 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Text Sentiment Analysis: Reinforcing Human-Performed Surveys with Wider Topic Analysis
Mar 04, 2024



Sentiment analysis (SA) has been, and is still, a thriving research area. However, the task of Arabic sentiment analysis (ASA) is still underrepresented in the body of research. This study offers the first in-depth and in-breadth analysis of existing ASA studies of textual content and identifies their common themes, domains of application, methods, approaches, technologies and algorithms used. The in-depth study manually analyses 133 ASA papers published in the English language between 2002 and 2020 from four academic databases (SAGE, IEEE, Springer, WILEY) and from Google Scholar. The in-breadth study uses modern, automatic machine learning techniques, such as topic modelling and temporal analysis, on Open Access resources, to reinforce themes and trends identified by the prior study, on 2297 ASA publications between 2010-2020. The main findings show the different approaches used for ASA: machine learning, lexicon-based and hybrid approaches. Other findings include ASA 'winning' algorithms (SVM, NB, hybrid methods). Deep learning methods, such as LSTM can provide higher accuracy, but for ASA sometimes the corpora are not large enough to support them. Additionally, whilst there are some ASA corpora and lexicons, more are required. Specifically, Arabic tweets corpora and datasets are currently only moderately sized. Moreover, Arabic lexicons that have high coverage contain only Modern Standard Arabic (MSA) words, and those with Arabic dialects are quite small. Thus, new corpora need to be created. On the other hand, ASA tools are stringently lacking. There is a need to develop ASA tools that can be used in industry, as well as in academia, for Arabic text SA. Hence, our study offers insights into the challenges associated with ASA research and provides suggestions for ways to move the field forward such as lack of Dialectical Arabic resource, Arabic tweets, corpora and data sets for SA.
Social Interactions Clustering MOOC Students: An Exploratory Study
Aug 10, 2020
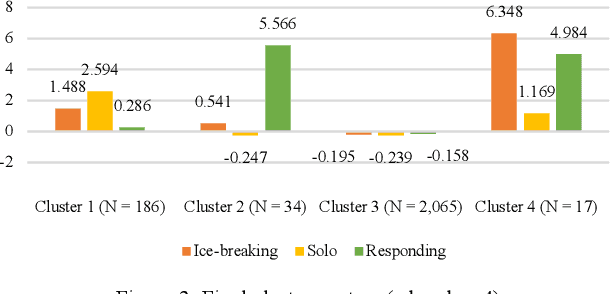


An exploratory study on social interactions of MOOC students in FutureLearn was conducted, to answer "how can we cluster students based on their social interactions?" Comments were categorized based on how students interacted with them, e.g., how a student's comment received replies from peers. Statistical modelling and machine learning were used to analyze comment categorization, resulting in 3 strong and stable clusters.
Hybrid Sequential Recommender via Time-aware Attentive Memory Network
May 18, 2020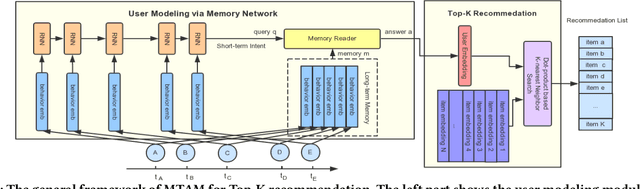


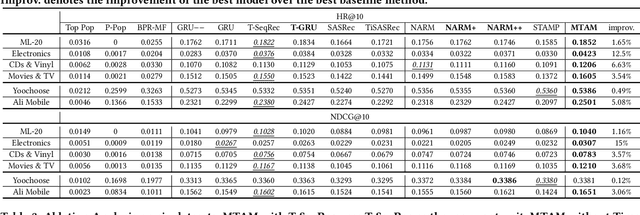
Recommendation systems aim to assist users to discover most preferred contents from an ever-growing corpus of items. Although recommenders have been greatly improved by deep learning, they still faces several challenges: (1) Behaviors are much more complex than words in sentences, so traditional attentive and recurrent models may fail in capturing the temporal dynamics of user preferences. (2) The preferences of users are multiple and evolving, so it is difficult to integrate long-term memory and short-term intent. In this paper, we propose a temporal gating methodology to improve attention mechanism and recurrent units, so that temporal information can be considered in both information filtering and state transition. Additionally, we propose a Multi-hop Time-aware Attentive Memory network (MTAM) to integrate long-term and short-term preferences. We use the proposed time-aware GRU network to learn the short-term intent and maintain prior records in user memory. We treat the short-term intent as a query and design a multi-hop memory reading operation via the proposed time-aware attention to generate user representation based on the current intent and long-term memory. Our approach is scalable for candidate retrieval tasks and can be viewed as a non-linear generalization of latent factorization for dot-product based Top-K recommendation. Finally, we conduct extensive experiments on six benchmark datasets and the experimental results demonstrate the effectiveness of our MTAM and temporal gating methodology.