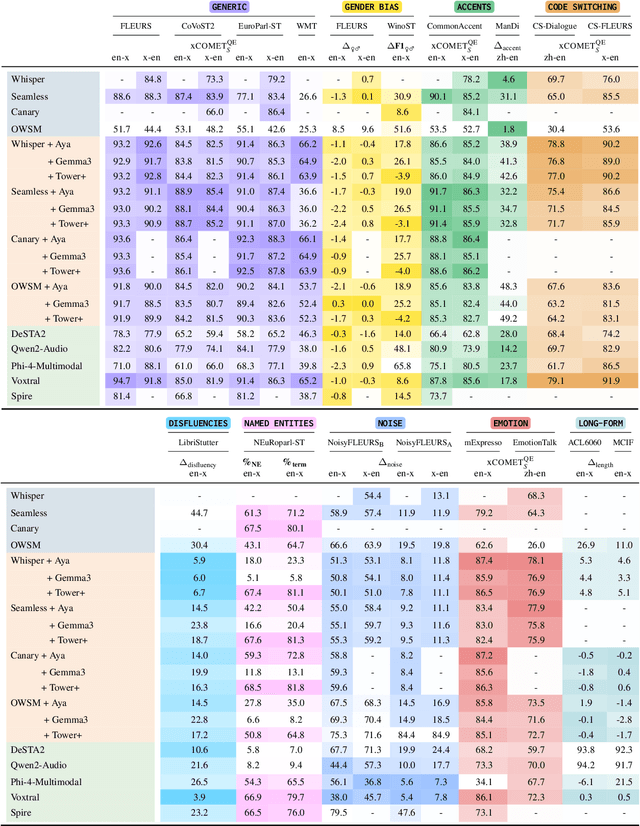
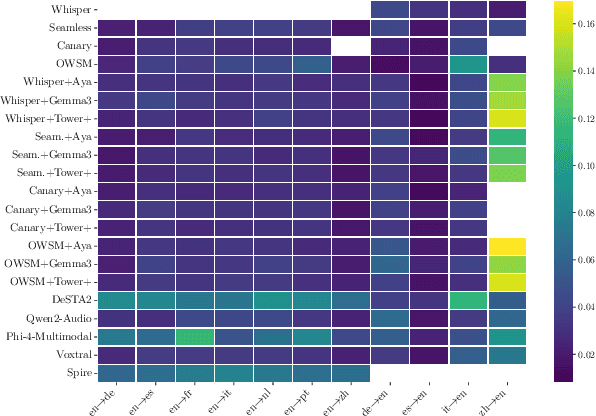
As Large Language Models (LLMs) expand beyond text, integrating speech as a native modality has given rise to SpeechLLMs, which aim to translate spoken language directly, thereby bypassing traditional transcription-based pipelines. Whether this integration improves speech-to-text translation quality over established cascaded architectures, however, remains an open question. We present Hearing to Translate, the first comprehensive test suite rigorously benchmarking 5 state-of-the-art SpeechLLMs against 16 strong direct and cascade systems that couple leading speech foundation models (SFM), with multilingual LLMs. Our analysis spans 16 benchmarks, 13 language pairs, and 9 challenging conditions, including disfluent, noisy, and long-form speech. Across this extensive evaluation, we find that cascaded systems remain the most reliable overall, while current SpeechLLMs only match cascades in selected settings and SFMs lag behind both, highlighting that integrating an LLM, either within the model or in a pipeline, is essential for high-quality speech translation.
MLLP-VRAIN UPV system for the IWSLT 2025 Simultaneous Speech Translation Translation task
Jun 23, 2025This work describes the participation of the MLLP-VRAIN research group in the shared task of the IWSLT 2025 Simultaneous Speech Translation track. Our submission addresses the unique challenges of real-time translation of long-form speech by developing a modular cascade system that adapts strong pre-trained models to streaming scenarios. We combine Whisper Large-V3-Turbo for ASR with the multilingual NLLB-3.3B model for MT, implementing lightweight adaptation techniques rather than training new end-to-end models from scratch. Our approach employs document-level adaptation with prefix training to enhance the MT model's ability to handle incomplete inputs, while incorporating adaptive emission policies including a wait-$k$ strategy and RALCP for managing the translation stream. Specialized buffer management techniques and segmentation strategies ensure coherent translations across long audio sequences. Experimental results on the ACL60/60 dataset demonstrate that our system achieves a favorable balance between translation quality and latency, with a BLEU score of 31.96 and non-computational-aware StreamLAAL latency of 2.94 seconds. Our final model achieves a preliminary score on the official test set (IWSLT25Instruct) of 29.8 BLEU. Our work demonstrates that carefully adapted pre-trained components can create effective simultaneous translation systems for long-form content without requiring extensive in-domain parallel data or specialized end-to-end training.
Segmentation-Free Streaming Machine Translation
Sep 26, 2023Streaming Machine Translation (MT) is the task of translating an unbounded input text stream in real-time. The traditional cascade approach, which combines an Automatic Speech Recognition (ASR) and an MT system, relies on an intermediate segmentation step which splits the transcription stream into sentence-like units. However, the incorporation of a hard segmentation constrains the MT system and is a source of errors. This paper proposes a Segmentation-Free framework that enables the model to translate an unsegmented source stream by delaying the segmentation decision until the translation has been generated. Extensive experiments show how the proposed Segmentation-Free framework has better quality-latency trade-off than competing approaches that use an independent segmentation model. Software, data and models will be released upon paper acceptance.