 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERMAS: Becoming Robust to Reward Function Sim-to-Real Gaps in Multi-Agent Simulations
Jun 10, 2021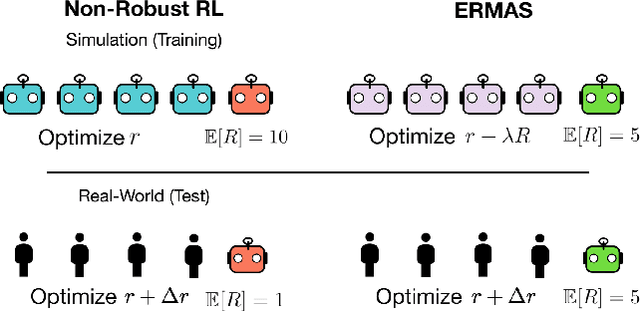


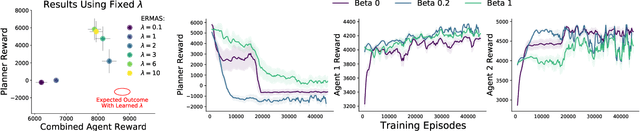
Multi-agent simulations provide a scalable environment for learning policies that interact with rational agents. However, such policies may fail to generalize to the real-world where agents may differ from simulated counterparts due to unmodeled irrationality and misspecified reward functions. We introduce Epsilon-Robust Multi-Agent Simulation (ERMAS), a robust optimization framework for learning AI policies that are robust to such multiagent sim-to-real gaps. While existing notions of multi-agent robustness concern perturbations in the actions of agents, we address a novel robustness objective concerning perturbations in the reward functions of agents. ERMAS provides this robustness by anticipating suboptimal behaviors from other agents, formalized as the worst-case epsilon-equilibrium. We show empirically that ERMAS yields robust policies for repeated bimatrix games and optimal taxation problems in economic simulations. In particular, in the two-level RL problem posed by the AI Economist (Zheng et al., 2020) ERMAS learns tax policies that are robust to changes in agent risk aversion, improving social welfare by up to 15% in complex spatiotemporal simulations.