 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Energy Projective Simulation (FEPS): Active inference with interpretability
Nov 22, 2024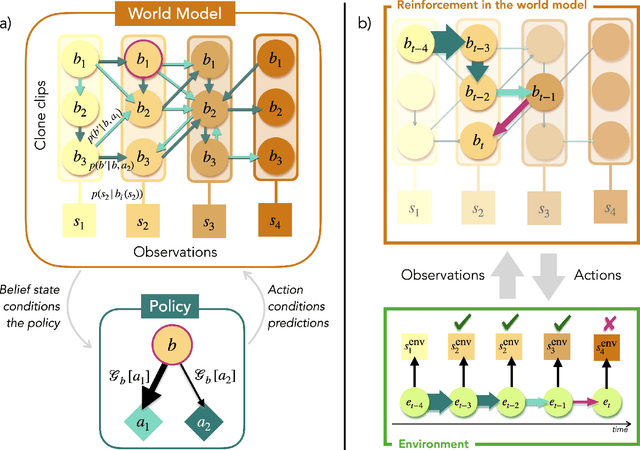

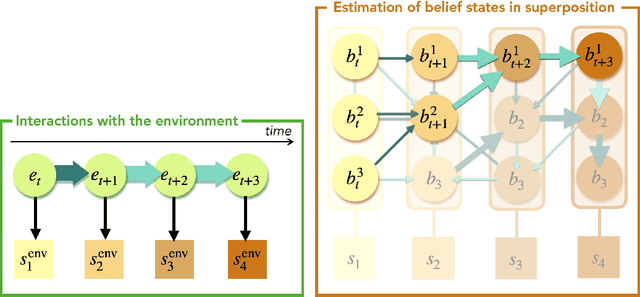
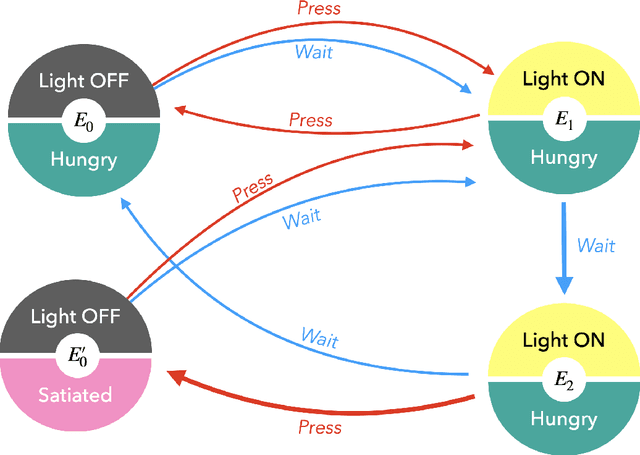
In the last decade, the free energy principle (FEP) and active inference (AIF) have achieved many successes connecting conceptual models of learning and cognition to mathematical models of perception and action. This effort is driven by a multidisciplinary interest in understanding aspects of self-organizing complex adaptive systems, including elements of agency. Various reinforcement learning (RL) models performing active inference have been proposed and trained on standard RL tasks using deep neural networks. Recent work has focused on improving such agents' performance in complex environments by incorporating the latest machine learning techniques. In this paper, we take an alternative approach. Within the constraints imposed by the FEP and AIF, we attempt to model agents in an interpretable way without deep neural networks by introducing Free Energy Projective Simulation (FEPS). Using internal rewards only, FEPS agents build a representation of their partially observable environments with which they interact. Following AIF, the policy to achieve a given task is derived from this world model by minimizing the expected free energy. Leveraging the interpretability of the model, techniques are introduced to deal with long-term goals and reduce prediction errors caused by erroneous hidden state estimation. We test the FEPS model on two RL environments inspired from behavioral biology: a timed response task and a navigation task in a partially observable grid. Our results show that FEPS agents fully resolve the ambiguity of both environments by appropriately contextualizing their observations based on prediction accuracy only. In addition, they infer optimal policies flexibly for any target observation in the environment.