 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass Anchor Margin Loss for Content-Based Image Retrieval
Jun 03, 2023The performance of neural networks in content-based image retrieval (CBIR) is highly influenced by the chosen loss (objective) function. The majority of objective functions for neural models can be divided into metric learning and statistical learning. Metric learning approaches require a pair mining strategy that often lacks efficiency, while statistical learning approaches are not generating highly compact features due to their indirect feature optimization. To this end, we propose a novel repeller-attractor loss that falls in the metric learning paradigm, yet directly optimizes for the L2 metric without the need of generating pairs. Our loss is formed of three components. One leading objective ensures that the learned features are attracted to each designated learnable class anchor. The second loss component regulates the anchors and forces them to be separable by a margin, while the third objective ensures that the anchors do not collapse to zero. Furthermore, we develop a more efficient two-stage retrieval system by harnessing the learned class anchors during the first stage of the retrieval process, eliminating the need of comparing the query with every image in the database. We establish a set of four datasets (CIFAR-100, Food-101, SVHN, and Tiny ImageNet) and evaluate the proposed objective in the context of few-shot and full-set training on the CBIR task, by using both convolutional and transformer architectures. Compared to existing objective functions, our empirical evidence shows that the proposed objective is generating superior and more consistent results.
Multi-layer Optimizations for End-to-End Data Analytics
Jan 10, 2020
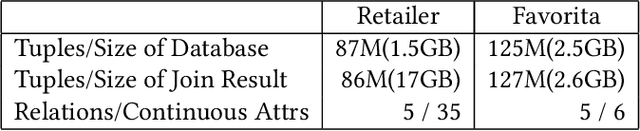
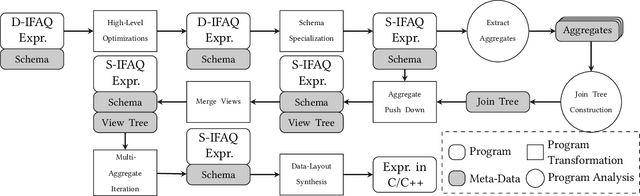

We consider the problem of training machine learning models over multi-relational data. The mainstream approach is to first construct the training dataset using a feature extraction query over input database and then use a statistical software package of choice to train the model. In this paper we introduce Iterative Functional Aggregate Queries (IFAQ), a framework that realizes an alternative approach. IFAQ treats the feature extraction query and the learning task as one program given in the IFAQ's domain-specific language, which captures a subset of Python commonly used in Jupyter notebooks for rapid prototyping of machine learning applications. The program is subject to several layers of IFAQ optimizations, such as algebraic transformations, loop transformations, schema specialization, data layout optimizations, and finally compilation into efficient low-level C++ code specialized for the given workload and data. We show that a Scala implementation of IFAQ can outperform mlpack, Scikit, and TensorFlow by several orders of magnitude for linear regression and regression tree models over several relational datasets.