 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOFT: Householder Orthogonal Fine-tuning
May 22, 2025Adaptation of foundation models using low-rank methods is a widespread approach. Another way to adapt these models is to employ orthogonal fine-tuning methods, which are less time and memory efficient despite their good generalization properties. In this work, we propose Householder Orthogonal Fine-tuning (HOFT), a novel orthogonal fine-tuning method that aims to alleviate time and space complexity. Moreover, some theoretical properties of the orthogonal fine-tuning paradigm are explored. From this exploration, Scaled Householder Orthogonal Fine-tuning (SHOFT) is proposed. Both HOFT and SHOFT are evaluated in downstream tasks, namely commonsense reasoning, machine translation, subject-driven generation and mathematical reasoning. Compared with state-of-the-art adaptation methods, HOFT and SHOFT show comparable or better results.
VRAIN-UPV MLLP's system for the Blizzard Challenge 2021
Oct 29, 2021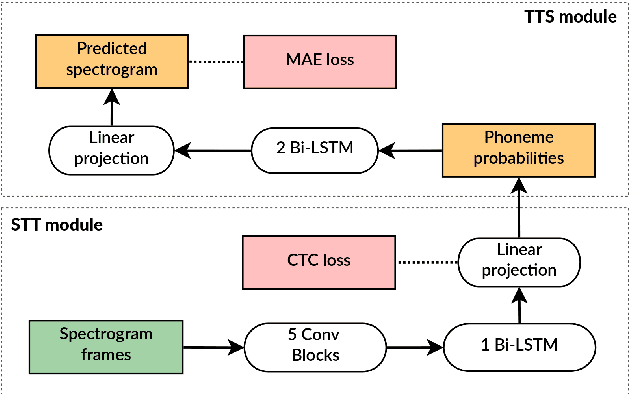


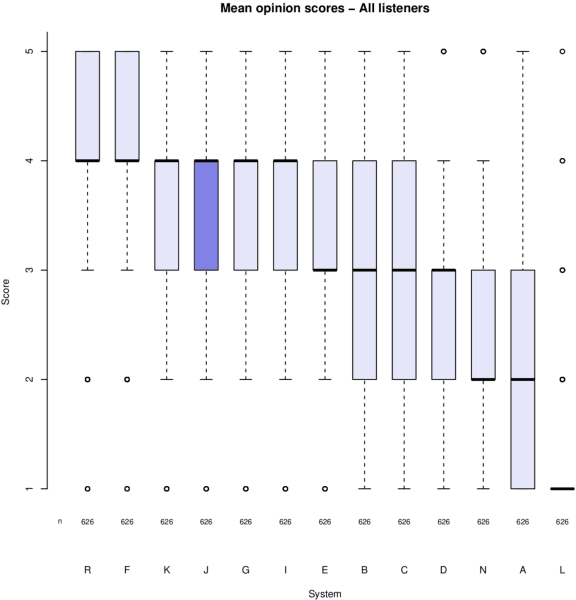
This paper presents the VRAIN-UPV MLLP's speech synthesis system for the SH1 task of the Blizzard Challenge 2021. The SH1 task consisted in building a Spanish text-to-speech system trained on (but not limited to) the corpus released by the Blizzard Challenge 2021 organization. It included 5 hours of studio-quality recordings from a native Spanish female speaker. In our case, this dataset was solely used to build a two-stage neural text-to-speech pipeline composed of a non-autoregressive acoustic model with explicit duration modeling and a HiFi-GAN neural vocoder. Our team is identified as J in the evaluation results. Our system obtained very good results in the subjective evaluation tests. Only one system among other 11 participants achieved better naturalness than ours. Concretely, it achieved a naturalness MOS of 3.61 compared to 4.21 for real samples.
Europarl-ST: A Multilingual Corpus For Speech Translation Of Parliamentary Debates
Nov 08, 2019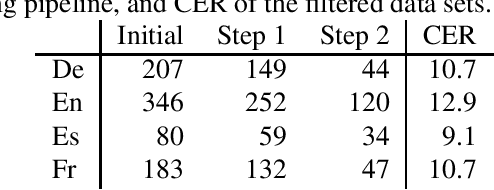
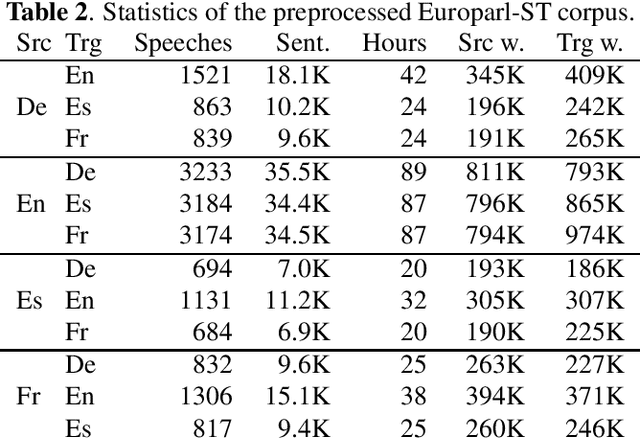
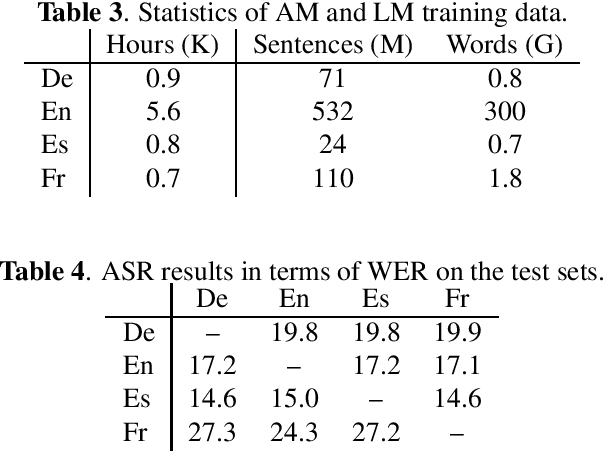
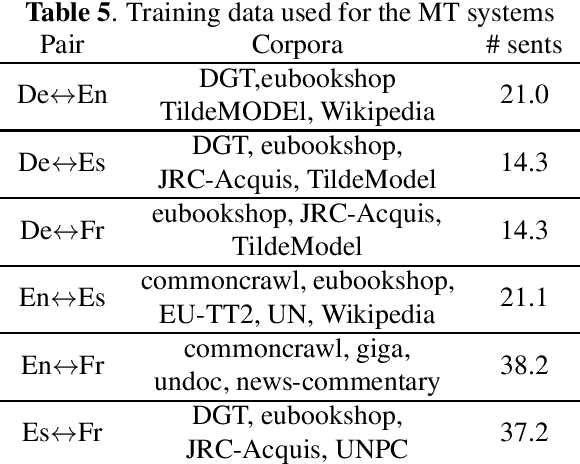
Current research into spoken language translation (SLT) is often hampered by the lack of specific data resources for this task, as currently available SLT datasets are restricted to a limited set of language pairs. In this paper we present Europarl-ST, a novel multilingual SLT corpus containing paired audio-text samples for SLT from and into 6 European languages, for a total of 30 different translation directions. This corpus has been compiled using the debates held in the European Parliament in the period between 2008 and 2012. This paper describes the corpus creation process and presents a series of automatic speech recognition, machine translation and spoken language translation experiments that highlight the potential of this new resource. The corpus is released under a Creative Commons license and is freely accessible and downloadable.