 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting upcoming visual features during eye movements yields scene representations aligned with human visual cortex
Nov 16, 2025

Scenes are complex, yet structured collections of parts, including objects and surfaces, that exhibit spatial and semantic relations to one another. An effective visual system therefore needs unified scene representations that relate scene parts to their location and their co-occurrence. We hypothesize that this structure can be learned self-supervised from natural experience by exploiting the temporal regularities of active vision: each fixation reveals a locally-detailed glimpse that is statistically related to the previous one via co-occurrence and saccade-conditioned spatial regularities. We instantiate this idea with Glimpse Prediction Networks (GPNs) -- recurrent models trained to predict the feature embedding of the next glimpse along human-like scanpaths over natural scenes. GPNs successfully learn co-occurrence structure and, when given relative saccade location vectors, show sensitivity to spatial arrangement. Furthermore, recurrent variants of GPNs were able to integrate information across glimpses into a unified scene representation. Notably, these scene representations align strongly with human fMRI responses during natural-scene viewing across mid/high-level visual cortex. Critically, GPNs outperform architecture- and dataset-matched controls trained with explicit semantic objectives, and match or exceed strong modern vision baselines, leaving little unique variance for those alternatives. These results establish next-glimpse prediction during active vision as a biologically plausible, self-supervised route to brain-aligned scene representations learned from natural visual experience.
Contextual Encoder-Decoder Network for Visual Saliency Prediction
Feb 18, 2019
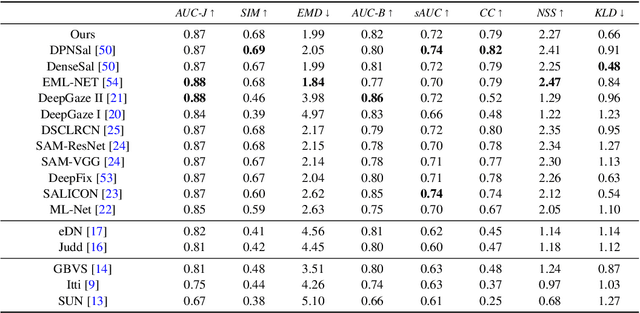
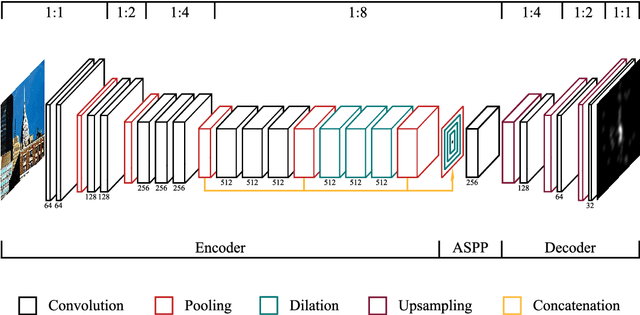
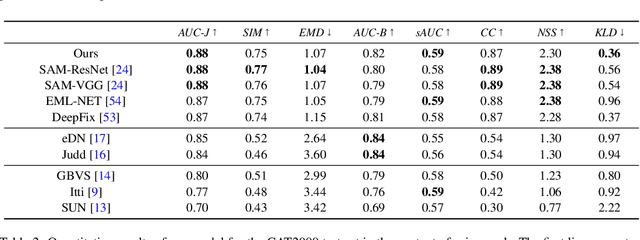
Predicting salient regions in natural images requires the detection of objects that are present in a scene. To develop robust representations for this challenging task, high-level visual features at multiple spatial scales must be extracted and augmented with contextual information. However, existing models aimed at explaining human fixation maps do not incorporate such a mechanism explicitly. Here we propose an approach based on a convolutional neural network pre-trained on a large-scale image classification task. The architecture forms an encoder-decoder structure and includes a module with multiple convolutional layers at different dilation rates to capture multi-scale features in parallel. Moreover, we combine the resulting representations with global scene information for accurately predicting visual saliency. Our model achieves competitive results on two public saliency benchmarks and we demonstrate the effectiveness of the suggested approach on selected examples. The network is based on a lightweight image classification backbone and hence presents a suitable choice for applications with limited computational resources to estimate human fixations across complex natural scenes.