 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised PCA: A Multiobjective Approach
Nov 10, 2020
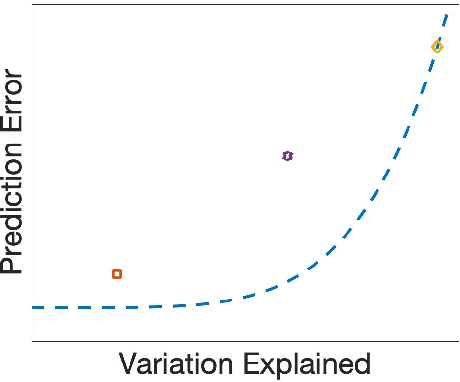
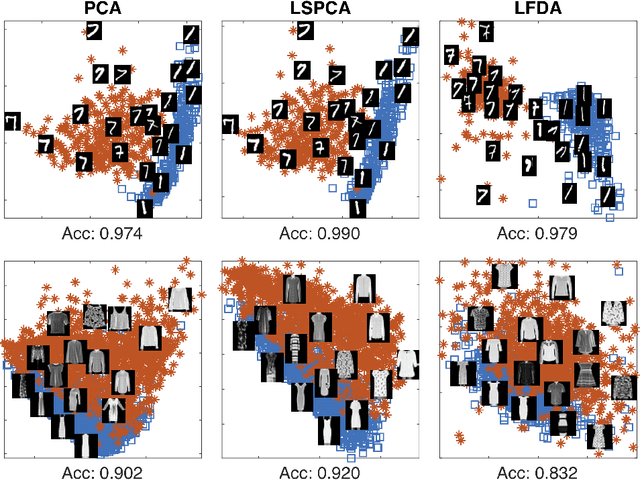
Methods for supervised principal component analysis (SPCA) aim to incorporate label information into principal component analysis (PCA), so that the extracted features are more useful for a prediction task of interest. Prior work on SPCA has focused primarily on optimizing prediction error, and has neglected the value of maximizing variance explained by the extracted features. We propose a new method for SPCA that addresses both of these objectives jointly, and demonstrate empirically that our approach dominates existing approaches, i.e., outperforms them with respect to both prediction error and variation explained. Our approach accommodates arbitrary supervised learning losses and, through a statistical reformulation, provides a novel low-rank extension of generalized linear models.
Consistent Estimation of Identifiable Nonparametric Mixture Models from Grouped Observations
Jun 12, 2020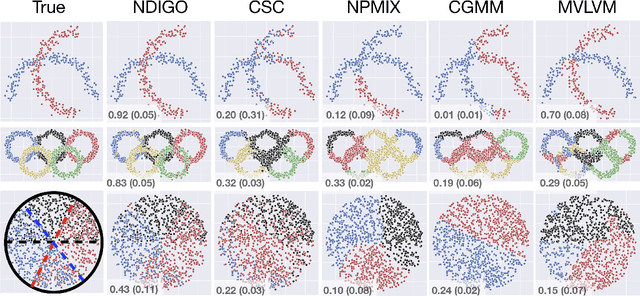
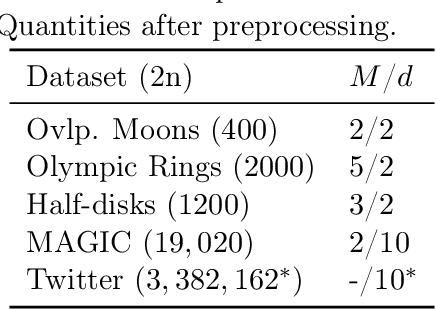


Recent research has established sufficient conditions for finite mixture models to be identifiable from grouped observations. These conditions allow the mixture components to be nonparametric and have substantial (or even total) overlap. This work proposes an algorithm that consistently estimates any identifiable mixture model from grouped observations. Our analysis leverages an oracle inequality for weighted kernel density estimators of the distribution on groups, together with a general result showing that consistent estimation of the distribution on groups implies consistent estimation of mixture components. A practical implementation is provided for paired observations, and the approach is shown to outperform existing methods, especially when mixture components overlap significantly.