 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss-Conditional PINNs for Parametric PDE Families
Jun 03, 2026Physics-informed neural networks (PINNs) approximate solutions of ODEs and PDEs by minimising a weighted combination of residual, boundary, initial, and data losses. Their performance is often dominated by the choice of loss weights: a poor weighting can drive training to a degenerate solution in which one physical constraint is satisfied while another is ignored. Existing methods select or adapt a single good set of weights. We take a different view: instead of tuning one weight vector, we explore the entire weight space during training. We introduce LC-PINN, which adapts the loss-conditional training of Dosovitskiy and Djolonga (2020) to the PDE-residual setting: the conditioning vector (either the loss weights or a scalar physical coefficient) is treated as a network input and sampled from a simple prior at every optimisation step. This turns PINN training into learning a continuous family of solutions indexed by that vector, with no solver-generated paired data. LC-PINN thus lies between classical PINNs and operator learning: it stays fully physics-informed but amortises training over a parametric family. Our contribution is not the loss-conditional construction itself, but its extension to PINNs, the unification of the loss-weight and parametric-coefficient regimes under one architecture (concatenation for loss weights, FiLM for coefficients), and a fixed-quadrature L-BFGS finishing protocol that makes the parametric-coefficient regime trainable. We give a lambda-invariance result for the conditional optimum and study LC-PINN on parametric Helmholtz, Schrodinger, viscous Burgers, and Buckley-Leverett equations. A single LC-PINN matches or improves retrained per-weight PINN baselines while parameterising the full family in one model, at a total cost that amortises favourably against per-instance retraining.
Digital Fingerprinting of Microstructures
Mar 25, 2022



Finding efficient means of fingerprinting microstructural information is a critical step towards harnessing data-centric machine learning approaches. A statistical framework is systematically developed for compressed characterisation of a population of images, which includes some classical computer vision methods as special cases. The focus is on materials microstructure. The ultimate purpose is to rapidly fingerprint sample images in the context of various high-throughput design/make/test scenarios. This includes, but is not limited to, quantification of the disparity between microstructures for quality control, classifying microstructures, predicting materials properties from image data and identifying potential processing routes to engineer new materials with specific properties. Here, we consider microstructure classification and utilise the resulting features over a range of related machine learning tasks, namely supervised, semi-supervised, and unsupervised learning. The approach is applied to two distinct datasets to illustrate various aspects and some recommendations are made based on the findings. In particular, methods that leverage transfer learning with convolutional neural networks (CNNs), pretrained on the ImageNet dataset, are generally shown to outperform other methods. Additionally, dimensionality reduction of these CNN-based fingerprints is shown to have negligible impact on classification accuracy for the supervised learning approaches considered. In situations where there is a large dataset with only a handful of images labelled, graph-based label propagation to unlabelled data is shown to be favourable over discarding unlabelled data and performing supervised learning. In particular, label propagation by Poisson learning is shown to be highly effective at low label rates.
Optimal Bayesian experimental design for subsurface flow problems
Aug 10, 2020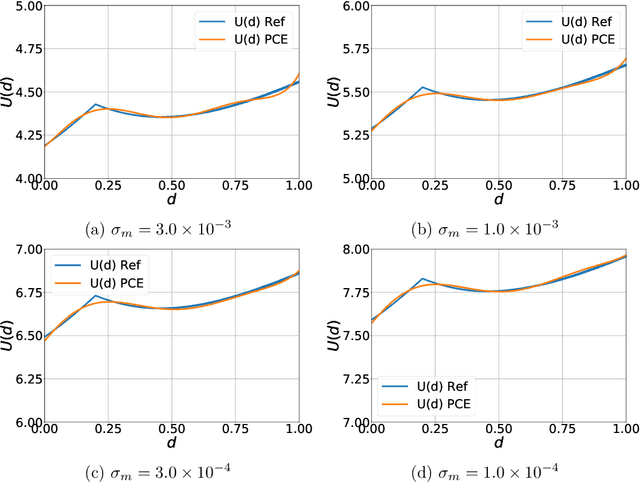
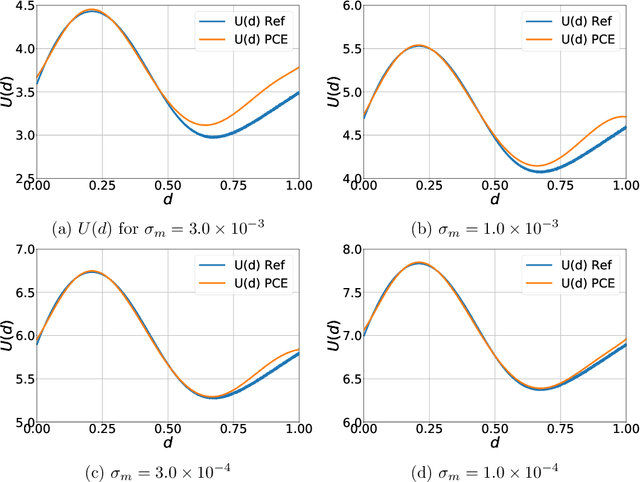
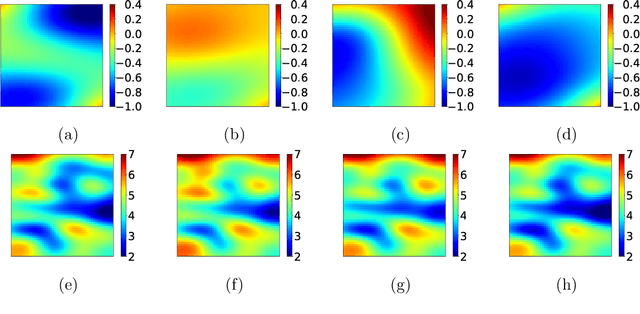
Optimal Bayesian design techniques provide an estimate for the best parameters of an experiment in order to maximize the value of measurements prior to the actual collection of data. In other words, these techniques explore the space of possible observations and determine an experimental setup that produces maximum information about the system parameters on average. Generally, optimal Bayesian design formulations result in multiple high-dimensional integrals that are difficult to evaluate without incurring significant computational costs as each integration point corresponds to solving a coupled system of partial differential equations. In the present work, we propose a novel approach for development of polynomial chaos expansion (PCE) surrogate model for the design utility function. In particular, we demonstrate how the orthogonality of PCE basis polynomials can be utilized in order to replace the expensive integration over the space of possible observations by direct construction of PCE approximation for the expected information gain. This novel technique enables the derivation of a reasonable quality response surface for the targeted objective function with a computational budget comparable to several single-point evaluations. Therefore, the proposed technique reduces dramatically the overall cost of optimal Bayesian experimental design. We evaluate this alternative formulation utilizing PCE on few numerical test cases with various levels of complexity to illustrate the computational advantages of the proposed approach.
* 30 pages, 9 figures. Published in Computer Methods in Applied Mechanics and Engineering