 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Collaborative Framework for High-Definition Mapping
Oct 14, 2019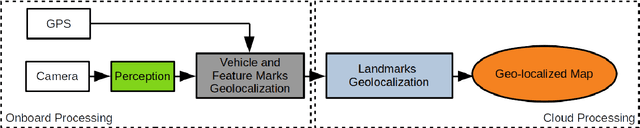
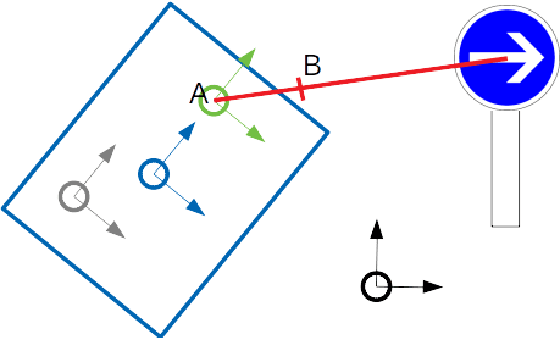
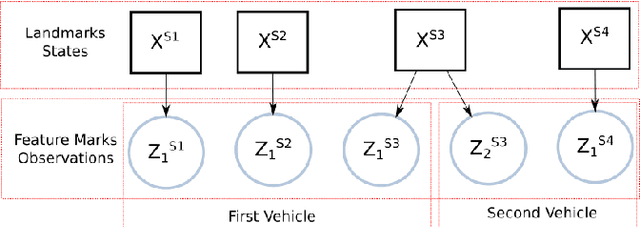
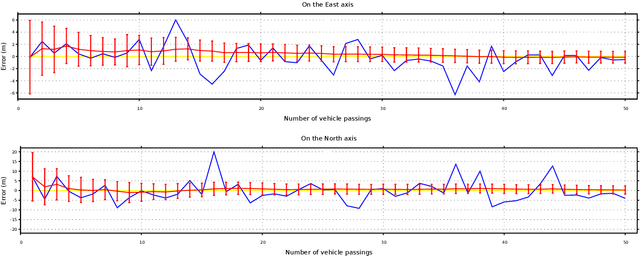
For connected vehicles to have a substantial effect on road safety, it is required that accurate positions and trajectories can be shared. To this end, all vehicles must be accurately geo-localized in a common frame. This can be achieved by merging GNSS (Global Navigation Satellite System) information and visual observations matched with a map of geo-positioned landmarks. Building such a map remains a challenge, and current solutions are facing strong cost-related limitations. We present a collaborative framework for high-definition mapping, in which vehicles equipped with standard sensors, such as a GNSS receiver and a mono-visual camera, update a map of geo-localized landmarks. Our system is composed of two processing blocks: the first one is embedded in each vehicle, and aims at geo-localizing the vehicle and the detected feature marks. The second is operated on cloud servers, and uses observations from all the vehicles to compute updates for the map of geo-positioned landmarks. As the map's landmarks are detected and positioned by more and more vehicles, the accuracy of the map increases, eventually converging in probability towards a null error. The landmarks' geo-positions are estimated in a stable and scalable way, enabling to provide dynamic map updates in an automatic manner.
* 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Fuzzy Gesture Expression Model for an Interactive and Safe Robot Partner
Sep 26, 2019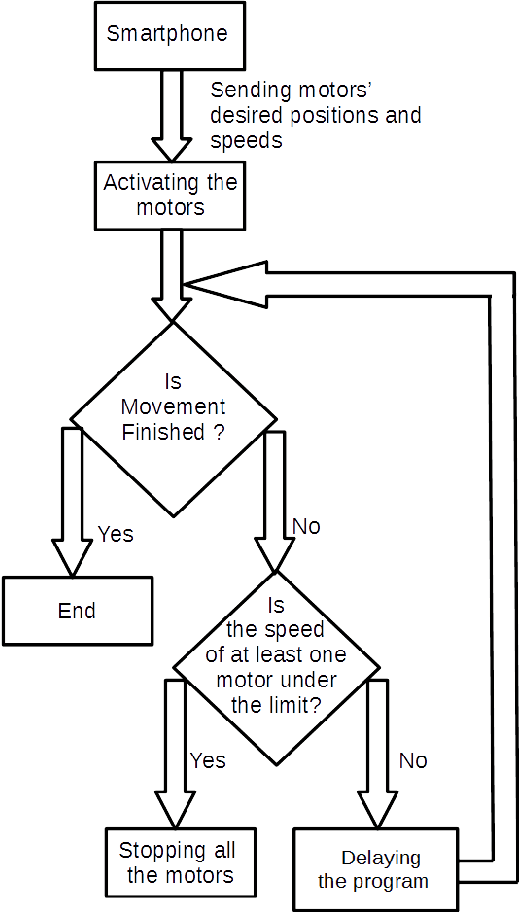
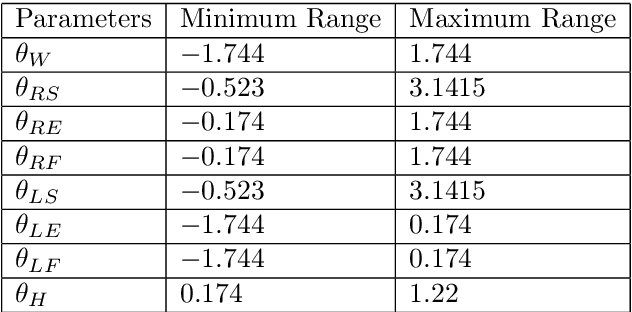
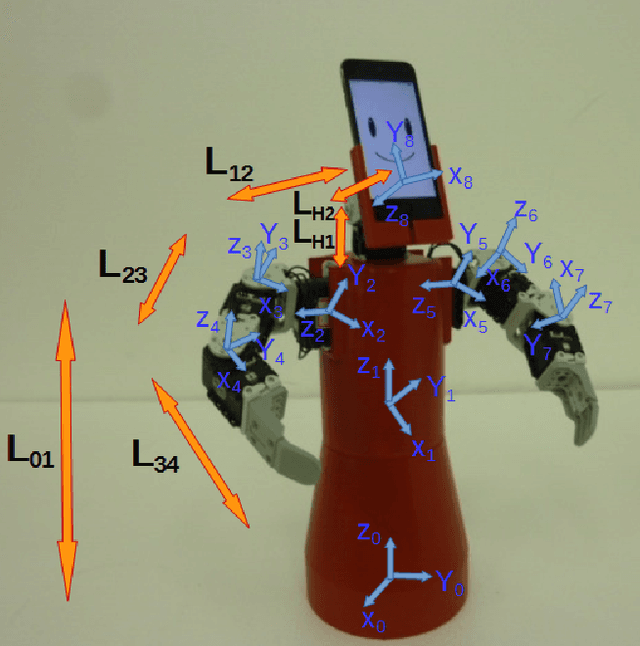
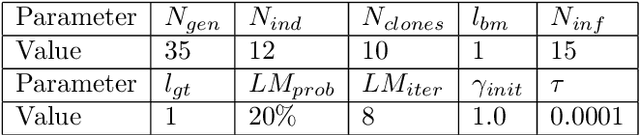
Interaction with a robot partner requires many elements, including not only speech but also embodiment. Thus, gestural and facial expressions are important for communication. Furthermore, understanding human movements is essential for safe and natural interchange. This paper proposes an interactive fuzzy emotional model for the robot partner's gesture expression, following its facial emotional model. First, we describe the physical interaction between the user and its robot partner. Next, we propose a kinematic model for the robot partner based on the Denavit-Hartenberg convention and solve the inverse kinematic transformation through Bacterial Memetic Algorithm. Then, the emotional model along its interactivity with the user is discussed. Finally, we show experimental results of the proposed model.
* 11 pages, 8 figures, accepted for publication in Journal of Network Intelligence